
Gemma with Ollama — small and private LLM
Run Google’s latest LLM with Ollama offline

To enable the Gemma model, upgrade the ollama version to >0.1.26, by running the installation of ollama.
The quality of the Gemma models (2bn and 7bn), due to their size, will depends heavily on the training data. From the kaggle reference we can read that they were trained on 6 trillion tokens constituted of:
- Web Documents: A diverse collection of web text ensures the model is exposed to a broad range of linguistic styles, topics, and vocabulary. Primarily English-language content.
- Code: Exposing the model to code helps it to learn the syntax and patterns of programming languages, which improves its ability to generate code or understand code-related questions.
- Mathematics: Training on mathematical text helps the model learn logical reasoning, symbolic representation, and to address mathematical queries.
Use case of information retrieval
As ollama provides a convenient framework for running LLMs on local computational resources. One use case for private LLM are for document question-answering:
In order to use the Gemma 7bn model for this task, the instruct version of the model has to be downloaded, in this case from ollama:
ollama run gemma
Other version of the model can be downloaded from the tag list of Gemma.
In a comparison with Mixtral for this task, the limitations of the model become visible. This off course is due to the unfair comparison of the 70bn to 7bn model. Interestingly, tho when the Gemma 7bn model was used to retrieve information from a document, it could still perform simpler search tasks (retrieve pieces of information like values or dates), but failed to summarize sections from a document, where it simply stated that the document does not contain the requested information.
Limitation and intended use case
The behavior of Gamma on the document information retrieval highlight the limitations:
- context understanding due to the training data used
- requires more context in the prompts to combat task complexity
- factual correctness can be problematic
The ideal use case for this model is in text generation, chat. Text summarization can still be hindered by the listed limitations.
How Gemma 7bn compares to other LLMs in its weight category
Models such as the larger Mixtral (MoE of 8x mistral 7bn models) perform really good for this task. In case, however, when the computational resources are not that shabby, a single 7bn parameter model might also be a good choice. According to some test, the 7bn Gemma model outperforms other models, especially in mathematical reasoning — it can be very handy model to summarize papers or scientific content.
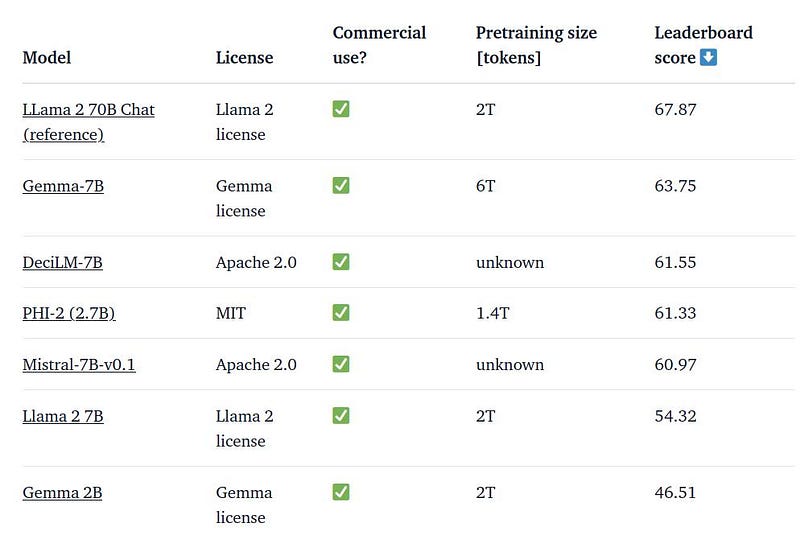
Conclusion
Gemma models are geared toward use cases that can don’t need all the knowledge an LLM can carry. It focuses on uses that would run LLM on somewhat restrained cases, whether to batch process a lot of request, or to have a decent LLM running on local machines, laptops, small servers, as it’s architecture offers faster inference speeds and lower computational demands. It is free for commercial use, and it’s instruction-tuned versions contribute to wider adaptability.
References: https://ollama.com/library/gemma https://huggingface.co/blog/gemma https://huggingface.co/collections/google/gemma-release-65d5efbccdbb8c4202ec078b https://www.analyticsvidhya.com/blog/2024/02/gemma-llm/


