
GAN — CycleGAN (Playing magic with pictures)
Many GAN research focuses on model convergence and mode collapse. We deal with game theories that we do not know how to solve it efficiently. But GAN can be fun, in particular for cross-domain transfer. CycleGAN transfers styles to images. For example, we start with collecting three sets of pictures: one for real scenery, one for Monet paintings and the last one for Van Gogh. Can we take a real picture and transfer the style of Monet or Van Gogh onto it? On the other hand, can we make a Monet picture looks real?

Can we turn a picture in the summer to winter?

In addition, the set of images are not paired, i.e. we do not have the real images corresponding to the same locations where Monet painted the pictures. CycleGAN learns the style of his images as a whole and applies it to other types of images.
CycleGAN
The concept of applying GAN to an existing design is very simple. We can treat the original problem as a simple image reconstruction. We use a deep network G to convert image x to y. We reverse the process with another deep network F to reconstruct the image. Then, we use a mean square error MSE to guide the training of G and F.
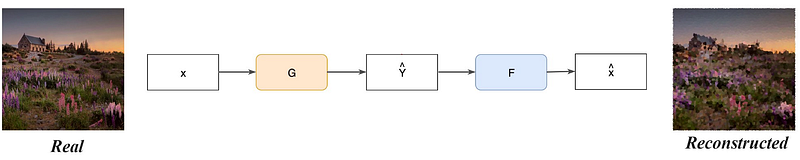
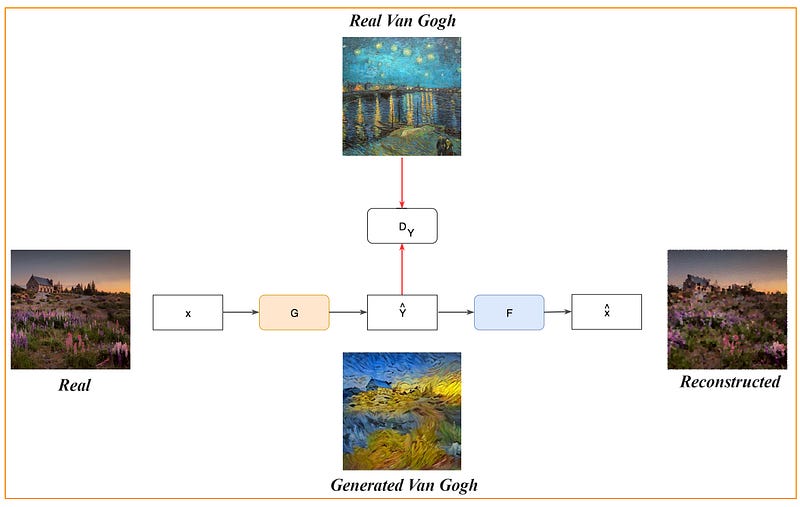
However, we are not interested in reconstructing images. We want to create y resembling certain styles. In GAN, a discriminator D is added to an existing design to guide the generator network to perform better. D acts as a critic between the training samples and the generated images. Through this criticism, we use backpropagation to modify the generator to produce images that address the shortcoming identified by the discriminator. In this problem, we introduce a discriminator D to make sure Y resemble Van Gogh paintings.
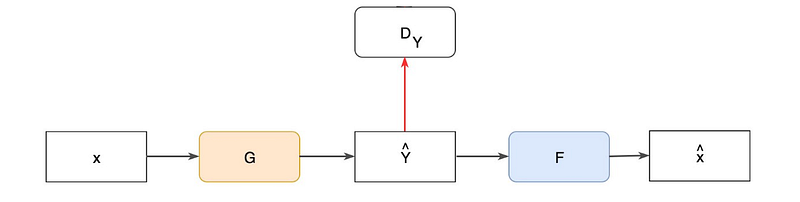
Network design
CycleGAN transfers pictures from one domain to another. To transform pictures between real images and Van Gogh paintings. We build three networks.
- A generator G to convert a real image to a Van Gogh style picture.
- A generator F to convert a Van Gogh style picture to a real image.
- A discriminator D to identify real or generated Van Gogh pictures.
For the reverse direction, we just reverse the data flow and build an additional discriminator Dx to identify real images.

Cost function
Training GAN is like training a design without GAN and then put back the adversary loss for the generator and the discriminator.
We first determine the reconstruction cost
- This is the Cycle consistency loss which measures the L1-norm reconstruction cost for the real image (x → y → reconstructed x) and the Monet paintings (y → x → reconstructed y)
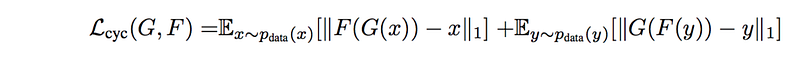
Then we add the adversary loss for the generator and the discriminator.
- Adversary loss
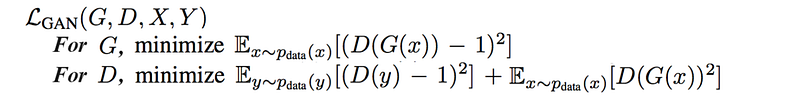
Here is the final objective function:
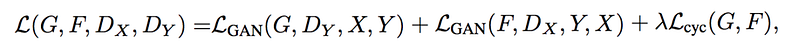
In addition, CycleGAN retains a history of the last 50 generated images to train the discriminator. Discriminators and generators can overfit themselves and fall into a cycle of greedy optimization that leads to the mode collapse. We use experience replay so the discriminator will not be overzealous in beating the current generator. It needs to beat the last 50 generators to create a more generalized solution.
Further readings
If your want to lean more on GANs:
Or you are interested to see more GAN applications:





