
Forward and Backward propagation in Convolutional Neural Networks
Theory and Code

Introduction
If you are here you have definitely heard about Convolutional Neural Networks and perhaps you are now trying to understand how they work under the hood. In this case this article should help you to get your head around how forward and backward passes are performed in CNNs by using some visual examples. I assume that you are familiar with padding and strides in CNNs and have some basic understanding of backpropagation and the chain rule.
Forward propagation
We start with one Input of shape 5x5 and one filter of shape 3x3. We assume number of channels C = 1 , stride = 1.

We perform padding with pad = 1 to have the shapes of the output and the input after convolution operation the same.
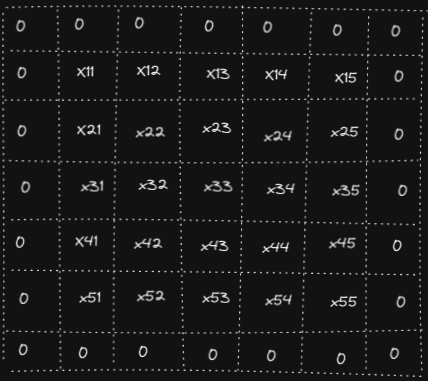
Indeed, we can compute the output shape using the following formula: H_out = floor(1 +(H + 2 * pad — HH)/stride) W_out = floor(1 +(W + 2 * pad — WW)/stride) where H is height of the input, HH is height of the filter W is width of the input, WW is width of the filter
In our example we get: H_out = floor(1 + (5 + 2 * 1–3)/1) = 5 W_out= floor(1 + (5 + 2 * 1–3)/1) = 5
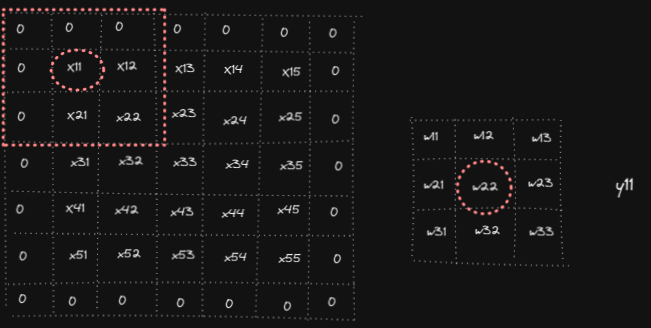
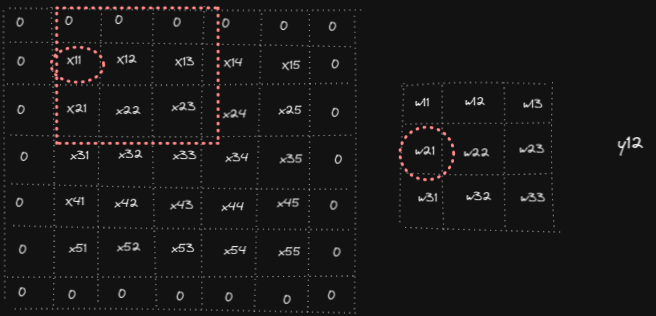
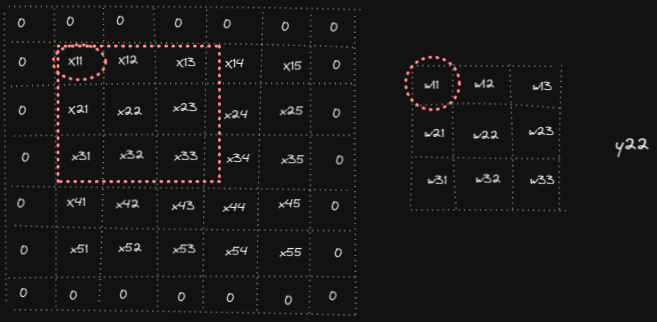
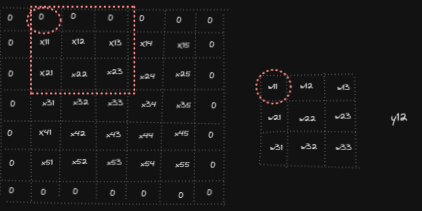
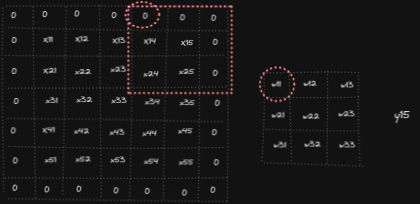
Forward pass in convolution operation consists of overlapping filter weights on the input, multiply them and sum the results to get the output. Below animation shows the computations for y₁₁, y₁₂ and y₅₅ (analogously other outputs yᵢⱼ are computed)

