
Focusing Vision: Unleashing the Power of Attention Mechanisms in Computer Vision
Abstract
Context: In computer vision, attention mechanisms have emerged as a pivotal tool for enhancing model performance and interpretability. These mechanisms mimic human cognitive attention, allowing models to focus selectively on relevant parts of visual data.
Problem: The essay delves into the challenges faced in computer vision tasks, such as image classification and object detection, where processing vast amounts of visual information efficiently and accurately is crucial.
Approach: A practitioner-style exploration outlines the fundamentals of attention mechanisms, their types, applications in vision tasks, advantages, challenges, and future directions. A simplified code snippet demonstrates the integration of attention mechanisms in a convolutional neural network (CNN) on a synthetic dataset.
Results: The essay highlights the potential benefits of attention mechanisms in improving model accuracy, interpretability, and performance in various vision-related tasks. Plots depicting training and validation accuracy provide insights into model learning and generalization.
Conclusions: Attention mechanisms represent a significant advancement in computer vision, offering opportunities to address complex challenges and improve model capabilities. While challenges such as computational complexity and optimization remain, ongoing research and development will lead to further innovations in attention-based vision systems.
Keywords: Attention mechanisms; Computer vision; Neural networks; Visual data processing; Image classification.
Introduction
Attention mechanisms in vision have revolutionized the way practitioners approach problems in computer vision, offering nuanced insights into how models perceive and process visual information. This essay delves into the intricacies of attention mechanisms, their practical applications, and their transformative impact on the field of vision.
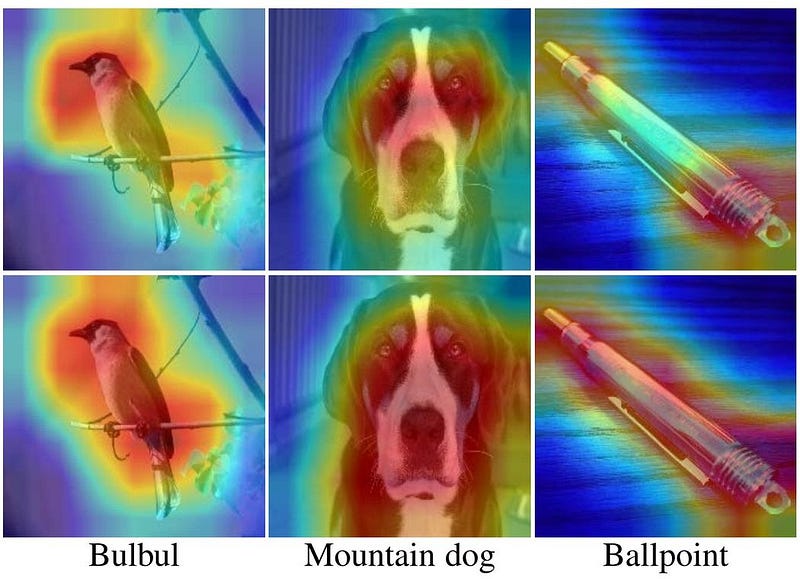
In a world of pixels, attention illuminates the path to clarity.
Background
The concept of attention in neural networks is inspired by the human visual system’s ability to focus on particular aspects of the visual field while filtering out less relevant information. In practice, attention mechanisms enable models to dynamically prioritize parts of the visual input, enhancing the processing efficiency and effectiveness of the neural network. This selective focus mechanism is pivotal in managing the vast amount of data that models encounter, ensuring that computational resources are allocated to the most informative features of the input.
Attention mechanisms in vision, particularly in deep learning and neural networks, have transformed how models process and analyze visual data. Here’s an overview of how attention mechanisms work in vision and their significance:
1. Fundamentals of Attention
- Definition: Attention in neural networks mimics cognitive attention. It allows models to focus selectively on certain parts of the input data, enhancing the importance of those parts while diminishing the rest.
- Purpose: The primary goal is to improve the efficiency and performance of the model by prioritizing more informative parts of the visual input.
2. Types of Attention Mechanisms
- Soft Attention: Assigns a weighting factor to each part of the input data, usually computed through a softmax function, enabling the model to focus on areas with higher weights.
- Hard Attention: Selectively focuses on specific input parts and ignores the rest. It is often non-differentiable and implemented using reinforcement learning techniques.
