
Go: Map Design by Example — Part I

ℹ️ This article is the first of a series of three articles. Each article will cover a different part of the map. I suggest you read them in order.
The built-in type map provided by Go implements a hash table. In this article, we will explore the implementation of the different parts of this hash table: the buckets (structure that stores the key/value pairs), the hashing (index of those pairs), and the load factor (metric that defines the capacity of the map should grow).
Buckets
Go stores the key/value pairs in a list of buckets where each bucket will hold 8 pairs, and when the map is running out of capacity, the number of hash buckets doubles. Here is a diagram of the rough representation of a map with 4 buckets:
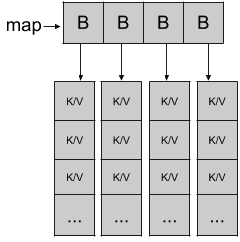
We will see in the next article how the key/value pairs in the bucket are stored. If the map grows again, the number of buckets will double to 8, then 16, and so on.
When a pair comes into the map, it will be dispatched to a bucket according to the hash calculated from the key.
Hashing
When a key/value pair is assigned to the map, Go will generate a hash based on this key.
Let’s take an example with the insertion of key/value pair "foo" = 1. The hash generated could be 15491954468309821754. This value will be applied to a bit operation with the mask corresponding to the number of buckets minus 1. In our example with 4 buckets, it will give a mask of 3 and the following operation:
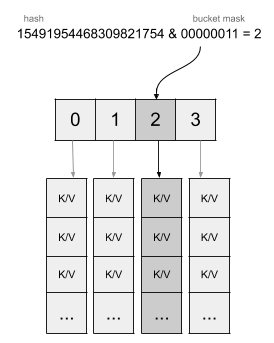
The hash is not only used to dispatch the value in the bucket. An extra operation will be applied on the hash. Each bucket uses the top byte of the hash and keeps it in an internal array that will allow Go to index the key and keep track of the empty slots in the bucket. Let’s have a look at an example with the binary representation of the hash:
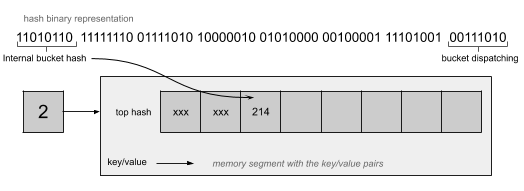
Thanks to this internal table in the bucket, called top hash, Go will be able to use them during data access and compare it with the hash of the requested key. According to the usage of the map in our programs, Go needs a way to grow the map to manage more key/values pairs.
Map growth
If a bucket receives a key/value pair to be stored, it will store it inside the 8 available slots in the bucket. If none of them are available, an overflow bucket will be created and linked to the current bucket:
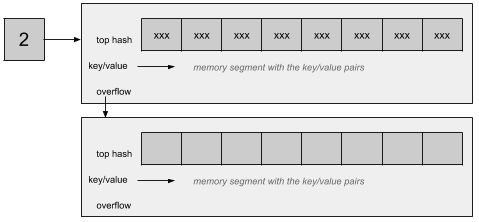
This overflow property concludes the internal structure of the bucket. However, adding overflow buckets will deteriorate the performance of the map. To remedy this, Go will allocate new buckets (double the current number), keep a link between the old buckets and the new ones, and will incrementally evacuate the buckets. Indeed, after this new allocation, each bucket involved in a writing operation will be evacuated if it has not been done already. All the key/value pairs of the bucket to be evacuated will be re-dispatched in the new buckets, which means pairs stored together previously in a similar bucket could now be dispatched in different buckets.
Go uses its load factor to know when it should start the allocation of the new buckets and this evacuation process.
Loading factor
Go has chosen a load factor of 6.5 for its map. You can find the study related to this load factor in the code:
// Picking loadFactor: too large and we have lots of overflow
// buckets, too small and we waste a lot of space. I wrote
// a simple program to check some stats for different loads:
// (64-bit, 8 byte keys and values)
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
//
// %overflow = percentage of buckets which have an overflow bucket
// bytes/entry = overhead bytes used per key/value pair
// hitprobe = # of entries to check when looking up a present key
// missprobe = # of entries to check when looking up an absent keyThe map will grow if the average number of values per bucket exceed 6.5. Since the distribution based on the hash of the key could not be evenly distributed, choosing a value close to 8 could result in a lot of overflow buckets, as we saw in the study.
⏭ The next article of this series, “Go: Map Design by Code”, will explain the internal implementation of the map.