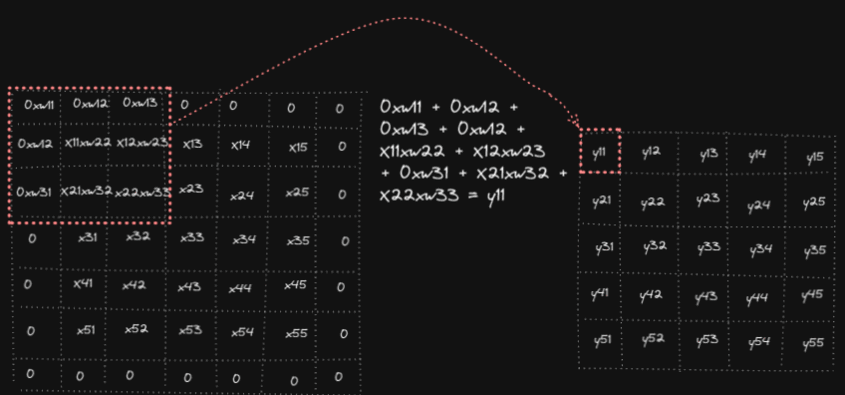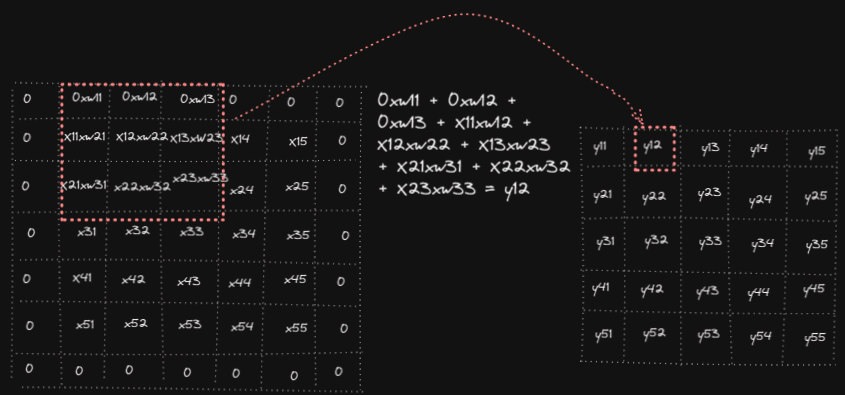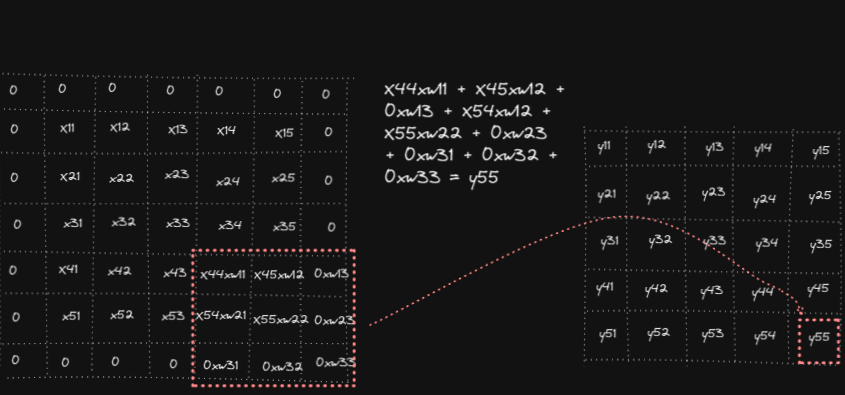
In code:
Backpropagation
We will need to compute the derivatives of the Output Y with respect to input X, filter W and bias b. Computing the derivatives with respect to bias b is easy and I would recommend to try it yourself after reading this tutorial — you will definitely be able to do it! Now let’s finally start from ∂Y/ ∂X:
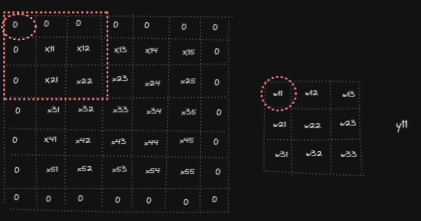
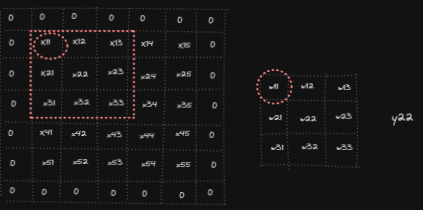
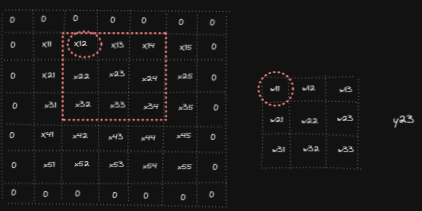
Let’s start by looking what the derivative of the output Y with respect to the first element of X is, namely we want to compute ∂Y/ ∂x₁₁. We can notice x₁₁ affects y₁₁, y₁₂, y₂₁ and y₂₂ as it is involved in the calculations of those output cells. And so we get ∂Y/ ∂x₁₁ = ∂y₁₁/ ∂x₁₁ + ∂y₁₂/ ∂x₁₁ + ∂y₂₁/ ∂x₁₁ + ∂y₂₂/ ∂x₁₁ = w₂₂ + w₂₁ + w₁₂ + w₁₁ In a similar fashion we can compute the other partial derivatives for the elements of X.
Also note that the shape of ∂X is the same of the unpadded X so we do not need to compute derivatives with respect to the padded elements