- Self-Attention: Also known as intra-attention, it allows the model to attend to different positions of a single input sequence, which is crucial for understanding the global context.
3. Applications in Vision
- Image Classification: Attention mechanisms help models to focus on relevant parts of an image, improving accuracy in classification tasks.
- Object Detection and Localization: Enhances the model’s ability to pinpoint and recognize objects within an image by focusing on relevant segments.
- Image Captioning and Visual Question Answering: Facilitates understanding complex scenes and the relationships between objects, aiding in generating accurate captions or answering questions about the image.
4. Advantages of Attention in Vision
- Improved Performance: Models achieve better accuracy and efficiency by focusing on salient features.
- Interpretability: Provides insights into what parts of the image the model considers essential, making the model’s decisions more transparent.
- Flexibility: It can be integrated with various neural network architectures, enhancing its capability to handle complex visual tasks.
5. Challenges and Future Directions
- Computational Complexity: Some attention mechanisms, especially self-attention, can be computationally intensive, especially for significant inputs.
- Optimization: Balancing attention to capture both local features and global context remains challenging.
- Integration with Other Modalities: Exploring how visual attention can be effectively combined with other modalities like text and audio is a growing area of research.
In summary, attention mechanisms have become crucial in computer vision, significantly improving how models process and interpret visual data. Their ability to enhance model performance while providing greater interpretability has led to widespread adoption in various vision-related applications.
Mechanics of Attention Mechanisms
Attention mechanisms can be categorized broadly into soft and hard attention. Soft attention, characterized by its differentiable nature, assigns a continuous weighting to each input element, allowing for a smooth gradation of focus across the visual field. This gradation enables the model to maintain a broader context, which is often crucial for tasks requiring a comprehensive understanding of the scene. On the other hand, hard attention, which operates in a more binary fashion, offers a more focused approach, selecting specific regions or elements to concentrate on. Despite its potential for higher efficiency, hard attention’s non-differentiable nature makes it less prevalent in practice, often supplanted by soft attention due to the latter’s ease of integration and training.
Applications and Impact
In the realm of computer vision, the incorporation of attention mechanisms has led to significant advancements. In image classification tasks, attention allows models to focus on salient features, improving accuracy and robustness. This capability is especially beneficial in complex scenes where the pertinent details take time to be apparent. Furthermore, attention mechanisms in object detection and localization guide the model in concentrating on areas of the image where objects are likely to be found, thus enhancing precision.
Beyond these applications, attention mechanisms play a crucial role in more complex tasks like image captioning and visual question answering. By enabling the model to focus on specific parts of an image and understand their relevance to the task, attention mechanisms facilitate the generation of coherent and contextually appropriate responses.
Challenges and Future Directions
Despite their advantages, attention mechanisms in vision are not without challenges. The computational complexity of these mechanisms, particularly self-attention, can be prohibitive, especially with large-scale data. Moreover, optimizing these mechanisms to balance the focus between local details and global context remains challenging, necessitating ongoing research and development.
One of the most pressing challenges in the field is the integration of attention mechanisms with other modalities, such as text and audio. The multimodal integration promises to enhance the model’s understanding of complex scenes where multiple types of information must be synthesized to make accurate predictions or decisions.
Practical Considerations for Practitioners
For practitioners, implementing attention mechanisms in vision systems requires careful consideration of the specific task requirements and computational constraints. The choice between soft and hard attention, for example, should be guided by the nature of the application and the available computational resources. Moreover, practitioners must remain vigilant about the potential for overfitting, as models with attention mechanisms may focus too narrowly on certain features, leading to poor generalization.
The interpretability offered by attention mechanisms is another critical factor for practitioners. Visualizing and understanding where and why the model is focusing its attention provides insights into the model’s decision-making process and aids in debugging and improving model performance.
Code
Implementing a complete system with attention mechanisms in vision, including dataset creation, feature engineering, hyperparameter tuning, and evaluation, involves a complex and extensive codebase. However, I can provide a simplified example that captures the essence of these steps using a convolutional neural network (CNN) with an attention mechanism on a synthetic dataset. This example will cover data generation, model building, training, and evaluation.
