
Generating music using images
with Hugging Face’s new diffusers package
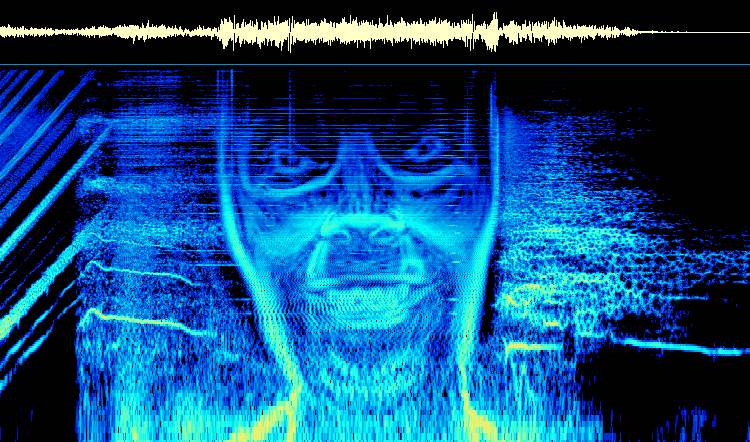
[UPDATE: I’ve also trained the model on 30,000 samples that have been used in music, sourced from WhoSampled and YouTube. The idea is that the model could be used to generate loops or “breaks” that can be sampled to make new tracks. People (“crate diggers”) go to a lot of lengths or are willing to pay a lot of money to find breaks in old records.]
I have been astonished by the recent improvements in Deep Learning models in the domains of image generation (DALL-E 2, MidJourney, Imagen, Make-A-Scene, etc.) and text generation (GPT-3, BLOOM, BART, T5, etc.) but, at the same time, surprised by the relative lack of progress with audio generation. Two notable exceptions come to mind: MuseNet treats sheet music as sequential tokens (similar to text) and leverages GPT-2, while Jukebox and WaveNet generate music from raw wave forms. Even so, is audio generation a laggard because there is less interest in it, or because it is intrinsically more challenging?
Whatever the case, audio can easily be converted to an image and vice versa, by way of a mel spectrogram.

The horizontal axis of the spectrogram is time, the vertical axis is frequency (on a log scale) and the shade represents amplitude (also on a log scale). The mel spectrogram is supposed to correspond closely to how the human ear perceives sound.
If we can now easily generate convincing looking photos of celebrities using AI, why not try to generate plausible spectrograms and convert them into audio? This is exactly what I have done using the new Hugging Face diffuserspackage.
TL;DR
So, how well does it work? Check out some automatically generated loops:
You can also generate more for yourself on Google Colab
You can choose between a model trained on almost 500 tracks (around 20,000 spectrograms) from my Spotify “liked” playlist or one trained on 30,000 samples that have been used in music.
Tell me more…
In the above repo, you will find utilities to create a dataset of spectrogram images from a directory of audio files, train a model to generate similar spectrograms and convert the generated spectrograms into audio. You will also find notebooks that allow you to play around with the pre-trained model.
If you are interested in the details of the model, then I recommend you read the Denoising Diffusion Probabilistic Models paper. According to Open AI, diffusion models beat GANs at their own game. The basic idea is that a model is trained to recover images from a version that has been corrupted by gaussian noise. If the model is trained with photos of celebrities, for example, it will come to learn what typical (or maybe not so typical!) facial features look like. To generate a random face of a celebrity, the model is given a completely random image and, each time it is run, the output image is slightly less noisy than before and looks a little more like a face (or a spectrogram in our case).
For simplicity, I chose to create square spectrogram images of 256 x 256 pixels, which correspond to five seconds of reasonable quality audio. I used Hugging Face’s accelerate package to split the batches into shards that would fit on my single RTX 2080 Ti GPU. The training took about 40 hours.
Bear in mind that my Spotify playlist is a bit of a mix of different styles of music. I felt it was important to use a training dataset that I knew intimately, so that I would be able to judge how much the model was creating and how much it was just regurgitating (as well as there being a good chance I might actually like the results). In the same way that the celebrities dataset is relatively homogenous, it would be interesting to train the model with piano only music, or just techno music, for example, to see whether it is able to learn anything about a particular genre.
What’s next?
Music changed forever with the advent of samplers. At first they were controversial (A Tribe Called Quest had to pay all the proceeds from “Can I Kick It?” to Lou Reed for the sample of “Walk on the Wild Side”) but then they were embraced by almost every genre. Finding a new hook to sample can be big business, so why not use AI to create new ones? What I would love to see is the equivalent of DALL-E 2 and company, but for prompt driven audio generation…



