
Fixing Automatic Speech Recognition (ASR) with NLU
Why doesn’t speech recognition operate at human-levels?
Didn’t we have a revolution in artificial intelligence (AI) with machine learning (ML) and deep learning (DL) in 2012 that has improved AI since then?
Automatic Speech Recognition (ASR), or just ‘speech rec’, remains a somewhat useful feature, with the tech giants bringing the best of ML / DL technology to us. But it is lacking in some obvious ways that holds back adoption of this key technology.
Often, even when the spoken words are transcribed correctly, the selection of action fails due to lack of Natural Language Understanding (NLU). But today, we’ll focus on ASR specifically. ASR is needed for AI applications such as PAT’s Next Generation Technology that gathers user requirements — an approach that would be ideal with a working voice interface.
Who doesn’t want to control a device with their voice?
“the underlying ASR science needs to be updated to incorporate meaning from NLU”
Today, let’s consider an interaction with Apple Siri to highlight how a world-best solution is still found wanting. I’ll show you why the same underlying science for meaning-based NLU is necessary to enable a step-up in speech recognition.
History
“Every time I fire a linguist, the performance of our speech recognition system goes up.”
is a quote often attributed to Fred Jelinek in the 1980s. And my conclusion in 2015 was: “The battle was won, but the war for humanlike accuracy was lost.”
Since the early statistical models were proposed in the 1970s, human-like emulation of language is excluded, mainly by excluding NLU in the process. ASR systems statistically determine word recognition by sequence alone, not meaning or phrases. At its core, the engineering design needs to change from what was a reasonable investment in the 1980s — where NLU was deemed impossible — to one it can solve the problems of ASR properly.
The statistical models implemented are ineffective at detecting words from the sequence of sounds. Some parts of ASR are effective with statistics, while others, like determining from a choice of words or phrases which is intended, are not.
Word sequences are not statistical, of course, but relate the meaning of phrases composed to make language.
How Should ASR Work?
I was recently given a quick lesson on the auditory aspects of the brain by the successful scientist and entrepreneur, Lloyd Watts from Neocortix, whose company Audience IPO’d in 2012. They “reverse-engineered the human hearing system and model its processes onto a chip.”
He pointed out to me that Patom Theory was unlike the human audio system. The human brain’s system was more like (from memory) a perfectly designed processing system, where each element in the process from sound input to output was addressed with engineered processes.
Given that and accepting it as fact since Patom Theory is primarily concerned with recognition (store, match and use patterns…), not transduction (converting sensory input), ASR should be split between the recognition of input sound, phone recognition to phoneme recognition to syllable recognition to potential word recognition (words being a sequence of syllables making up an auditory sign in the semiotics science) to fixed expressions (fixed word sequences that cannot be changed without losing their meaning, like ‘The Wizard of Oz’).
Ultimately, ASR should mimic the human language acquisition model, in which phonemes are learned through experience, and errors in recognition are clarified through questioning. But that’s getting ahead of ourselves.
Let’s compare how ASR today works, to see where NLU should fit.
How Does ASR Work?
The term we use in engineering is often ‘stack’ to refer to a sequence of processing steps that combine to solve a problem.
The stack in ASR has been consistent since the 1970s, although possibly compressed into a single step in the most recent implementations. {Ouch, that’s harder to fix!}
The parts are roughly (per the CMU Sphinx open-source concepts):
- an acoustic model (acoustic properties)
- a phonetic dictionary (mapping words from phones)
- a language model (restricting word search — which words follow other words)
If technology can accurately determine the phone/phoneme/syllable sequence, perhaps valid dictionary/encyclopedia/discourse will prove superior to the fully automated, but inaccurate subsequent steps 2 and 3.
A high probability, rhyming word sequence isn’t as good as a word sequence that is meaningful in a sentence!