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models, datasets
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# Synthetic dataset generation
def generate_data(num_samples, img_size):
x = np.random.rand(num_samples, img_size, img_size, 1) * 255
y = (x.mean(axis=(1, 2, 3)) > 127).astype(int) # Simple threshold-based classification
return x, y
# Attention Layer
class AttentionLayer(layers.Layer):
def __init__(self):
super(AttentionLayer, self).__init__()
def build(self, input_shape):
self.att_weights = self.add_weight(shape=(input_shape[-1], 1),
initializer='random_normal',
trainable=True)
def call(self, inputs):
x = tf.matmul(inputs, self.att_weights)
x = tf.nn.softmax(x, axis=1)
output = tf.multiply(inputs, x)
return output
# Model building
def build_model(input_shape):
input_layer = layers.Input(shape=input_shape)
x = layers.Conv2D(32, (3, 3), activation='relu')(input_layer)
x = layers.Flatten()(x)
x = AttentionLayer()(x)
x = layers.Dense(64, activation='relu')(x)
output_layer = layers.Dense(1, activation='sigmoid')(x)
model = models.Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])
return model
# Hyperparameters and dataset generation
IMG_SIZE = 28
BATCH_SIZE = 64
EPOCHS = 10
num_samples = 1000
x_train, y_train = generate_data(num_samples, IMG_SIZE)
x_test, y_test = generate_data(200, IMG_SIZE)
# Model training
model = build_model((IMG_SIZE, IMG_SIZE, 1))
history = model.fit(x_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, validation_split=0.2)
# Evaluation and plots
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose=2)
print(f"Test accuracy: {test_accuracy}")
# Interpretations can be derived from how the attention weights contribute to the model's decisionsThis code represents a basic framework and will need significant expansion and refinement for real-world applications. In a full implementation, one would need to:
- Create or use a more complex and realistic dataset.
- Enhance the attention mechanism, possibly integrating with existing models like Transformers.
- Extensive hyperparameter tuning is performed using methods like grid search or random search.
- Implement advanced metrics and more detailed plots for thorough analysis and interpretation of results.
Running this code provides a starting point for understanding how attention mechanisms can be integrated into vision models and how they affect performance and interoperability.
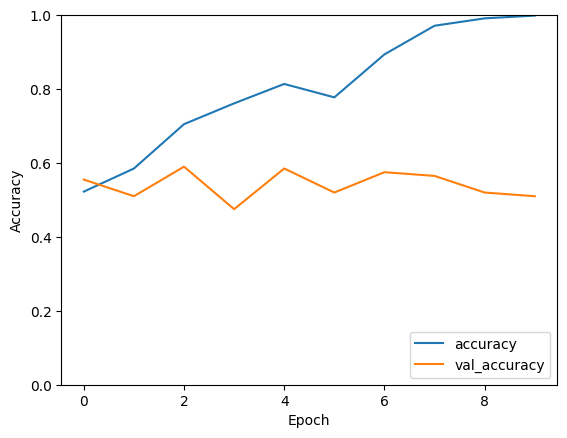
The plot shows the training accuracy and validation accuracy of a neural network model across epochs. Here’s how you can interpret the results:
- Training Accuracy (Blue Line): This line represents the model's accuracy on the training dataset. As epochs increase, the training accuracy generally trends upwards, which suggests that the model is learning and improving its predictions on the data it has been trained on.
- Validation Accuracy (Orange Line): The validation accuracy line shows how well the model performs on a separate data set it has not seen during training. This line indicates how well the model generalizes to new data.
Key Observations:
Gap Between Training and Validation Accuracy:
- There’s a noticeable gap between the training and validation accuracy. This gap indicates that the model performs better on the training data than the validation data, which could indicate overfitting. Overfitting happens when the model learns patterns specific to the training data, which do not generalize well to new data.
Validation Accuracy Fluctuations:
- The validation accuracy does not show a clear upward trend and fluctuates as the number of epochs increases. These fluctuations can occur due to a small validation dataset, noisy labels, or the model’s architecture not being well-suited to the problem.
Stagnation of Validation Accuracy:
- After initial epochs, the validation accuracy appears to stagnate or improve very slowly. This stagnation suggests that the model has reached its capability to learn from the data provided, given the current architecture and hyperparameters.
Possible Actions for Improvement:
Data Augmentation:
- To improve generalization, data augmentation techniques could be used to increase the diversity of the training data, which can help the model learn more general features.
