
France’s New AI Champion Scares Silicon Valley
Mistral’s New Model is a Box of Pleasant Surprises

Just a few months ago, a petit small French company was born. Three weeks later, it had already raised $113 million.
At the time, I recall searching the website, and it was almost plain HTML, a seemingly unimpressive CSS animation, and literally three lines of text.
Yet, the company was valued at a quarter of a billion dollars.
No team, let alone a product.
Still, they raised tons of millions through a diverse set of investors who thought that three Frency ex-DeepMind and Meta researchers were the real deal.
Now, we are starting to see why, thanks to the release of their first model, Mistral.
A 7-billion-parameter model that, despite its size, has crazy credentials already and comes packed with surprises that few saw coming.
The results are so good that, proportionate to its size, one could be bold enough to say that its the best Generative AI model ever created.
This model was originally covered days ago in my free weekly newsletter, TheTechOasis.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝 to become an AI leader among your peers and receive content not present in any other platform, including Medium:
Everyone Roots for the Small Guy
Since the dawn of modern civilization, aka the Greeks, humans have proven their innate desire to root for the small guys.
David, armed with a sling, manages to kill his enemy, the giant Goliath.
This story showcased what we define as the underdog mentality, that feeling that pushes small teams to believe and win against theoretically much superior teams while also earning the respect and admiration of society.
Unsurprisingly, underdogs appeal to people. Society enjoys seeing big guys lose.
In AI, it seems the trend repeats.
Even though the gap between private and open-source models is massive, people still believe and hope that one day, the greatest technology ever created by humans will be largely driven by open-source innovation and not by the Silicon Valley behemoths.
But will this eventually happen?
Mistral-7B gives many the hope that the answer will be yes.
A Small, Uncanny Beast
Despite being very, very small in AI terms, Mistral-7B is scarily good.
Besides completely obliterating LLaMa-7B, Meta’s model of the same size, it also surpasses the 13 billion version, almost two times its size, in all evaluated benchmarks.
Mistral-7B is so good that it even manages to beat LLaMa’s 34-billion-parameter model, a model 5 times larger (in this case, the first version of LLaMa) in mathematics, reasoning, and code generation.
And if that’s not all, the model is also faster, optimized for cost, and specially designed for large batches, meaning that its throughput is consistently superior to most other models.
But how did they manage to pull all this off?
Attention is All you Have to Improve
Mistral is a Transformer-based model. No surprises here.
However, it has a handful of things that make it unique.
Shortsighted attention… or not?
The first innovation comes when discussing the attention mechanism that sits at the core of any Transformer, including ChatGPT.
The idea is simple: to one word in a sequence, when compared to the rest of the words in the sequence, some matter more to it than others.
In layman’s terms, if you give the model the sequence ‘My name is Nacho, and I’m Spanish,’ the model needs to identify that the adjective ‘Spanish’ refers to the noun ‘Nacho’.
To know what words mean more to one particular word (for the model to know that ‘Spanish’ refers to ‘Nacho’ in the previous sequence), Transformer models perform the self-attention mechanism, where each word ‘talks’ with all its previous words.
Technical clarifications: When I say ‘talk’, I really mean that ‘query’ vector embedding of each word gets multiplied by the ‘key’ vector embeddings of the rest, and the larger the result the more attention that word needs to give to the other.
The intuition behind this is that the more semantically similar two words are, the more similar their vectors will be and, hence, the larger the result of the dot product between them. The larger the dot product, the more attention that word is given.
One way to define the attention mechanism is that the meaning of a word is the ‘sum’ of the attention it pays to the other words in the sequence.
Also, transformer decoders like ChatGPT or Mistral are autoregressive, meaning that all words can only look back to previous ones, as the ones coming next have yet to be predicted based on the previous words.
When visualizing it, the process would be something like below, where each one only talks to the ones preceding it (marked in yellow).
