
Generative AI on Research Papers Using Nougat Model
Doing cool things with Data!

Introduction
Recent advances in large language models (LLMs) like GPT-4 have shown impressive capabilities in generating coherent text. However, parsing and understanding research papers accurately remains an extremely challenging task for AI. Research papers contain complex formatting, math equations, tables, figures, and domain-specific language. The density of information is very high and important semantics are encoded in the formatting.
In this article, I will demonstrate how a new model called Nougat from Meta can help parse research papers accurately. We then combine it with an LLM pipeline that extracts and summarizes all the tables in the paper.
The potential here is immense. There is a lot of data/information locked up in research papers and books that have not been parsed correctly. Accurate parsing enables their use in many different applications including LLM retraining.
I made a Youtube video explaining the code and my experiments in more detail. Check it out here.
Nougat Model
Nougat is a visual transformer model developed by researchers at Meta AI that can convert images of document pages into structured text [1]. It takes a rasterized image of a document page as input and outputs text in a lightweight markup language.
The key advantage of Nougat is that it relies solely on the document image and does not need any OCR text. This allows it to recover semantic structure like math equations properly. It is trained on millions of academic papers from arXiv and PubMed to learn the patterns of research paper formatting and language.
The figure below from [1] shows how math equations written in PDF are reproduced in Latex and rendered correctly.

Nougat uses a visual transformer encoder-decoder architecture. The encoder uses a Swin Transformer to encode the document image into latent embeddings. The Swin Transformer processes the image in a hierarchical fashion using shifted windows. The decoder then generates the output text tokens autoregressively using self-attention over the encoder outputs.
Nougat is trained end-to-end on page image and text pairs using stochastic gradient descent. Data augmentation like erosions, dilations, and elastic transforms are used to improve robustness. A special anti-repetition regularization is also used during training to reduce text repetitions.
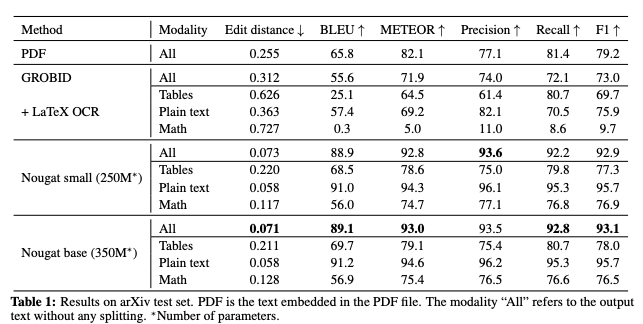
The authors report metrics like edit distance, BLEU, METEOR, and F1-score on a test set of academic papers. Nougat achieves high accuracy, especially for plain text. The errors are mostly in math expressions because of ambiguity in LaTeX commands. As shown below, Nougat outperforms prior approaches like GROBID and PDF OCR by a significant margin.
Running and Evaluating the output from the Nougat Model
The installation instructions and the steps to run the Nougat Model are shared in the Colab Notebook here.
The Nougat small model runs easily on a free Colab T4 GPU and has very impressive results.
The main steps to running the model are installing the package nougat-ocr. And then we use the subprocess to run a command line CLI to pass the downloaded PDF to Nougat and get its outputs.
!pip install -qq nougat-ocr
def nougat_ocr(file_name):
# Command to run
cli_command = [
'nougat',
'--out', 'output',
'pdf', file_name,
'--checkpoint', CHECKPOINT,
'--markdown'
]
# Run the command
subprocess.run(cli_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
returnIn my Colab Notebook, I ran Nougat on the DOLA paper. Nougat impressively captures the math equations in Latex.
Recent language models are consists of an embedding layer, \(N\) stacked transformer layers, and an affine layer \(\phi(\cdot)\) for predicting the next-word distributution. Given a sequence of tokens \(\{x_{1},x_{2},\ldots,x_{t-1}\}\), the embedding layer first embeds the tokens into a sequence of vectors \(H_{0}=\{h_{1}^{(0)},\ldots,h_{t-1}^{(0)}\}\). Then \(H_{0}\) would be processed by each of the transformer layers successively. We denote the output of the \(j\)-th layer as \(H_{j}\). Then, the vocabulary head \(\phi(\cdot)\) predicts the probability of the next token \(x_{t}\)
\[p(x_{t}\mid x_{<t})=\mathrm{softmax}\big{(}\phi(h_{t}^{N})\big{)}_{x_{t}}, \quad x_{t}\in\mathcal{X},\]
where \(\mathcal{X}\) is the vocabulary set.
