
From Queries to Quality Answers: Harnessing the Potentials of RAG and Rerankers
Retrieval-Augmented Generation (RAG) stands as a powerful innovation in search and data retrieval, blending traditional methods with modern natural language processing to achieve impressive outcomes. However, navigating RAG can be challenging, especially for beginners, filled with complexities and high expectations.
This article simplifies these complexities, providing clarity on RAG and rerankers’ intricate workings. We start by exploring the fundamental challenges in standard retrieval methods, emphasizing the necessity for improvement. A key focus is placed on the role of vectors and embeddings in fine-tuning the retrieval process, explaining their significance in managing and resolving queries.
The role of rerankers is also examined, highlighting their ability to enhance the relevance and precision of retrieved results. Through this discussion, readers will gain deeper insights into embedding models and rerankers, understanding their essential functions in improving search and retrieval methods.
Before we proceed, let’s stay connected! Please consider following me on Medium, and don’t forget to connect with me on LinkedIn for a regular dose of data science and deep learning insights.” 🚀📊🤖
Making the Best Out of RAG
Diving into RAG (Retrieval-Augmented Generation) is like starting a new adventure, full of hopes and expectations. But using RAG is not as simple as just putting documents in a special database and getting them back when needed. It’s like a puzzle that needs different pieces to work together perfectly to show its full picture. To make RAG work its best, you need to make several improvements and fine-tunings, like adjusting and improving parts of a machine to make it run smoothly and efficiently.
Improving RAG with Reranking
Reranking is like a helper that makes the RAG system work better. Think of it as a friend who helps you sort and choose the best options. With reranking, the RAG system can give better and more accurate answers. It’s an important part that improves the way RAG works, helping it perform at its best
Solving the Puzzle of Retrieval
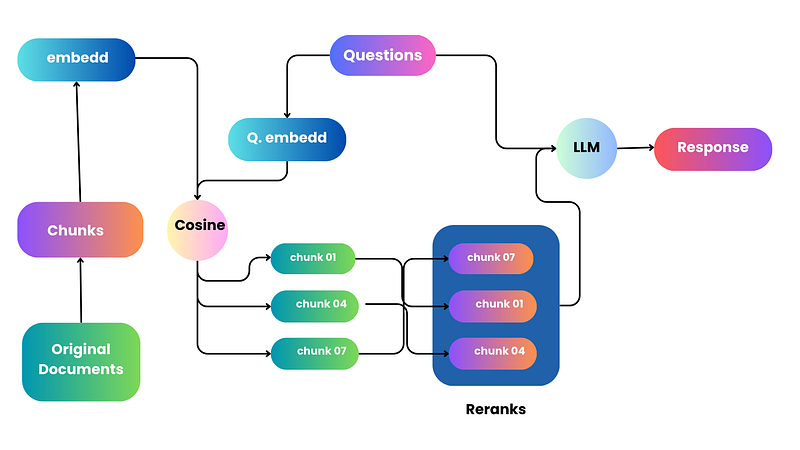
When we try to find and get back information, it’s like going on an adventure with many challenges. One main part of this adventure is using something called Vector Search. Imagine turning text into special codes (vectors) and putting them in a space where we can find them later. When we have a question (query), the system looks for the codes that match our question the best and shows them to us.
But it’s not always easy. When we turn text into these special codes, we have to simplify them, and sometimes we lose some details. Even though we have to make this compromise, Vector Search is still a great tool. It helps us find and get back the information we need more efficiently.
Making Searches Better with Re-ranking
Imagine you’re searching for something, and you get back a lot of answers. Re-ranking is like having a helper who sorts these answers for you. The helper (ranker) looks at all the answers carefully and puts the best ones at the top. This way, you see the most helpful information first. It makes sure that when the system looks at the answers to understand and use them better, it focuses on the most important ones, making the whole search process work better and give you what you need more quickly.
Do We Really Need the Ranker in Searches?
In our journey of making searches better, a big question pops up: Is having a ranker (our helper who sorts the answers) really necessary? Could we just make the original search method better and skip having a ranker? We could, and improving the basic way we search is something we’ll explore more. But, the ranker has a special job that makes it important. It has its own way of making searches work better, doing things that just improving the basic search might not do. In the future, we’ll talk more about why a ranker is a unique and powerful part of improving how we find information.
Imagine you are on a treasure hunt, looking for hidden gems in a vast jungle. Your goal is to find the most valuable treasures without spending too much time searching everywhere.
