GAN — Self-Attention Generative Adversarial Networks (SAGAN)
How can GAN use attention to improve image quality, like how attention improves accuracy in language translation and image captioning? For example, an image captioning deep network focuses on different areas of the image to generate words in the caption.

The highlighted area below is the attention area where the network focuses on in generating the specific word.

Motivation
For GAN models trained with ImageNet, they are good at classes with a lot of texture (landscape, sky) but perform much worse for structure. For example, GAN may render the fur of a dog nicely but fail badly for the dog’s legs. While convolutional filters are good at exploring spatial locality information, the receptive fields may not be large enough to cover larger structures. We can increase the filter size or the depth of the deep network but this will make GANs even harder to train.
Alternatively, we can apply the attention concept. For example, to refine the image quality of the eye region (the red dot on the left figure), SAGAN only uses the feature map region on the highlight area in the middle figure. As shown below, this region has a larger receptive field and the context is more focus and more relevant. The right figure shows another example on the mouth area (the green dot).

Design
For each convolutional layer,
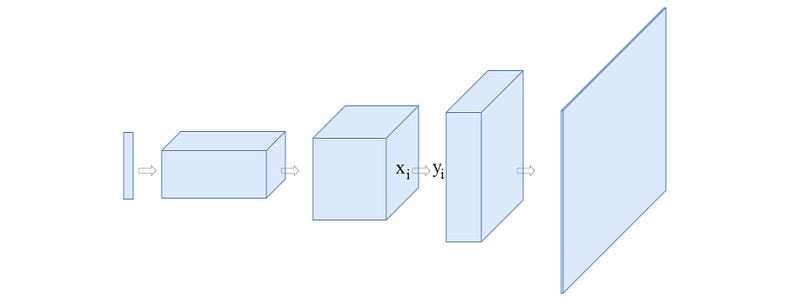
we refine each spatial location output with an extra term o computed by the self-attention mechanism.

where x is the original layer output and y is the new output.
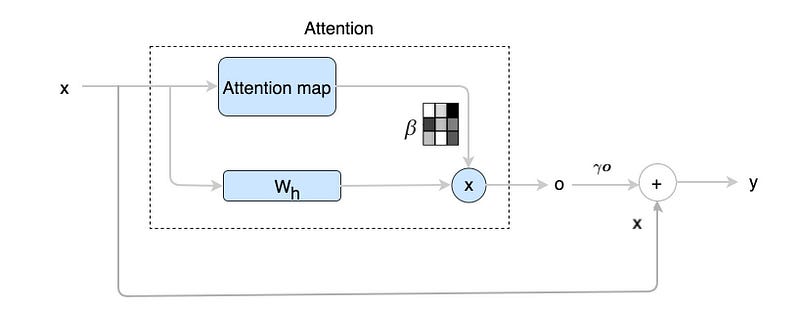
(Note, we apply the self-attention mechanism to each convolutional layers.)
The self-attention composes of
- Compute the attention map β, and
- Compute the self-attention output.
Attention map
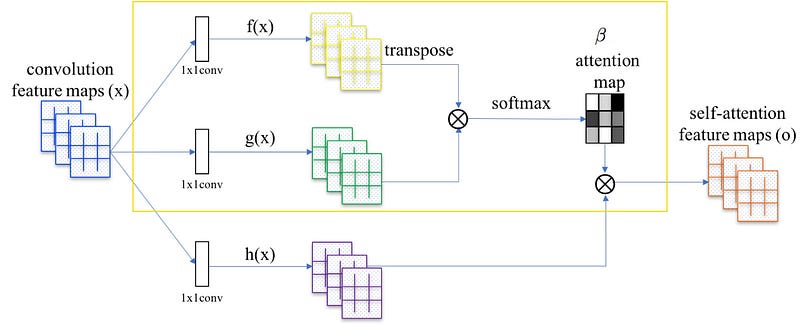
We multiple x with Wf and Wg (these are model parameters to be trained) and use them to compute the attention map β with the following formula:
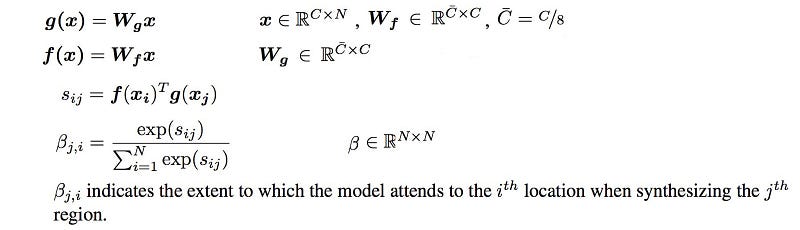
For each spatial location, an attention map is created which acts as a mask. βij is interpreted as the impact of location i when rendering the location j.

Attention output
Next, we multiple x with Wh (model parameters to be trained also) and merge it with the attention map β to generate the self-attention feature map output o.
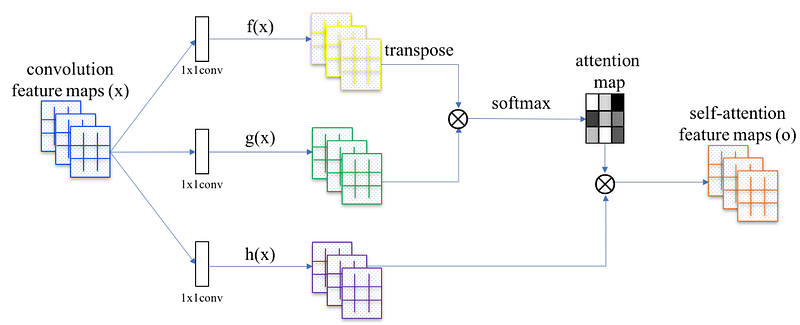
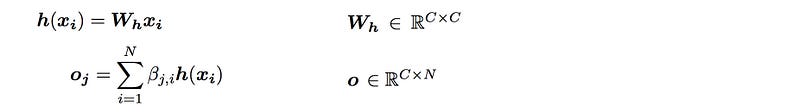
The final output of this convolutional layer is:
where γ is initialized as 0 so the model will explore the local spatial information first before refining it with self-attention.
Loss function
SAGAN uses hinge loss to train the network:
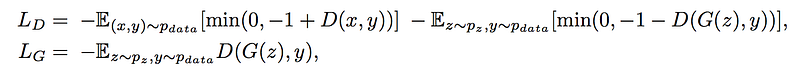
Implementation
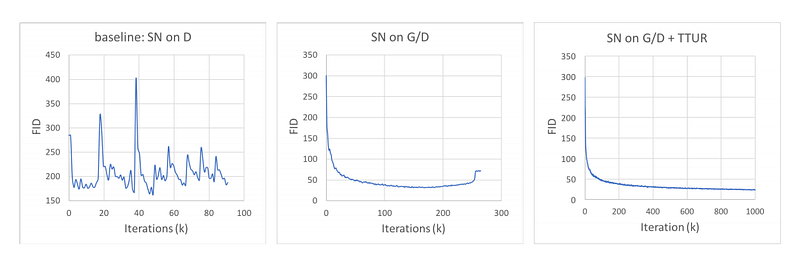
Self-attention does not apply to the generator only. Both the generator and the discriminator use the self-attention mechanism. To improve the training, different learning rates are used for the discriminator and the generator (called TTUR in the paper). In addition, spectral normalization (SN) is used to stabilize the GAN training. Here is the performance measure in FID (the lower the better).