

GAN — What is wrong with the GAN cost function?
We work hard to produce mathematical models for deep learning. But often, we are not successful and fall back to the empirical data to support our arguments. Arjovsky et al 2017 wrote a paper to illustrate the GAN problem mathematically. The paper develops a mathematical model in an effort to illustrate potential issues with the GAN cost functions. Here are some of the claims:
- GAN has stability and saturation issue for both proposed objective functions (when the discriminator is optimal).
- Theoretically, it happens even a slight misalignment between the ground truth and the model, and
- During training, adding noise to generated images can stabilize the model.
This article is part of the series for GAN. By studying the mathematical model of the GAN objective functions, we get hints in understanding the stability and mode collapse issue. However, the claims are still highly debatable. So be prepared to have an open mind.
The perfect discrimination theorems
In practice, the discriminator can be trained reasonably well. Below, the DCGAN is trained for 1, 10 and 25 epochs. Then the generator is fixed while the discriminator is optimized. The discriminator can reach close to 100% accuracy fast, even in some case less than 50 iterations.
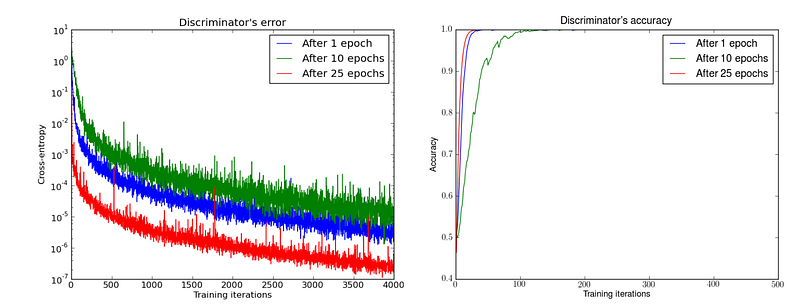
This should be good news since a good discriminator provides quality information to optimize the generator. But let’s take a moment to see what is the consequence of an optimal discriminator.
From the Arjovsky’s research paper: If two distributions have supports on low dimensional manifolds and they are not perfect align, the optimal discriminator will be perfect and the gradient for the GAN object function will be zero almost everywhere.
The support of a function is set of points where the function value is not zero.(Function f : A→B, the support is the set { x∈A : f(x)≠0 })
Hope that the claim does not scare you away already because it is not difficult to understand. If the latent feature z used to generate the image x (G(z)) is in a lower dimension than x, we can train a discriminator with 100% accuracy in detecting the generated images. Unfortunately, the gradient ▽D*(X) will be zero for almost everywhere. The theorem below shows the expected KL-divergence and JS-divergence of the data distributions for real and generated images (Pr and Pg) if they do not match exactly.

The problem of the GAN cost functions
Now let’s come back to the original GAN cost function and the alternative proposal that supposes to address the diminishing gradient for the generator.
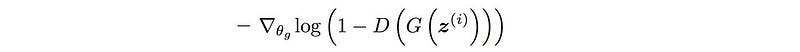
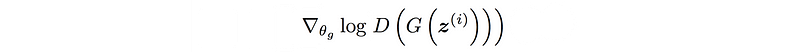
For the first cost function, the upper bound for the generator’s gradient is shown below.


In which, the gradient vanishes when the discriminator becomes optimal (D is close to D*). i.e.
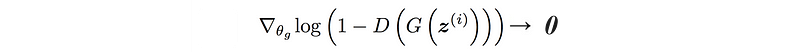
Gradient descent depends on the gradient to backpropagate signal. Regardless whether the prediction is accurate or not, vanishing gradients make learning very hard. Will the alternative cost function proposal do better?
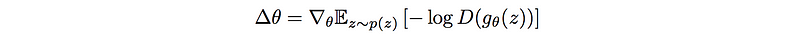
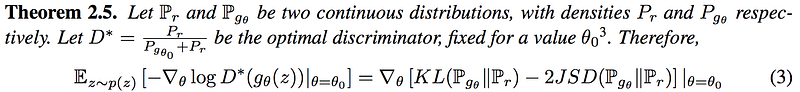
The new gradient composes of a reverse KL-divergence and a JS-divergence term. The reverse KL term assigns high cost in generating unnatural images while mode dropping is more acceptable. i.e. it generates more natural images but mode may collapse.

