
Getting Race Results from F1.com Using BeautifulSoup and Python
Racing Data Lab
In the world of motorsports, Formula 1 stands out as the pinnacle of racing technology and strategy. Fans, analysts, and enthusiasts often seek the latest race results and statistics to dissect every aspect of the racing weekend. Today, we’ll explore how you can use Python and a powerful library called BeautifulSoup to extract race results directly from F1.com for your analysis.
Please note that web scraping should be done responsibly and in compliance with the terms of service of the website. Always check F1.com’s robots.txt file and terms of service to ensure compliance.
The race results data available in the F1.com website for each Gran Prix of the F1 2023 season requires to build a specific url.
For example if we want to get the race results from the 2023 Brazil GP, we need to extract the information from the following url:
https://www.formula1.com/en/results.html/2023/races/1224/brazil/race-result.html
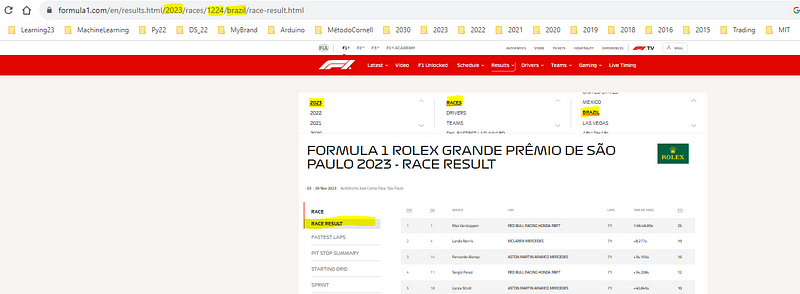
As you can see, to identify a specific Grand Prix we need to know the race id and the race name, for Brazil we have the following data:
- race_id = 1224
- race_name = brazil

If you want to obtain the information from other Grand Prix, we can use the following values to build the required url:
'race_id':1141, 'race_name': 'bahrain'
'race_id':1142, 'race_name': 'saudi-arabia'
'race_id':1143, 'race_name': 'australia'
'race_id':1207, 'race_name': 'azerbaijan'
'race_id':1208, 'race_name': 'miami'
'race_id':1209, 'race_name': 'italy'
'race_id':1210, 'race_name': 'monaco'
'race_id':1211, 'race_name': 'spain'
'race_id':1212, 'race_name': 'canada'
'race_id':1213, 'race_name': 'austria'
'race_id':1214, 'race_name': 'great-britain'
'race_id':1215, 'race_name': 'hungary'
'race_id':1216, 'race_name': 'belgium'
'race_id':1217, 'race_name': 'netherlands'
'race_id':1218, 'race_name': 'italy'
'race_id':1219, 'race_name': 'singapore'
'race_id':1220, 'race_name': 'japan'
'race_id':1221, 'race_name': 'qatar'
'race_id':1222, 'race_name': 'united-states'
'race_id':1223, 'race_name': 'mexico'
'race_id':1224, 'race_name': 'brazil'
'race_id':1225, 'race_name': 'las-vegas'
'race_id':1226, 'race_name': 'abu-dhabi'Google Colab Notebook
Python Code
import bs4 as bs
import urllib.request
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from functools import wraps
from bs4 import BeautifulSoup
year = 2023
url_all_races = 'https://www.formula1.com/en/results.html/'+ str(year) +'/races/'
#Races Catalog
r0 = {'race_id':1141, 'race_name': 'bahrain'}
r1 = {'race_id':1142, 'race_name': 'saudi-arabia'}
r2 = {'race_id':1143, 'race_name': 'australia'}
r3 = {'race_id':1207, 'race_name': 'azerbaijan'}
r4 = {'race_id':1208, 'race_name': 'miami'}
r5 = {'race_id':1209, 'race_name': 'italy'}
r6 = {'race_id':1210, 'race_name': 'monaco'}
r7 = {'race_id':1211, 'race_name': 'spain'}
r8 = {'race_id':1212, 'race_name': 'canada'}
r9 = {'race_id':1213, 'race_name': 'austria'}
r10 = {'race_id':1214, 'race_name': 'great-britain'}
r11 = {'race_id':1215, 'race_name': 'hungary'}
r12 = {'race_id':1216, 'race_name': 'belgium'}
