
Fuzzy String Matching with Spark in Python — Real World Example

Fuzzy string matching is a technique often used in data science within the data cleaning process. It tries to match text that is not 100% the same because of various reasons (eg. human errors, different data sources, ...) but actually means or refers to the same thing, like ‘Barack Obama’ and ‘B. Obama’ in the context of American Presidents. This article will walk through the necessary steps (including the code) to perform fuzzy string matching on a real-world example using the Python API of Spark.
Real-World Example
As an example, we will work with two datasets that contain details of movies. The first dataset comes from GroupLens, a research lab at the University of Minnesota, and contains information for 62423 movies (dataset). The second dataset contains 100 movies from IMDB (dataset). The goal is to join the IMDB movies to their equivalent in the GroupLens dataset based on the movie title and show the corresponding rating from both platforms. Let’s start!
Spark Initialisation
We will be using Spark, a unified analytics engine for large-scale data processing. First, the spark context needs to be initialized.
import pyspark
from pyspark.sql import SparkSession, functions as Fsc = pyspark.SparkContext('local[*]')
spark = SparkSession.builder.getOrCreate()Data Loading
Before we can start processing the data, it needs to be loaded into a distributed data frame (DDF). This enables us to use a high-level API on top of spark's resilient distributed dataset (RDD).
The GroupLens dataset does not contain a single file with both the movies and their corresponding rating but a file with details of the movies and a separate file containing 25M individual ratings by users. We will first need to calculate the average rating per movie and join the result with the movie's details.
Let’s start loading the file containing the details of a movie while keeping only the necessary data by stripping the release year from the title and dropping the genres.
stripYear = F.udf(lambda title: title[:-7])
movies_ddf = (spark.read.csv('movies.csv', header=True, inferSchema=True)
.drop('genres')
.withColumn('title', stripYear(F.col('title'))))
movies_ddf.show(5, False)+-------+---------------------------+
|movieId|title |
+-------+---------------------------+
|1 |Toy Story |
|2 |Jumanji |
|3 |Grumpier Old Men |
|4 |Waiting to Exhale |
|5 |Father of the Bride Part II|
+-------+---------------------------+Next, we load the user ratings.
ratings_ddf = (spark.read.csv('ratings.csv', header=True, inferSchema=True)
.drop('timestamp'))
ratings_ddf.show(5, False)+------+-------+------+
|userId|movieId|rating|
+------+-------+------+
|1 |296 |5.0 |
|1 |306 |3.5 |
|1 |307 |5.0 |
|1 |665 |5.0 |
|1 |899 |3.5 |
+------+-------+------+Then we can calculate the average rating per movie and join the two DDF’s.
lens_ddf = (ratings_ddf
.groupby('movieId')
.avg('rating')
.select(F.col('movieId'), F.col('avg(rating)').alias('Rating'))
.join(movies_ddf, 'movieId'))
lens_ddf.show(5, False)+-------+------------------+-------------------------+
|movieId|Rating |Title |
+-------+------------------+-------------------------+
|1088 |3.25002094679514 |Dirty Dancing |
|1580 |3.5817083457378187|Men in Black (a.k.a. MIB)|
|3175 |3.6077836141619484|Galaxy Quest |
|44022 |3.2593627146699773|Ice Age 2: The Meltdown |
|175197 |2.754918032786885 |The Dark Tower |
+-------+------------------+-------------------------+The 100 IMDB movie dataset already contains all the needed data in a single file. Easy!
imdb_df = (spark.read.csv('imdb_sample.csv', sep=';', header='true')
.select('Id', 'Title', F.col('ImdbScore').alias('Rating')))
imdb_df.show(5, False)+---+------------------------+------+
|Id |Title |Rating|
+---+------------------------+------+
|1 |The Shawshank Redemption|9.2 |
|2 |The Godfather |9.2 |
|3 |The Godfather: Part II |9 |
|4 |Pulp Fiction |8.9 |
|5 |Schindler's List |8.9 |
+---+------------------------+------+Baseline Join
Now the data is properly loaded, we arrive at the interesting part of linking the GroupLens with the IMDB movies using ‘Fuzzy String Matching’. As a baseline, both datasets are joined by using Title resulting in 64 matches out of 100. Not bad but we can definitely do better!
result = imdb_df.join(lens_ddf, 'Title')
result.count()# 64 matchesRecord Linkage
To match the equivalent movie titles we need a metric that tells us how similar two strings are. The Jaccard Distance is a commonly used indicator of similarity between two finite sets. It is defined as 1 minus the size of the intersection divided by the size of the union of both sets.
D(A, B) = 1 - |A∩B|/|A∪B|
Before we can use this distance function, the strings need to be transformed into a set. Two techniques that are often used: Bag-of-Words and n-Grams. For this use-case Bag-of-Words isn’t suitable as misspelled words would never match against their original. Instead, we will use 2-Grams at the character level. One could pick another value for n but because the Titles are relatively short and the probability of (almost all) n-grams is small, a low value is preferred.
English contains a lot of very common words, called stop words. Including these in our sets could falsely decrease or increase the Jaccard Distance. Depending on the context, removing white space, capitals or punctuation could also be beneficial.
The only problem with this approach is that calculating this distance pair-wise for all the elements in both datasets explodes computational exponentially with the size of the dataset, O(n²). Luckily there already exists a technique called MinHash, to estimate this distance with lower complexity, implemented in Spark.