Instead of applying \(\phi\) just on the final layer, our approach contrasts the higher-layer and lower-layer information to obtain the probability of next token. More specifically, for the lower layers, we also compute the probability of the next tokens using \(\phi(\cdot)\),
\[q_{j}(x_{t}\mid x_{<t})=\mathrm{softmax}\big{(}\phi(h_{t}^{j})\big{)}_{x_{t}}, \quad j=1,\ldots,N.\]
The idea of applying language heads directly to the hidden states of the middle layers, known as _early exit_(Teerapittayanon et al., 2016; Elbayad et al., 2020; Schuster et al., 2022), has proven to be an effective inference method even without special training process (Kao et al., 2020), as the residual connections (He et al., 2016) in transformer layers make the hidden representations gradually evolve without abrupt changes. Using \(q_{j}(x_{t})\) to represent \(q_{j}(x_{t}\mid x_{<t})\) for notational brevity, we then compute the probability of the next token by,
\[\hat{p}(x_{t}\mid x_{<t}) =\mathrm{softmax}\big{(}\mathcal{F}\big{(}q_{N}(x_{t}),q_{M}(x_{t })\big{)}\big{)}_{x_{t}}, \tag{1}\] \[\text{where}\quad M =\operatorname*{arg\,max}_{j\in\mathcal{J}}\;d\big{(}q_{N}(\cdot ),q_{j}(\cdot)\big{)}.\]
Here, layer \(M\) is referred to as the _premature layer_, while the final layer is referred to as the _mature layer_. The operator \(\mathcal{F}(\cdot,\cdot)\), to be elaborated further in Section 2.3, is used to contrast between the output distributions from the premature layer and the mature layer by computing the difference between two distributions in the log domain. The premature layer is dynamically selected in each decoding step using a distributional distance measure \(d(\cdot,\cdot)\) (we use the Jensen-Shannon Divergence) between the mature layer and all the candidate layers in \(\mathcal{J}\). We discuss \(d(\cdot,\cdot)\) in more detail in Section 2.1 and Section 2.2. The motivation for selecting the layer with the highest distance \(d(\cdot,\cdot)\) as the premature layer is to maximize the difference between the mature/premature layers.I also found tables were captured well in Latex. Table 1 is converted accurately to Latex below!
\begin{table}
\begin{tabular}{l c c c c c} \hline \hline \multirow{2}{*}{**Model**} & \multicolumn{4}{c}{**TruthfulQA**} & \multicolumn{2}{c}{**FACTOR**} \\ \cline{2-6} & **MC1** & **MC2** & **MC3** & **News** & **Wiki** \\ \hline LLaMa-7B & 25.6 & 40.6 & 19.2 & 58.3 & 58.6 \\ + ITI (Li et al., 2023) & 25.9 & - & - & - & - \\ + DoLa & **32.2** & **63.8** & **32.1** & **62.0** & **62.2** \\ \hline LLaMa-13B & 28.3 & 43.3 & 20.8 & 61.1 & 62.6 \\ + CD (Li et al., 2022) & 24.4 & 41.0 & 19.0 & 62.3 & 64.4 \\ + DoLa & **28.9** & **64.9** & **34.8** & **62.5** & **66.2** \\ \hline LLaMa-33B & 31.7 & 49.5 & 24.2 & 63.8 & 69.5 \\ + CD (Li et al., 2022) & **33.0** & 51.8 & 25.7 & 63.3 & **71.3** \\ + DoLa & 30.5 & **62.3** & **34.0** & **65.4** & 70.3 \\ \hline LLaMa-65B & 30.8 & 46.9 & 22.7 & 63.6 & 72.2 \\ + CD (Li et al., 2022) & 29.3 & 47.0 & 21.5 & 64.6 & 71.3 \\ + DoLa & **31.1** & **64.6** & **34.3** & **66.2** & **72.4** \\ \hline \hline \end{tabular}
\end{table}
Table 1: Multiple choices results on the TruthfulQA and FACTOR.Generative LLM to summarize Latex Tables
There are many examples of LLMs summarizing text including research papers. But almost always, the data in tables and math equations is neither parsed correctly nor included in the summary. I now test, how well models like GPT3.5 do on Latex tables.
I have used Langchain to write a chain pipeline here that does the following:
- Identifies all tables in the research paper
- Reads the Latex and understands the table
- Creates an output dictionary summarizing each table
The full source code is included in the Colab Notebook here. As shown in the code snippet below, our prompt to LLM is to identify all tables, summarize them, and share the results in a structured format.
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
context_template="You are a helpful AI Researcher that specializes in analysing research paper outputs presented to you in Latex"
system_message_prompt = SystemMessagePromptTemplate.from_template(context_template)
human_template= """
Please extract all tables referenced in this paper. The tables are in Latex format. Summarize the tables one by one.
Each summary should be 4-5 sentences long. Include numbers in summary where you can. Make a dictionary with table number, table name and summary of that table.