In theorem 2.6, it shows the new gradient has introduced a new problem. The updates to the model follow a centered Cauchy distribution which has zero mean and infinite variance. This large variance can make the model unstable. Also, in theory, the zero mean adds no change to the parameter in average, i.e. zero feedback.
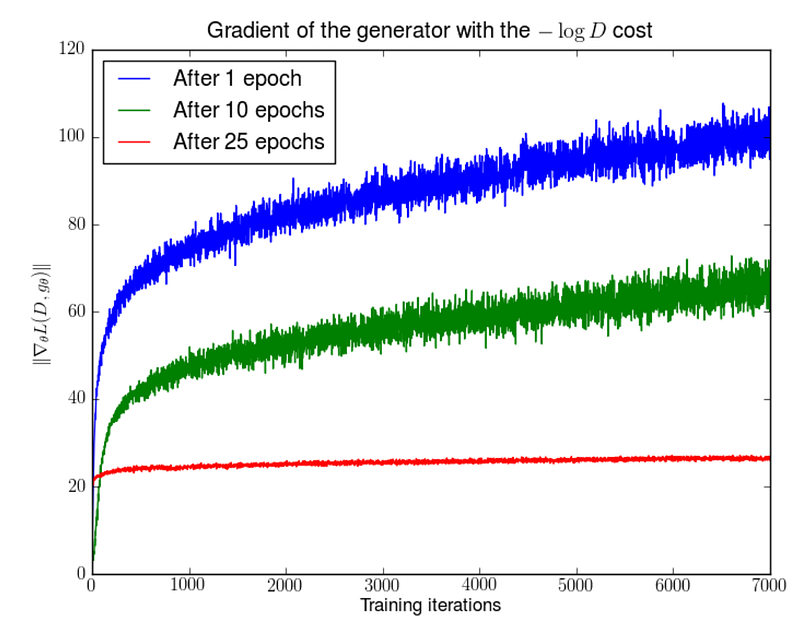
Here, the generator is fixed and the experiment optimizes the discriminator again. The diagram below plots the gradient changes during this training. As shown, not only the gradient goes up but it fluctuates more. All these lead to unstable models.
Adding noise
How can we mitigate the vanishing or exploding gradients?
Add noise (continuous noise) to the inputs of the discriminator to smoothen the data distribution of the probability mass.
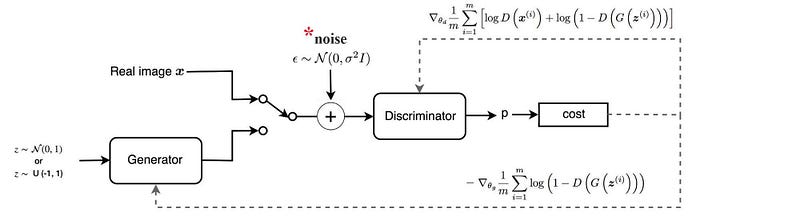
Let’s recompute the generator gradient with the presence of noise.
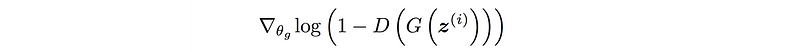
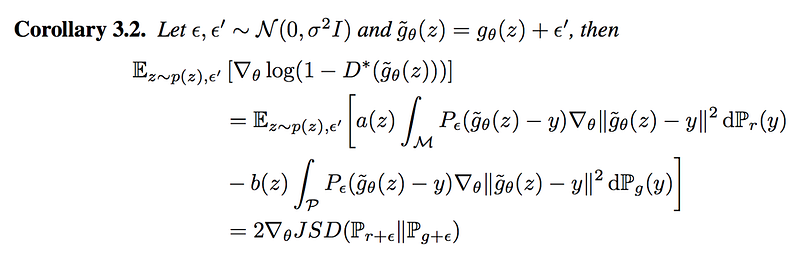
When noise is added, the gradient of the objective function equals to the JSD.
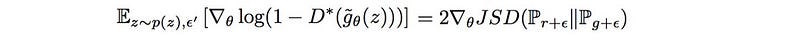
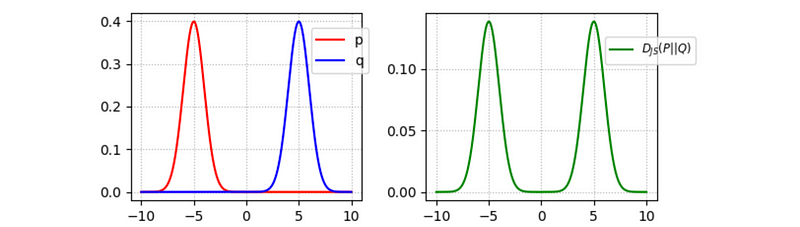
which is not zero when p and q are very different. This is excellent news because the generator’s gradient is not vanishing when the discriminator is optimal.
More thoughts
The mathematical model produces a good framework for discussion and study. But the debate on cost functions is likely to continue. The mathematical model paints a very negative picture on the original cost functions in GAN but not necessarily supported by experiments. There is a fundamental question: if the gradient behaves so badly, how can we explain the result using the original GAN. There is even a Google Brain report showing the “state-of-the-art” cost functions have no difference in performance if the GAN with the second objective functions is tuned more vigorously.
Is the mathematical model too simple? Does the batch normalization introduce noise to mitigate the problem? Can larger models take advantage of the new cost function? There are still many questions. Hopefully, presenting multiple viewpoints will help you to understand the fundamentals better.
Reference
Towards principled methods for training Generative Adversarial Networks





