
Getting Started with Data Science — Instacart Dataset & Google BigQuery
In 2017 Instacart open-sourced 3 million grocery orders. To this date, it is still the largest real grocery sales dataset. We will use this very interesting dataset to hone our skills in Exploratory Data Analysis and try Google Cloud BigQuery Data Studio. It will be a fun and informative beginner friendly tutorial on data analysis. There are limitations to this data:
- The users are anonymized. There’s no demographics data — no gender, age. Instacart explained on its blog post that it’s too hard to protect privacy of users if such data is included. In real life, Instacart also does not collect such data, but does use code scripts to analyze and infer gender from usernames. We heard of a devtool, from a different developer in a different company, that figures out gender called genderize.io.
- There is no brand specific data. All of almond milk is classified as almond milk regardless of the brand.
- There’s is no explicit time or date data, but there is interval data. Some data that infers time and also indication of the sequence of purchasing by each user.
Despite its limitations, it is a huge dataset of granular purchasing data. We love it and we are grateful to Instacart for opening it to data scientists and developers.
Citation: “The Instacart Online Grocery Shopping Dataset 2017”, Accessed from https://www.instacart.com/datasets/grocery-shopping-2017 on April 2019. Instacart Note: the dataset is for non-commercial use only.
In Jeremy Stanley’s post, Curious about the food Americans eat? Look no further, he introduced the dataset, citation, term of use. He also pointed out that Americans are most likely order less healthy food choices like ice cream at night and late night. He also compared frequency of purchase of herbs, veggies and baking ingredients.
Motivation for engineers at Instacart — data like this is used to build new features and core product functionalities for Instacart customers such as “Buy It Again” and “Frequently Bought with XYZ (e.g. Hass Avocado)” — making relevant and sales driven recommendations for customers.
Our motivation for beginner tutorial — learn to analyze large datasets, getting started with small sample big data, trying out exploratory analysis, trying out analyzing large datasets on Google Cloud BigQuery.
Type of Data
The user data is completely anonymous. Purchase sequence data is available.
“…to protect the privacy of our users and retail partners and to ensure that the data is entirely anonymous… The only information provided about users is their sequence of orders and the products in those orders.” — 3 Million Instacart ORders, Open Sources — tech-at-instacart
Summary Statistics of Large Datasets are Interesting
When a dataset size is large enough, there’s a wealth of information, even if the actual data is anonymized and simplified.
There are 200,000 Instacart users (you can easily figure this out by querying user IDs and select unique), each with 4–100 orders (range of data) in a year! One hundred orders!! That is almost one order every three days. That’s a super user or in the gaming world — a whale. We got a sense that the number is truncated too! There are many users with 100 orders, which appears to be capped at 100. That number alone makes Instacart’s business potential very compelling.
There are 49688 products (number of rows in the product table). Wow. If you are applying for work at Instacart Engineer, you’d better brush up your big data skills. By the way, Instacart stack in 2017 include XGBoost, Word2Vec, Annoy.
There are 3 million orders, which is number large enough to slow down Excel and end up in bulky files, but for Google BigQuery, it’s actually a small appetizer size dataset. That’s why we will use it.
As explained in this section, even basic summary stats such as number of rows / length of table and range of data yields informative results.
In a later section, we will drive into the relative time interval and sequence of the purchase and each item purchased. That’s what Instacart Engineering finds interesting.
Loading 3 Million Instacart Data Records into BigQuery
It is easy to preview a few smaller .csv tables using Google Sheet but for the gorilla in the room — orders.csv, we will employ Google BigQuery SQL for Big Data in the Google Cloud.
Notes Google BigQuery charges both storage and querying fees, though the fee is relatively small and easy to budget. Any new account with billing setup can get a $300 trial credit, more than enough to do multiple tutorials. Be sure to set a budget to limit excessive spending.
One important pro tip is that the limit statement will not save your quota. All results are queried and returned and billed on , LIMIT only modifies the final view.
SELECT * FROM tablename
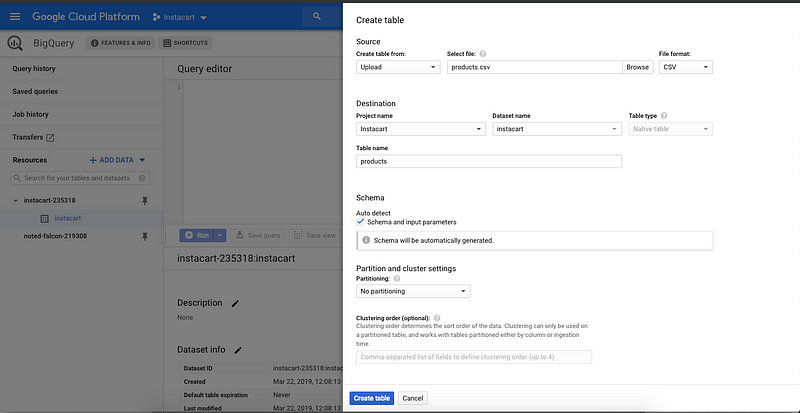
LIMIT 100A few csv files can be easily uploaded to BigQuery with a click of a button, but the larger files requires uploading to Google Cloud Storage first and access from there.
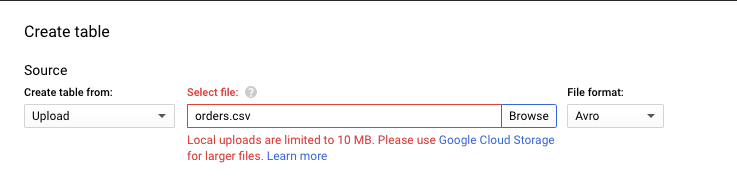
Loading a CSV File to Google BigQuery
As noted above any file larger than 10MB will need to be uploaded to Google Cloud Storage first. There’s a nominal usage and storage cost associated with GCS. Transaction data are usually lengthy, so generally it will need to go through GCS. You can use CSV to upload smaller metadata files like category.csv, time_of_week.csv (just examples not a part of Instacart dataset).
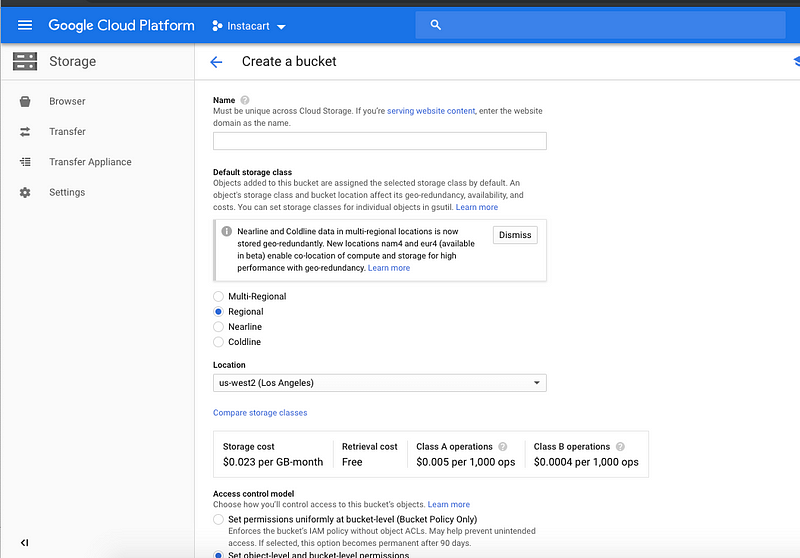
Uploading Large CSV to Google Cloud Storage
First you will have to create a bucket in the storage.
More Updates Coming Soon
This post is under construction please check back later. If you need this article urgently please comment below. Please clap if you like it!
Summary Statistics
For a dataset of this size and new (2017 is still relevant), summary statistics are simple yet powerful metrics
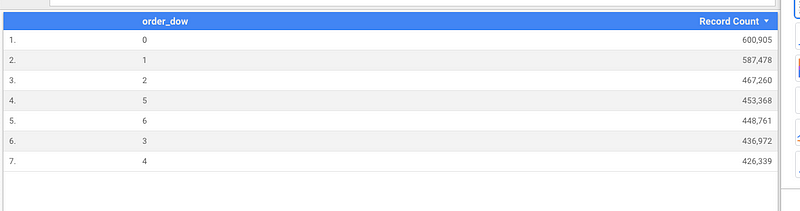
Number of orders vs Day of Week (DOW)
Building Features out of Customer Purchase Data
“Instacart currently uses XGBoost, word2vec, and Annoy in production on similar data to sort items for users to ‘buy again’”
“We hope the machine learning community will use this data to test models for predicting products that a user will buy again, try for the first time and add to cart next during a session.”
In Tech in Instacart’s own words, the feature that can be build from sequences of purchase data is the Buy Again recommendation features.