
Generate Text2Human via Hugging Face 🤗
Human Image Generation using Text
This python library Text2Human generates a person’s image by only providing a textual description about the gender and cloths.
Project Specifications
Raw data DeepFashion-MultiModal Pre-processed dataset Pre-trained models Try out web Demo
Raw Dataset
DeepFashion-MultiModal, a large-scale high-quality human dataset with rich multi-modal annotations. It has the following properties:
- There are 44,096 high-resolution human photos in all, with 12,701 full-body images.
- We manually mark the human parser labels of 24 classes for each complete body picture.
- We carefully annotate the key-points on each complete body image.
- For each human picture, we extract DensePose.
- Each image is manually tagged with clothing shape and texture attributes.
- For each photograph, we include a textual description.
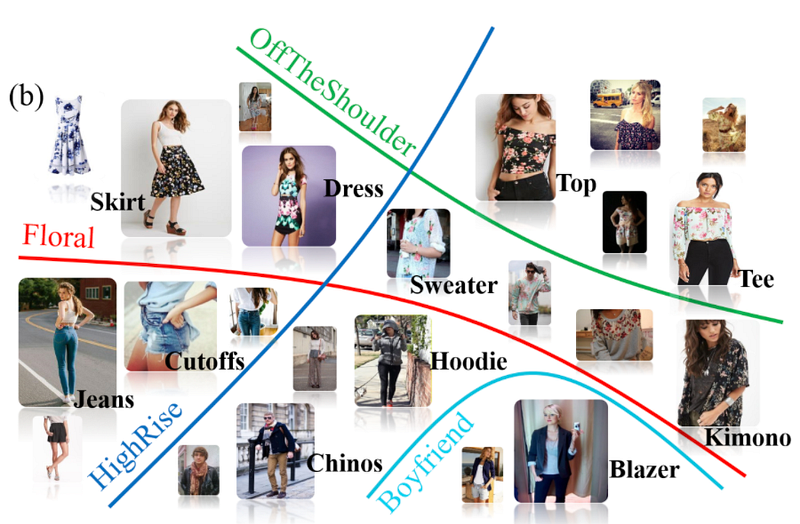
Dataset pre-processing
The following components make up the pre-processing pipeline:
- Align the human body in the image’s center based on the human pose
- Combine the clothes color and fabric annotations into a single texture annotation
- Tidy up the annotations, and apply some image filtering
- Divide the entire dataset into two groups: training and testing.

