
FWD: Stephen Jones’ talk on “How GPU Computing — Where’s My Data” at GTC2021
https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31151/
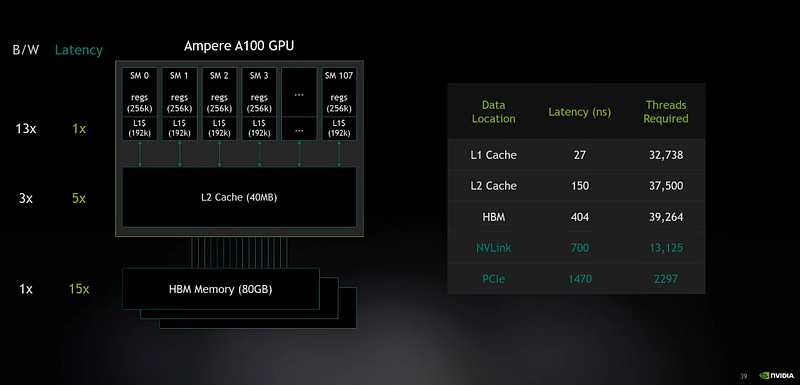
“14:26 the designers of the gpu put all the resources into adding more threads instead of cutting latency by contrast of the cpu it’s a latency machine the expectation of the cpu is that a single thread is largely doing all the work it’s expensive to switch out these threads from one to another it’s a context switch so you only need just about enough threads to cover the latency so the cpu designer puts all their resources into cutting latency instead of adding threads they’re two completely opposite approaches to attacking the same latency problem and this is really the root of the fundamental difference between how the gpu runs work and how cpu runs work…
21:14 … the the gpu is built with all these sms and all these threads in each sm this is part of the whole strategy remember the gpu designers fight latency by adding threads rather than finding latency by cutting latency down so i can have a lot more threads alive than running at any time 2048 in any
21:50 given sm but only 128 of them running at a time right this is the idea i was talking about that the gpu was oversubscribed so when some threads are off waiting for a read latency other threads have presumably received their response and are ready to go this is the entire secret to how the gpu works it can switch between warps instantly within a single clock cycle so there’s no contact switch overhead at all right it can literally run threads back to back that means it’s very important to have way more threads alive than the
22:23 system can run at any time because this is how you compensate for the latency it’s literally the opposite of the cpu where you never want to work subscribing your threads excuse me the gpu is a throughput machine.
38:38 i can beat latency with threads and i can beat bandwidth with locality and then i can get all the flops even from the tensor cores.”