
Getting Started with Clustering: A Beginner’s Guide
Absolute Beginner’s Guide to Clustering
Clustering is a powerful data-driven technique to divide a dataset into distinct groups or clusters. Using clustering algorithms, data scientists can uncover patterns and insights from large and complex datasets. This guide is designed for absolute beginners and introduces the fundamentals of clustering. We will first discuss the basics of clustering and its various phases. Then we’ll look at the different types of clustering algorithms, such as K-Means, Hierarchical Clustering, Gaussian Mixture Models, and more. We’ll also cover the topics of data pre-processing, model evaluation, and big data clustering. By the end of this guide, you will understand the basics of clustering and have the tools needed to get started on your clustering projects.
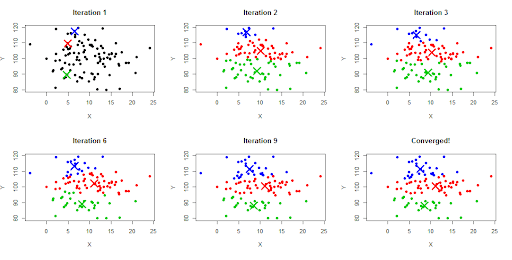
K-means
K-means is one of the simplest and most widely used clustering algorithms. It’s based on an iterative refinement process that alternates between assigning data points to clusters and updating the parameters of each cluster. K-means is a fast and reliable method for clustering data, although it’s not ideal for clustering non-spherical datasets. The algorithm assigns each data point to the cluster with the closest mean. As the mean of each cluster is updated, the data points are reassigned to their nearest clusters.
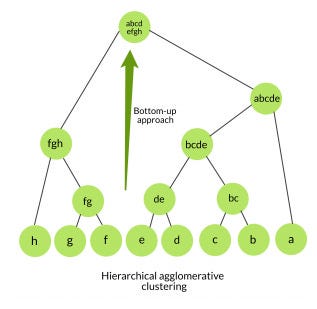
Hierarchical Clustering
Hierarchical clustering is another commonly used clustering algorithm. It involves grouping data objects into clusters with varying degrees of similarity. It starts by treating each data object as a single cluster and then iteratively combines or hierarchically divides clusters. Hierarchical clustering can be used to create a cluster tree or dendrogram, which shows the order in which the clusters are formed. It’s a powerful technique for analyzing data objects with a hierarchical structure.
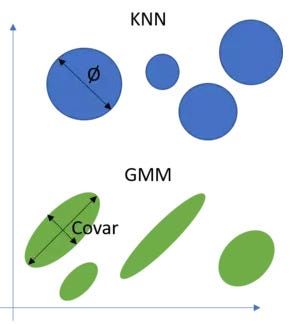
Gaussian Mixture Models
Gaussian mixture models (GMM) are clustering algorithm that uses probabilistic models to assign data points to clusters. GMM assumes that each cluster is a Gaussian distribution and that data points can be assigned based on the probability of belonging to that cluster. GMM is well suited for data with different shapes and sizes and datasets with overlapping clusters. It also allows for the inference of latent variables (data points that are not observed).
Model Evaluation
Once a model is built and tested, it’s essential to evaluate its performance. Various metrics are used to evaluate clustering models, and the most common ones are the Adjusted Rand Index, the Silhouette Coefficient, and the Calinski-Harabasz index. These indices provide information on the quality of the clusters and can be used to compare and optimize different clustering models.
Data Pre-Processing
To yield meaningful results, clustering algorithms require data to be divided into clusters that are distinct and separable. Data pre-processing is essential for clustering; it involves transforming the data into a representation better suited for clustering algorithms. This includes scaling data, normalizing data, and eliminating outliers. Data pre-processing can significantly improve the accuracy of clustering algorithms.
Big Data Clustering
Big data clustering poses unique challenges due to the sheer size of datasets. Traditional clustering algorithms may need to be faster or scale better with big datasets. The most common approach to clustering big data is to use distributed clustering algorithms. These algorithms break the dataset into smaller subsets and cluster each subset in parallel. Another method is to use approximation algorithms to speed up the clustering process.
Conclusion
Clustering is an essential data-driven tool for uncovering insights from large and complex datasets. This guide provided a comprehensive overview of clustering, including the most commonly used clustering algorithms, evaluation techniques, pre-processing data methods, and techniques for clustering big data. With this guide, you now have the tools to get started on your clustering projects.
For additional PMM and ML reading and resources (mixture of free and subscription services): Bits, Bytes, and Bots
For Education & Analytics reading and resources (mixture of free and subscription services): Education on Education