PAPER: {paper_content}
"""
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template=human_template,
input_variables=["paper_content"],))
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt,
human_message_prompt])
chat = ChatOpenAI(model_name="gpt-3.5-turbo-16k",
temperature=0.2)
summary_chain = LLMChain(llm=chat, prompt=chat_prompt_template)
output = summary_chain.run(noref_content)
pprint.pprint(output)I wasn’t very sure how the LLM would do, so I have to say I was stunned by the quality of the response. There are 6 tables in the paper and all of them were identified correctly. Then each was summarized well.
The response from LLM to the above prompt is below.
('Dictionary of Tables:\n'
'\n'
'Table 1:\n'
'- Table Number: 1\n'
'- Table Name: Multiple choices results on the TruthfulQA and FACTOR '
'datasets\n'
'- Summary: This table presents the results of multiple choice tasks on the '
'TruthfulQA and FACTOR datasets. It compares the performance of different '
'models, including the baseline, Inference Time Intervention (ITI), and DoLa. '
'The table shows that DoLa consistently outperforms the other methods, '
'improving the truthfulness and informativeness scores.\n'
'\n'
'Table 2:\n'
'- Table Number: 2\n'
'- Table Name: Open-ended generation results on TruthfulQA, StrategyQA, and '
'GSM8K\n'
'- Summary: This table summarizes the results of open-ended generation tasks '
'on the TruthfulQA, StrategyQA, and GSM8K datasets. It compares the '
'performance of different models, including the baseline, Contrastive '
'Decoding (CD), and DoLa. The table shows that DoLa consistently enhances the '
'truthfulness and informativeness scores, outperforming the other methods.\n'
'\n'
'Table 3:\n'
'- Table Number: 3\n'
'- Table Name: Multiple choices results on the FACTOR dataset\n'
'- Summary: This table presents the results of multiple choice tasks on the '
'FACTOR dataset. It compares the performance of different models, including '
'the baseline, DoLa with dynamic premature layer selection, and DoLa with '
'random layer selection. The table shows that DoLa with dynamic premature '
'layer selection performs better than the other methods, improving the '
'truthfulness and informativeness scores.\n'
'\n'
'Table 4:\n'
'- Table Number: 4\n'
'- Table Name: Comparison of MPT-7B and modifications on TruthfulQA, FACTOR, '
'and CoT datasets\n'
'- Summary: This table compares the performance of the MPT-7B model and its '
'modifications on the TruthfulQA, FACTOR, and CoT datasets. It shows that '
'DoLa improves the truthfulness and truthfulness+informativeness scores on '
'most datasets, indicating the potential of DoLa to generalize across '
'different transformer models.\n'
'\n'
'Table 5:\n'
'- Table Number: 5\n'
'- Table Name: Qualitative study for LLaMA-33B on TruthfulQA\n'
'- Summary: This table presents qualitative examples from the TruthfulQA '
'dataset, comparing the answers generated by the baseline and DoLa using the '
'LLaMA-33B model. It shows that DoLa produces more truthful and informative '
'answers compared to the baseline.\n'
'\n'
'Table 6:\n'
'- Table Number: 6\n'
'- Table Name: Averaged decoding latency per token in milliseconds\n'
'- Summary: This table shows the average decoding latency per token in '
'milliseconds for the baseline and DoLa. It indicates that DoLa adds a small '
'additional latency to the decoding process, making it a practical and '
'efficient decoding strategy.')Reading through these examples, my observations were:
- Each table was identified. The model accurately understands the rows and columns of the table
- The summary captures the conclusion from the table
- The summary suggests the model used information from the paper to understand the table. For Table 3, the model accurately understood that the table compares DOLA with random layer selection vs. premature layer selection, even though the table itself doesn’t mention it
- I would have loved to see more numbers and stats in the summary of the table but the model did not output them. As a side note, I also tested Claude2 from Anthropic.AI and it was able to summarize the table with a mention of the key statistical conclusions, presenting a superior response
My code also covers an example of the above pipeline now searching for all math equations and explaining them. Impressive first results, there too.
Conclusion
In this article, I demonstrated how the Nougat model can parse complex research papers directly from images. Nougat overcomes a key challenge — understanding the semantics encoded in the formatting of papers.
I showed an end-to-end pipeline to parse a paper with Nougat, extract tables, and summarize them using LLMs. Nougat extracted the text, math, tables, and formatting with high accuracy. The downstream LLM successfully summarized an extracted table, focusing on key comparisons.
Nougat helps overcome the limitations of PDF text and current best solutions like pyPDF and GROBID. We can now understand the information in papers much better. Overall this demonstrates how generative AI models are making strides in unlocking all the knowledge trapped in unstructured formats.
I run my own Machine learning consulting, helping clients with Generative AI applications. Email me at [email protected] if you are interested in collaborating together.
References
[1] Blecher, Lukas, et al. “Nougat: Neural Optical Understanding for Academic Documents.” arXiv preprint arXiv:2308.13418 (2023).
[2] Langchain Source Documentation — https://python.langchain.com/docs/get_started/introduction