r13 = {'race_id':1217, 'race_name': 'netherlands'}
r14 = {'race_id':1218, 'race_name': 'italy'}
r15 = {'race_id':1219, 'race_name': 'singapore'}
r16 = {'race_id':1220, 'race_name': 'japan'}
r17 = {'race_id':1221, 'race_name': 'qatar'}
r18 = {'race_id':1222, 'race_name': 'united-states'}
r19 = {'race_id':1223, 'race_name': 'mexico'}
r20 = {'race_id':1224, 'race_name': 'brazil'}
r21 = {'race_id':1225, 'race_name': 'las-vegas'}
r22 = {'race_id':1226, 'race_name': 'abu-dhabi'}
catalog_race = { 0:r0, 1:r1, 2:r2, 3:r3, 4:r4, 5:r5, 6:r6, 7:r7, 8:r8, 9:r9, 10:r10, 11:r11, 12:r12, 13:r13, 14:r14, 15:r15, 16:r16, 17:r17, 18:r18, 19:r19, 20:r20, 21:r21, 22:r22}
event = 'race-result.html'
column01 = []
column02 = []
for x, y in catalog_race.items():
final_url = url_all_races + str(catalog_race[x]['race_id']) + '/' + catalog_race[x]['race_name'] + '/' + event
column01.append(final_url)
column02.append(catalog_race[x]['race_name'])
data_tuples = list(zip(column01, column02))
f1_url_df = pd.DataFrame(data_tuples, columns=['f1_url','race_name'])
f1_url_df
'''
race_index values:
0 = 'bahrain'
1 = 'saudi-arabia'
2 = 'australia'
3 = 'azerbaijan'
4 = 'miami'
5 = 'italy'
6 = 'monaco'
7 = 'spain'
8 = 'canada'
9 = 'austria'
10 = 'great-britain'
11 = 'hungary'
12 = 'belgium'
13 = 'netherlands'
14 = 'italy'
15 = 'singapore'
16 = 'japan'
17 = 'qatar'
18 = 'united-states'
19 = 'mexico'
20 = 'brazil'
21 = 'las-vegas'
22 = 'abu-dhabi'
'''
#Selecting Brazil 2023 GP
race_index = 20
f1_url_df._get_value(race_index, 'f1_url')
f1_url_df._get_value(race_index, 'race_name')
"""
Let's look at a single race result from the season
"""
source = urllib.request.urlopen(f1_url_df._get_value(race_index, 'f1_url')).read()
soup = BeautifulSoup(source,'lxml')
table = soup.find_all('table')[0]
df_race = pd.read_html(str(table), flavor='bs4', header=[0])[0]
df_race.insert(0, 'Race', f1_url_df._get_value(race_index, 'race_name'))
# Drop html empty labels
df_race = df_race.drop(['Unnamed: 0','Unnamed: 8'], axis=1)
# Give a style to the table
df_race.style.background_gradient(axis=0, gmap=df_race['PTS'], cmap="YlOrRd")This Python code is designed to scrape Formula 1 race results for a specific year from the official Formula 1 website and then process and display the data in a structured format using Pandas DataFrames. Let’s break down the code step by step:
Libraries Import
The code begins by importing necessary Python libraries:
bs4for BeautifulSoup, used to parse HTML and XML documents.urllib.requestfor opening and reading URLs.pandasaspdfor data manipulation and analysis.numpyasnp(though not directly used in the snippet provided).matplotlib.pyplotandseabornfor data visualization (though not directly used in the snippet provided).functools.wraps(imported but not used in the snippet provided).
Setting Up the Variables
year: This variable holds the year for which the race results are to be scraped.url_all_races: This is the base URL for the results page, to which the year and other parameters will be appended to access specific race results.- A catalog of races is created, where each race is represented by a dictionary with
race_idandrace_name.