There is a bit more to that. When doing backpropagation, we usually have an incoming gradient from the following layer as we perform the backpropagation following the chain rule. So in this case we assume the convolutional layer is followed by , we would have the incoming gradient of Y with respect to the loss L, ∂L/∂Y. It is the same shape as Y and this is the only thing we need to know as we won’t be calculating this derivative in this article.

So when computing ∂Y/∂x11 we will also need to multiply ∂Y/∂X by respective incoming derivatives ∂L/∂Y : (1) ∂Y/∂x₁₁ = ∂l/∂y₁₁ * ∂y₁₁/∂x₁₁ + ∂l/∂y₁₂* ∂y₁₂/∂x₁₁ + ∂l/∂y₂₁ * ∂y₂₁/∂x₁₁ + ∂l/∂y₂₂ * ∂y₂₂/∂x₁₁ = dy₁₁ * w₂₂ + dy₁₂ * w₂₁ + dy₂₁ * w₁₂ + dy₂₂ * w₁₁
If we print the w_idxs and y_idxs after the first loop through all width (W1) and height (H1) we get the respective cells of W and ∂L/∂Y matrices to compute ∂Y/∂x₁₁:
w_idxs = [(1, 1), (1, 0), (0, 1), (0, 0)]
y_idxs = [(0, 0), (0, 1), (1, 0), (1, 1)]in fig4 we start indexing from 1, so if we add one to w_idxs and y_idxs we see that in the last row to get the derivative with respect to the first element of X, dx₁₁ we multiply exactly the same elements as in our formula above.
To compute ∂Y/ ∂W we proceed in a similar way (Note that we do not show all the operations to avoid having too many images):
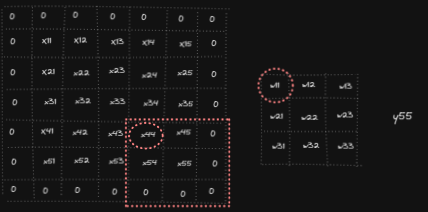
Looking at dY/dw₁₁ , we can see that change in w₁₁ affects all yᵢⱼ for every i,j. Now, instead of considering X we need to consider X_padded so instead of indexing from 1 to 5, X_padded will be indexed from 0 to 6.
(2) ∂Y/∂w₁₁ = ∂l/∂y₁₁ * ∂y₁₁/∂w₁₁ + ∂l/∂y₁₂ * ∂y₁₂/∂w₁₁ + … + ∂l/∂y₄₅ * ∂y₄₅/∂w₁₁ + ∂l/∂y₅₅ * ∂y₅₅/∂w₁₁ = dy₁₁ * x₀₀+dy₁₂ * x₀₁+ … + dy₄₅ * x₄₃+ dy₅₅ * x₄₄
As we can see, because each weight affect every output all the elements the incoming derivative ∂L/∂Y are used to compute ∂Y/∂wᵢⱼ
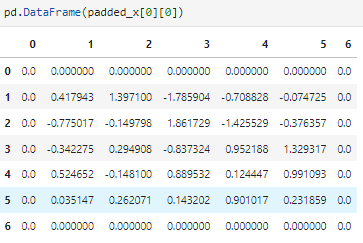
If we look at the elements that are summed to compute dw[0,0] (ignoring filters and channels) : given padded_x:
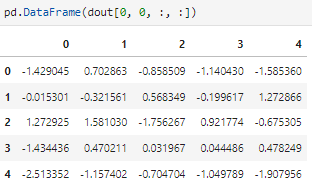
And dout derivatives:
We multiply the selected elements from padded_x from x₀₀ to x₄₄
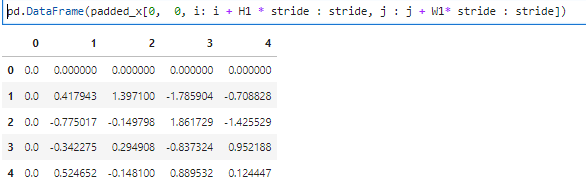
with all the elements of dout and then sum everything up like in (2) :

Note that we have seen forward and backward passes assuming 1 channel and 1 filter, but the code is able to handle multiple channels and filters and the explanation you have read so far is easily generalizable.
Conclusions
You should now have a good understanding of how backward and forward passes are done within CNNs. Obviously, you don’t need to implement them by hand — in the code snippets above we used for loops which are easy enough to follow, but are very slow and inefficient! No worries though, there are many packages out there that do all the work for you using very efficient implementation.