Regularization:
- Techniques like dropout, L1/L2 regularization, or early stopping could be introduced to reduce overfitting.
Model Complexity:
- Adjusting the complexity of the model (either simplifying it or making it more complex) based on the performance can help. If overfitting is the issue, simplifying the model or reducing its capacity may help. If underfitting is present, increasing the model’s complexity could be beneficial.
Hyperparameter Tuning:
- Experimenting with different learning rates, batch sizes, or other hyperparameters could lead to better convergence of validation accuracy.
Attention Mechanism Refinement:
- Since the attention mechanism is designed to help the model focus on relevant features, it is crucial to ensure it’s properly implemented and tuned. Considering different types of attention mechanisms or adjusting how the attention is applied could yield better results.
In conclusion, while the model is learning, further work is needed to improve its generalization of unseen data. Adjustments in the model’s architecture, training process, or data preparation might be necessary for better performance.
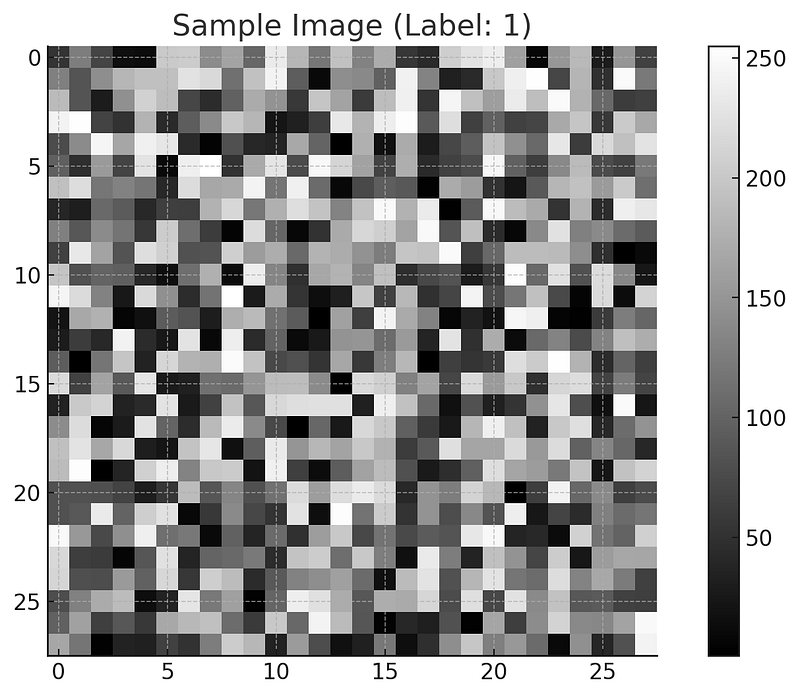
Here’s a sample image from a synthetic dataset similar to the type that could be used for training a neural network with attention mechanisms.
import numpy as np
import matplotlib.pyplot as plt
# Since we don't have the actual synthetic data used, we will create a new sample.
def generate_sample_data(img_size):
x = np.random.rand(img_size, img_size, 1) * 255
y = (x.mean() > 127).astype(int)
return x, y
# Generate a sample image and label
img_size = 28 # As per the previously discussed synthetic data generation
sample_image, sample_label = generate_sample_data(img_size)
# Plot the sample image
plt.imshow(sample_image[:, :, 0], cmap='gray')
plt.title(f"Sample Image (Label: {sample_label})")
plt.colorbar()
plt.show()The grayscale intensities are randomly generated, and the label for this sample indicates that this image's mean pixel intensity is greater than 127. This simplistic approach to labeling is based on a threshold and provides a straightforward binary classification task.
Conclusion
Attention mechanisms in vision represent a significant leap forward in computer vision. They have enabled models to process visual information more efficiently and effectively, leading to advancements in various applications. For practitioners, understanding and implementing these mechanisms correctly is critical to leveraging their full potential. As the field evolves, the ongoing research and development in attention mechanisms will undoubtedly unveil new possibilities and applications, further solidifying their importance in computer vision.
As we delve into the fascinating realm of attention mechanisms in computer vision, I invite you to share your insights and experiences. How do you envision the future of visual data processing with the integration of attention mechanisms? Your thoughts and ideas can spark engaging discussions and pave the way for innovative solutions in this dynamic field. Feel free to comment below, and let’s explore together!