In a 2018 paper by Google USA, the engineers use “Sequence-to-sequence models” and collapse those three elements into a single artificial neural network in competition against the “current state-of-the-art, HMM-based neural network acoustic models, which are combined with a separate PM and LM in a conventional system.” (PM being the pronunciation model and LM the language model)

The Google paper shows WER (Word-error rates) between 4% and 10%. We will come back to this because it excludes most useful applications.
PAT’s 2014 experience
In 2014, PAT was experimenting with ASR, using a Microsoft tool inside Visual Studio and also a tool from Nuance. The bottom line of those experiments was that narrowing down the possible responses in advance made the system reasonably accurate. Using the ‘full dictation model’, errors were prohibitive, but if only a few possible words were enabled, the system was pretty good.
One of the systems allowed access to the most probable choices. I think it provided the five top hits. The trouble was, these were the output of the language model — sequences of words. And in case after case, all 5 possible interpretations excluded the correct one. That meant we couldn’t improve on the output: the seam into the stack was too late.
If you had a few valid choices for the recognized text, you could check which made sense in English first, as a simple way of improving the results. Another way (the human-level model) would include the context of utterance (CoU) to align what makes sense in the current conversation — the unambiguous choice.
The point is that back in 2014 the technology was optimised for statistical prediction of word sequence, and didn’t cater to the use of NLU. Nothing has changed in the model used, and compressing all the elements into a single black box only limits future progress.
Fixing ASR with NLU (how people speak and converse)
When you hear: “Can you ge@#$% me a sandwich” a person may say “Do what with a sandwich?” or “Sorry, I missed a word. Can I what?” Today’s systems seem to understand nothing, and recognize nothing if not the whole thing, requiring the sentence to be repeated in full.
That’s awful. It also is confusing, since a long command can be hard to remember after you spoke it. And then you lose your ‘train of thought’ for your subsequent requests.
Why don’t our machines prompt us when they don’t understand a word in a sentence? Presumably, the system doesn’t support it. You put sound in one end, and probable strings of words comes out the other end. When the stack is in the cloud, application consumers don’t have access to anything in the ‘service’ and so the user is asked to: “please repeat that”.
In my language analysis, you can see that only 66 words comprise 50% of speech, and 2000 words is roughly 80% of a language. Soooo… what’s the other 20%?
Well, that’s the referents in language, the things we refer to. The top 2000 words covers the language, but the last 20% we learn on the fly, if we don’t already know them. The remaining words cover people, places, product names, company names, street names, country names and so on.
Those are typically learned on-the-fly when we first encounter them, with clarifying questions like: “Coke? What’s Coke?” The answer populates our knowledge — e.g. a carbonated, sugary black drink. These specific referents simplify our speech. That’s why we ask for a ‘coke’ if we know it, rather than a ‘black sugary carbonated drink.’
Let’s take a typical name in Australia, because I recently wanted to use it there. How does Apple Siri handles my dictation about the road I want to walk on? The road is called Wallumatta (a name from The Wallumettagal Aboriginal tribe).