1. Initial Filtering with Encoders:
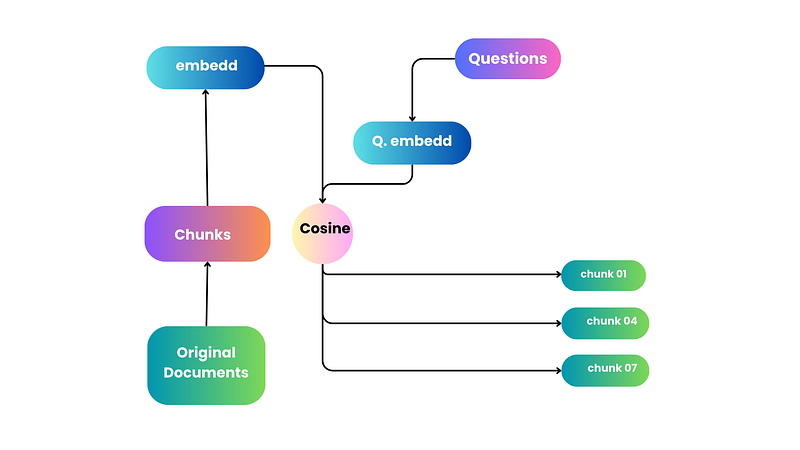
First, you have a map (encoder models) that guides you to places where treasures are most likely hidden. Instead of exploring the whole jungle, you use the map to quickly find a few spots where treasures are likely buried. This map helps you ignore less promising areas, saving time and effort. In the world of information retrieval, the encoder models swiftly sift through a massive number of documents and give you a more manageable, narrowed-down list of potential treasures (relevant documents).
2. Refinement with Rerankers:
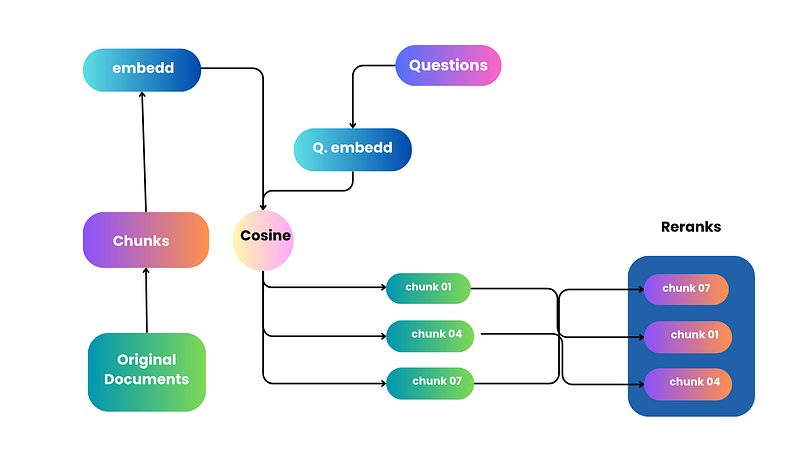
Now, you bring in an expert treasure hunter (reranker) to examine the treasures you’ve found more closely. The expert carefully assesses each item, evaluating its worth and relevance. With their expertise, they help you identify the most valuable and relevant treasures from the bunch, ensuring you walk away with the best finds (most relevant and precise documents).
Strategic Deployment:
Implementing rerankers in this process is like choosing when to call in the expert treasure hunter. You don’t want to bring them in too early because evaluating every possible treasure spot in the jungle would be exhausting and time-consuming. So, you strategically use the map first to narrow down the options, and then the expert steps in to make the final, refined selections.
In a nutshell, this strategy makes the retrieval process efficient, ensuring that you get the most accurate and valuable results without having to comb through every single piece of information in the massive jungle of documents.
example reranker code:-
from sentence_transformers import SentenceTransformer, util
import numpy as np
# Load the Sentence Transformer model
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# Sample documents
documents = ["The cat is on the roof",
"Dogs are in the garden",
"Birds are in the sky"]
# Embed the documents using Sentence Transformer
doc_embeddings = model.encode(documents)
def retrieve_and_rerank(query):
# Step 1: Initial Filtering with Sentence Transformers
query_embedding = model.encode(query)
similarities = util.pytorch_cos_sim(query_embedding, doc_embeddings)[0]
similar_docs = np.argsort(-similarities)
# Step 2: Rerank the filtered documents (you can use a more sophisticated reranker here)
reranked_docs = similar_docs # In this case, no further reranking is applied
# Printing the most similar documents
print("Most similar documents to the query:")
for i, idx in enumerate(reranked_docs[:3]): # Let's say we want the top 3 documents
print(f"Rank {i+1}: Document '{documents[idx]}' with similarity score of {similarities[idx]:.4f}")
# Test the retrieval and reranking with a query
retrieve_and_rerank("Where are the animals?")Learn more RAG
Conclusion
RAG and rerankers emerge as powerful tools in the realm of information retrieval, each playing a crucial role in optimizing and enhancing the results delivered. RAG, adept at navigating vast informational landscapes, brings forth relevant pieces of information, ensuring the generated responses are rich in context and coherence. On the other hand, rerankers fine-tune these results, ensuring that the output is not just relevant but precisely aligned with the user’s query.
Together, they forge a robust alliance, streamlining the retrieval process to be more efficient and effective. They allow systems to deliver meaningful and accurate responses, ensuring that users receive information that is not only helpful but also insightful. In embracing the collaborative strength of RAG and rerankers, we pave the way towards a more nuanced and refined approach to information retrieval.