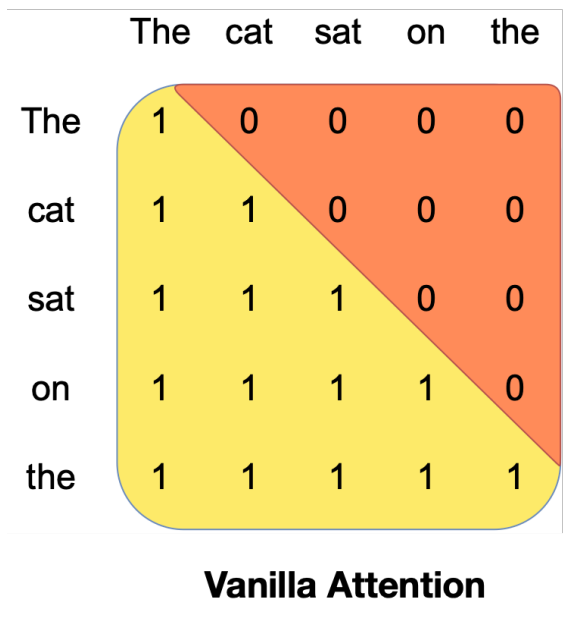
But there’s a problem.
As the sequence length grows in size, the number of multiplications to be done increases, too.
In fact, the computational costs of processing a sequence are quadratic to the sequence length. In other words, if the sequence doubles, the computational cost quadruples.
To solve this, Mistral proposes its first solution, Slided-Window Attention. In this case, the number of words each word can talk to is not only limited to the ones preceding it, it’s also limited to a fixed number of them.
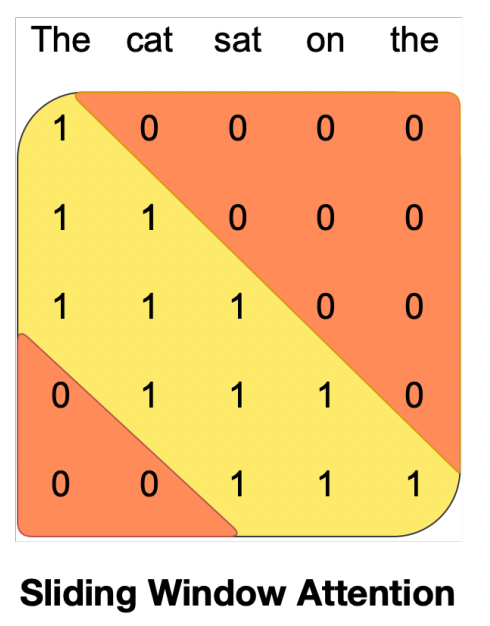
Using the example above, the word ‘cat’ only talks ‘The’, as expected, but the word ‘on’ won’t talk to ‘The’ as the word separation is larger than the fixed-maximum distance between them (three in this case).
But why do this?
If we limit the number of words one word can talk to, you also reduce the total amount of computations required to perform the attention mechanism (remember, when we say ‘talk’, we really mean a dot product calculation, so less ‘word talking’ means fewer computation requirements).
Naturally, you may think, ‘but less ‘word talking’ wouldn’t mean that a word in a position sufficiently separated from the start of the sequence would lose the capacity to ‘see’ what was said at the beginning of the sequence and, thus, mean that situations were context requires a global understanding of the sequence suffer from quality loss?’
The key intuition is that, even though we are, in fact, limiting the capacity of different parts of a sequence to ‘talk’ to each other, the way Transformer neural networks are built allows words at initial parts of a sequence to ‘carry’ knowledge to words in the further parts of the text sequence throughout the attention layers.
Although this may seem very complex to understand, it’s actually quite simple to explain if we look at the image below:
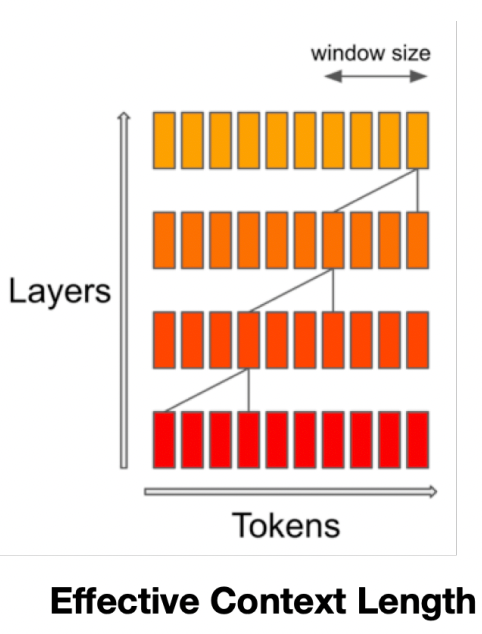
Each of the little squares in the first red row of the image are the words in the sequence. Throughout every attention layer, each word is updated with contextual information about the preceding words.