{kind=link}
Model Training
During model training, started with training the parsing generation network. Then, training the top level of the hierarchical VQ-VAE. (VQ-VAE is Vector Quantized Variational Autoencoder. VQ-VAE was proposed in Neural Discrete Representation Learning)
Further, training the sampler with mixture-of-experts. To train the sampler, started with training a model to tokenize the parsing maps. And finally, training the index prediction network.
Results
You can install the same using the github https://github.com/sameer-goel/Text2Human and run UI demo.
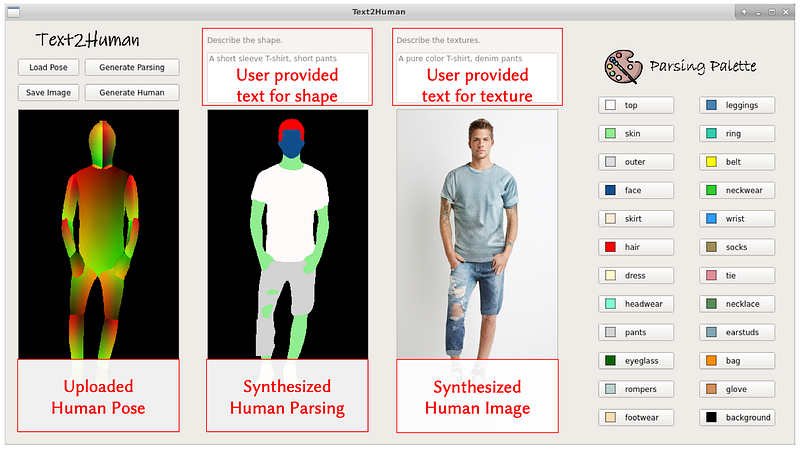
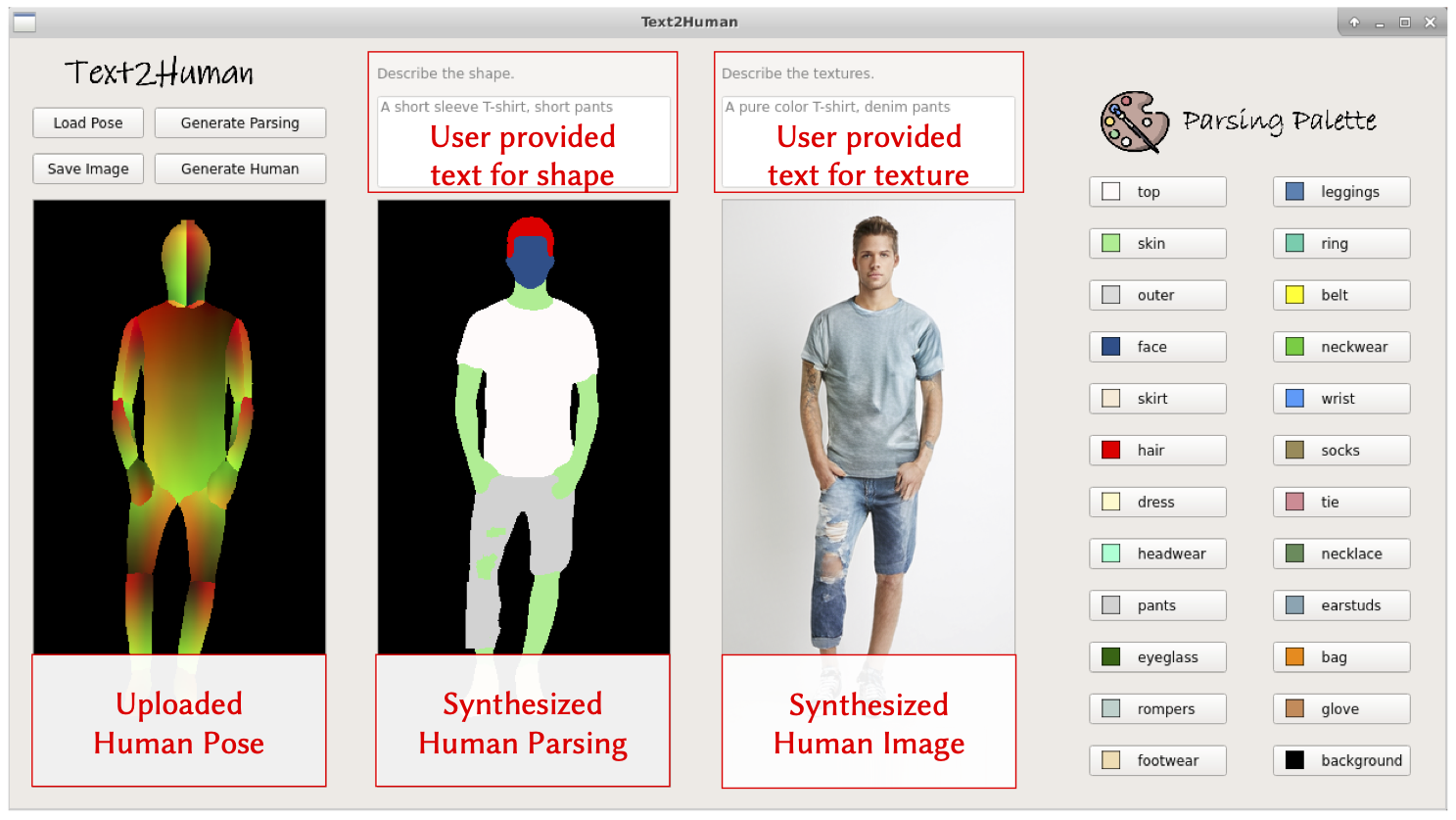{kind=link}
You can select the attributes to customize the desired human images.

{kind=link}
Kudos to Yuming Jiang, Shuai Yang, Haonan Qiu, Wayne Wu, Chen Change Loy and Ziwei Liu from MMLab@NTU affliated with S-Lab, Nanyang Technological University and SenseTime Research.
More Results
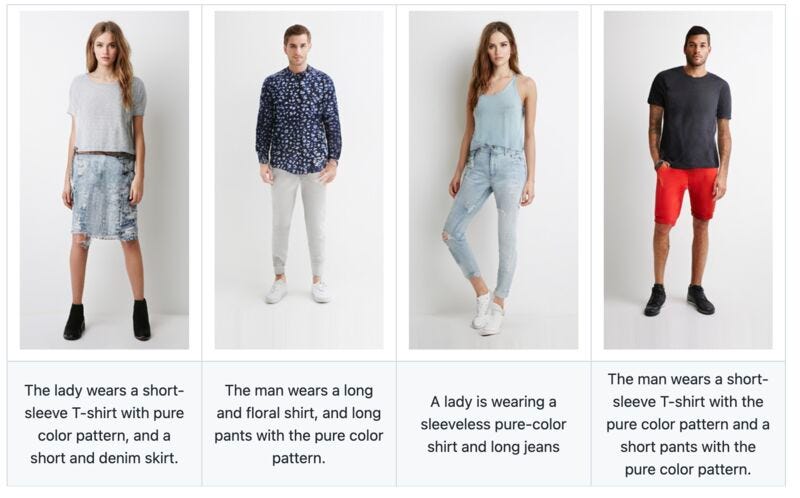
Here are some more synthetic images generated from this project.

I must say, the results were quite interesting.