Building URLs for Each Race
- The code iterates over the
catalog_racedictionary to construct the final URL for each race's result page by appending therace_id,race_name, andevent(which is set to 'race-result.html') to theurl_all_races. - These URLs (
column01) and race names (column02) are then zipped together intodata_tuplesand converted into a DataFramef1_url_dfwith columnsf1_urlandrace_name.
Selecting a Specific Race
- A
race_indexis set to 20, which corresponds to the Brazilian GP in the given dictionary. - The code then uses
_get_valuemethod from Pandas to retrieve the URL and race name for the Brazilian GP.
Scraping the Race Results
urllib.request.urlopenis used to open and read the content from the race result URL for the selected race.BeautifulSoupparses the HTML content retrieved from the page.- It finds the first table element in the parsed HTML, which is assumed to contain the race results.
Processing the Race Results into a DataFrame
pd.read_htmlreads the HTML table into a DataFrame. Theheader=[0]argument is used to specify that the first row of the table contains the column headers.- A new column ‘Race’ is inserted into the DataFrame to indicate the race name for each result.
- It drops any unnamed columns that do not contain any useful information.
- The DataFrame is styled to include a background gradient based on the points (
'PTS') column usingcmap="YlOrRd"which creates a color gradient from Yellow to Orange to Red.
Notes
- The
_get_valuemethod used in the code is generally not recommended for typical use; it's a low-level method intended for efficient value retrieval and is not guaranteed to be stable across versions of Pandas. - The use of web scraping techniques should be in compliance with the website’s terms of service and the legality of scraping in the applicable jurisdiction. It’s always important to review the
robots.txtfile of a website to understand what the site's owners allow to be crawled. - The script does not handle exceptions that may occur during the web requests or parsing stages, which would be important for robustness in a production environment
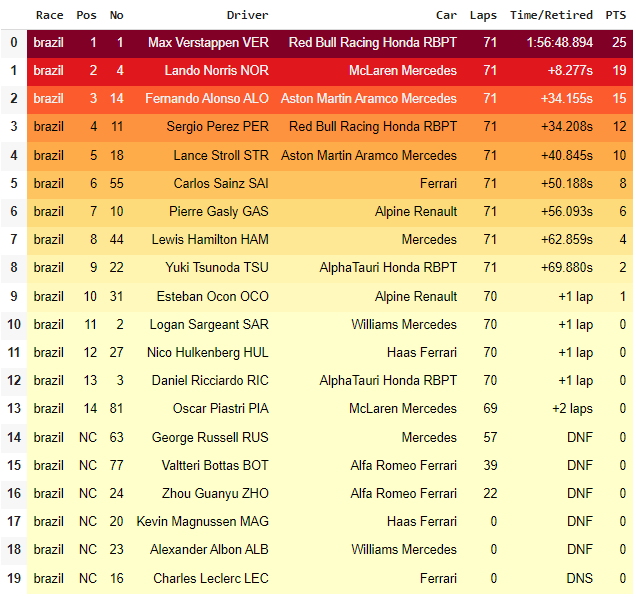
Result:
You can compare the results of the python script vs the official F1 website.

Thanks for getting to this point, if you have an specific doubt or if you want to perform a specific analysis please free to contact me.
For more information, please visit RacingDataLab Website:
Disclaimer:
- This article is unofficial and is not associated in any way with the Formula 1 companies. F1, FORMULA ONE, FORMULA 1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trade marks of Formula One Licensing B.V.
- The comments expressed on this article and in the analyzes are personal and do not represent the position of any company.
- This article is for a Fan use, dedicated to the FIA FORMULA ONE WORLD CHAMPIONSHIP, to report on and provide information about the FORMULA 1 events.
Credits:
FIA.com | the official website of the Federation Internationale de l’Automobile. | https://www.fia.com/
Formula1.com | the official website of the F1. | https://www.formula1.com/
RedBullContentPull.com | Editorial Use / Getty Images / Red Bull Content Pool | https://www.redbullcontentpool.com/
In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us: Twitter(X), LinkedIn, YouTube, Discord.
- Check out our other platforms: Stackademic, CoFeed, Venture.