Preprocessing Pipeline
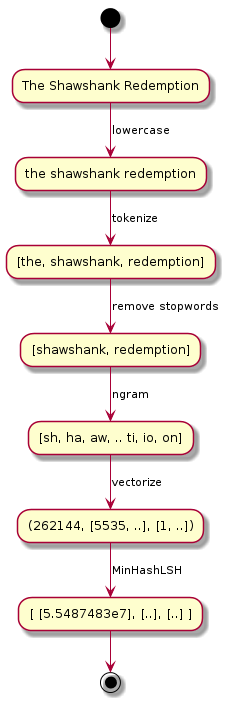
Let’s walk through the whole pipeline. First, the string is transformed to lowercase. Then, consecutively the lowercase string is tokenized and the most common (English) words are removed by the StopWordsRemover. After putting these keywords in the right format, we apply NGram, resulting in pairs of characters. Before we estimate the Jaccard Distance with MinHashLSH, the character pairs are vectorized.
The easiest way to implement this in Spark is by using a machine learning pipeline. This pipeline contains both existing transformers and user-defined SQLTransformers. The GroupLens and IMDB DDF are transformed by this same pipeline. There exist some anomalies in the dataset with movies that contain a single character. These result in an empty set of n-grams and can therefore not be hashed, thus should be filtered out.
First, we fit the pipeline on the GroupLens dataset and apply the transformation.
from pyspark.ml import Pipeline
from pyspark.ml.feature import StopWordsRemover, Tokenizer, NGram, HashingTF, MinHashLSH, RegexTokenizer, SQLTransformermodel = Pipeline(stages=[
SQLTransformer(statement="SELECT *, lower(Title) lower FROM __THIS__"),
Tokenizer(inputCol="lower", outputCol="token"),
StopWordsRemover(inputCol="token", outputCol="stop"),
SQLTransformer(statement="SELECT *, concat_ws(' ', stop) concat FROM __THIS__"),
RegexTokenizer(pattern="", inputCol="concat", outputCol="char", minTokenLength=1),
NGram(n=2, inputCol="char", outputCol="ngram"),
HashingTF(inputCol="ngram", outputCol="vector"),
MinHashLSH(inputCol="vector", outputCol="lsh", numHashTables=3)
]).fit(lens_ddf)result_lens = model.transform(lens_ddf)
result_lens = result_lens.filter(F.size(F.col("ngram")) > 0)Then we apply the same fitted pipeline on the IMDB dataset.
result_imdb = model.transform(IMDB_df)
result_imdb = result_imdb.filter(F.size(F.col("ngram")) > 0)Similarity Join
Now that both datasets are prepared, we can join them together by supplying a maximum Jaccard Distance that results in a match. Lowering this threshold will provide more exact matching and thus creating fewer false positives but could potentially lead to missing some true positives. A Jaccard Distance of 0.5 is the equivalent of a two-thirds match if both strings are of equal length.
result = model.stages[-1].approxSimilarityJoin(result_imdb, result_lens, 0.5, "jaccardDist")
(result
.select('datasetA.id', 'datasetA.Title', 'datasetB.Title', 'jaccardDist')
.sort(F.col('datasetA.id'))
.show(5))+---+--------------------+--------------------+-------------------+
| id| Title| Title| jaccardDist|
+---+--------------------+--------------------+-------------------+
| 1|The Shawshank Red...|Shawshank Redempt...|0.05555555555555558|
| 1|The Shawshank Red...| Redemption|0.47058823529411764|
| 10| Fight Club| Fight Club| 0.0|
| 10| Fight Club| Female Fight Club| 0.4375|
| 10| Fight Club| Zombie Fight Club| 0.4375|
+---+--------------------+--------------------+-------------------+Instead of lowering the Jaccard Distance to have fewer but more correct matches, you could select the match with the minimum distance at an extra computational cost. This is done by aggregating over id.
from pyspark.sql import Windoww = Window.partitionBy('datasetA.id')
result = (result
.withColumn('minDist', F.min('jaccardDist').over(w))
.where(F.col('jaccardDist') == F.col('minDist'))
.drop('minDist'))
(result
.select('datasetA.Title', 'datasetB.Title', 'jaccardDist')
.sort(F.col('datasetA.id'))
.show(5))+--------------------+--------------------+--------------------+
| Title| Title| jaccardDist|
+--------------------+--------------------+--------------------+
|The Shawshank Red...|Shawshank Redempt...| 0.05555555555555558|
| Fight Club| Fight Club| 0.0|
| Inglorious Basterds|Inglourious Basterds| 0.10526315789473684|
|The Lord of the R...|Lord of the Rings...|0.045454545454545414|
| Forrest Gump| Forrest Gump| 0.0|
+--------------------+--------------------+--------------------+The final data frame containing the ratings on IMDB and GroupLens can now be shown.
result.select('datasetA.Title', 'datasetB.Title', 'datasetA.Rating', 'datasetB.Rating').show(5)+--------------------+--------------------+------+-----------------+
| Title| Title|Rating| Rating (stars)|
+--------------------+--------------------+------+-----------------+
| Alien| Alien| 8.5|4.055518882196001|
|Star Wars Episode...|Star Wars: Episod...| 8.7|4.144122313069856|
| The Lion King| The Lion King| 8.4| 3.14922480620155|
|The Lord of the R...|Lord of the Rings...| 8.8|4.091188818716808|
|Once upon a Time ...| Once Upon a Time| 8.6|3.363636363636363|
+--------------------+--------------------+------+-----------------+Conclusion
A manual check tells us that 92 out of 100 IMBD movies have been matched with an equivalent from the GroupLens dataset with only a handful of false matches. Showing that efficient and effective fuzzy string matching can easily be implemented using Spark.