The reason for this is that as words are updated with information about previous words in the sequence, the model eventually understands the complete text.
That’s how models like ChatGPT understand context.
In other words, if we look at the fourth word in the sequence to the left, this word will be updated with information regarding the previous three (depicted with the triangular shape in the image). This updated version of this word is represented in the second layer (orange color).
At the same time, this newly updated fourth word in orange will be attended by the fifth, sixth, and seventh words, as it falls inside the attention window with a fixed value of three used in this example (second triangle).
Consequently, even though word seven will never attend to word one or two, the information of these words is carried by the fourth word into the second layer, thereby meaning that ‘some’ knowledge from those words will be dragged in.
And the proof that this solution actually works is that this Mistral model showcases one of the best performances with long sequences in any of these small models, thanks to the fact that fewer computational requirements mean that the model can be trained with longer sequences.
In other words, this not only doesn’t affect the model’s quality, but the drop in computational requirements even allows the model to be trained on larger sequences.
Guys, it seems that slide-window attention is here to stay, but this French company had a few extra surprises.
Rolling past others
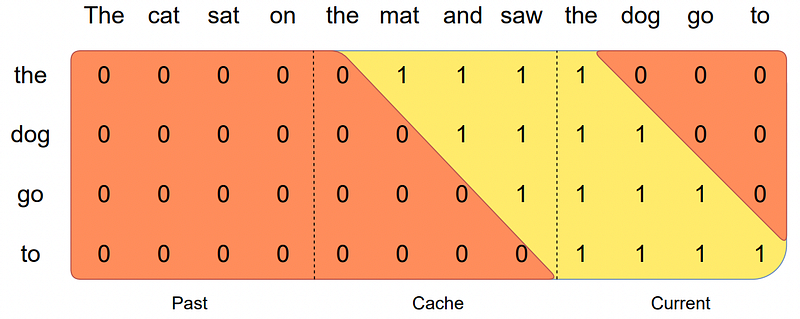
The fact that the attention mechanism was ‘chopped off’ means that the memory requirements can also be reduced.
As you probably guessed, as words talk to previous ones for every new word predicted, this creates a lot of redundant computation. Therefore, we have a thing called the (k,v) cache that, although I won’t get into detail for the sake of this article’s length, stores these calculations in memory so that they are computed only once.
But as we have chopped off the attention mechanism to a limited number of preceding words for every word, we also limit the size of the (k,v) cache matrix and, thus, reduce the memory requirements, too.
It’s called a ‘rolling’ cache because the sequence grows in size, initial words lose importance and, thus, their attention values are overwritten, meaning that the cache matrix ‘rolls’ along the sequence.
A Warning to Seafarers in Silicon Valley
If there’s one way to put it, Mistral’s model is a marvel of training efficiency.
Besides the alleged constraints put on the model to make it more efficient and cost-effective to train, the model still manages to blow out of the water similar-sized models and, in some cases, models many times larger considered state-of-the-art not long ago.
These results signal two conclusions:
- We are still far away from truly maximizing performance relative to size
- For enterprise use cases, having small, performant models has huge appeal, meaning that results like this may incentivize corporations to delve into the open-source world and benefit from complete control and security.
The latter point may also support a growing intuition brewing in the minds of many in this industry:
The belief is that huge models like ChatGPT are poised to become consumer-end products, products that appeal greatly to end-users as they can help you with pretty much anything, while smaller, efficient, and most probably specialized models will have a much broader appeal to corporations, where models are required to do great at one or few things, not many.
That being said, the reality is that ChatGPT remains king… for the moment.