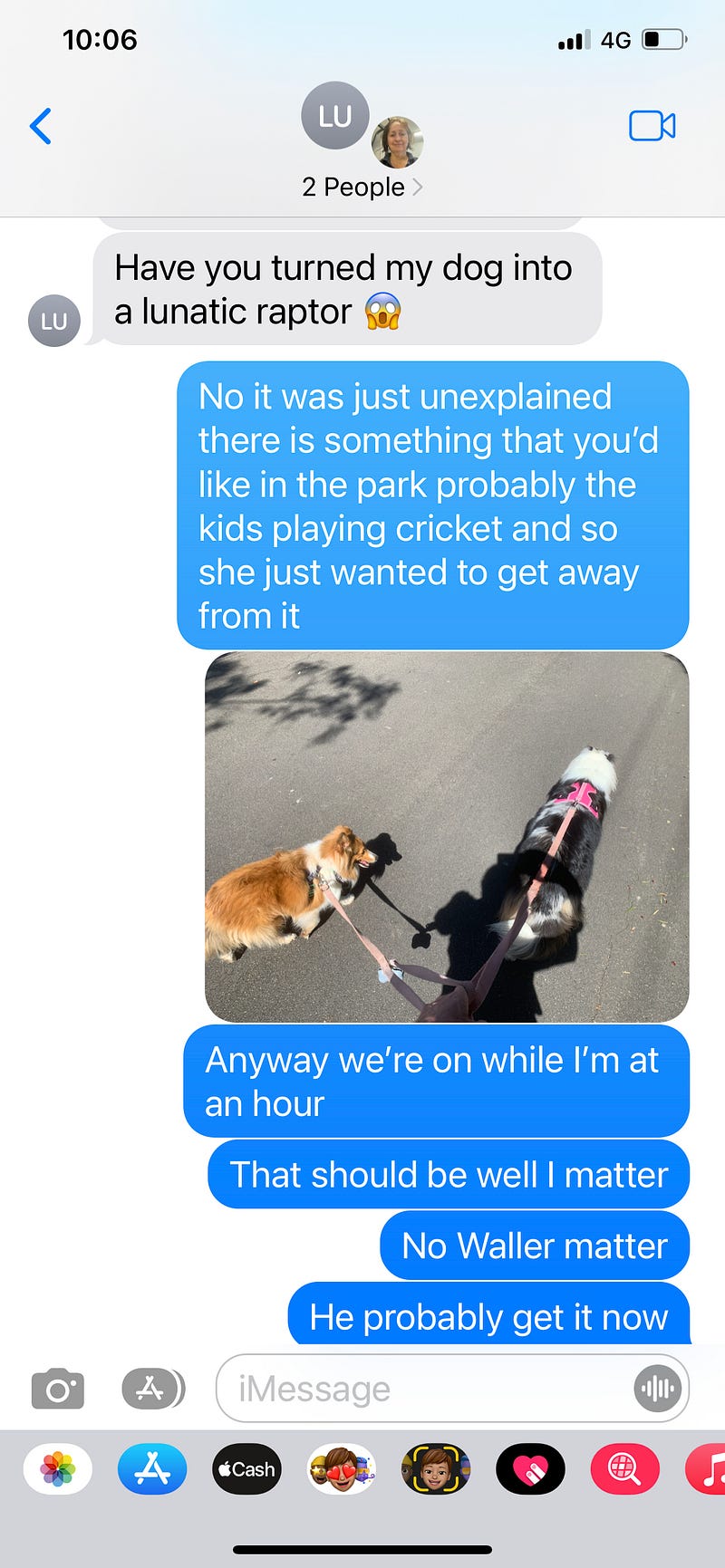
Attempt 1: Intended dialog:
Compare the statement with the text typed (in brackets).
- Anyway, we’re on Wallumatta now. (Anyway we’re on while I’m at an hour)
- That should be Wallumatta (That should be well I matter)
- No Wallumatta (No Waller matter)
- You probably get it now (He probably get it now)
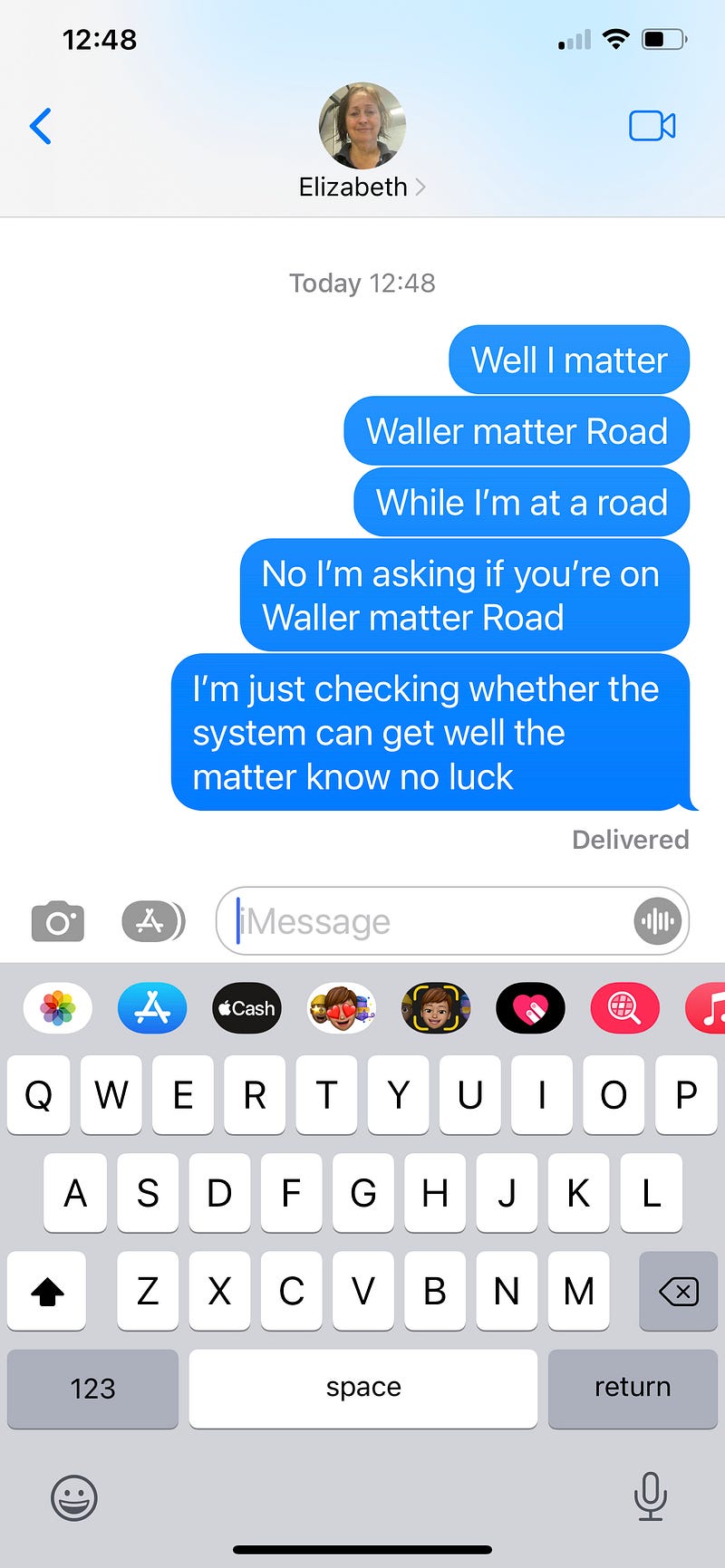
Attempt 2: Intended dialog a few days later:
- Wallumatta. (Well I matter)
- Wallumatta Road (Waller matter Road)
- Wallumatta Road (While I’m at a road)
- No, I’m asking if you’re on Wallumatta Road (No I’m asking if you’re on Waller matter Road)
- I’m just checking whether the system can get Wallumatta. No. No luck. (I’m just checking whether the system can get well the matter know no luck)
Dictation here is better than in 2014, that’s for sure. But it isn’t approaching human-level recognition, since some of the phrases returned aren’t English.
In “I’m just checking whether the system can get well the matter know no luck” English doesn’t make sense with, for example, ‘the system can get well the matter know’. It also doesn’t seem to know Wallumatta as a word, despite my walking down it at the time. My “no, no luck” was also set off with long pauses, but they were just rendered in sequence as “know no luck.”
What is broken? The recognition of words is terrible, while the phoneme sequences are good, giving us nicely rhyming guesses.
Is this good enough to leave as the best solution for the next 10, 20 or 30 years?
A Better, Incremental Design
Assuming we want to improve ASR, NLU can come to the rescue. The basic 2000 words often seems to be pretty good, but the lack of human-like error correction is maddening, as is the preference to chose the wrong words that are more probable.
As I say, ASR has hit a wall with its accuracy. Its future potential without a design change is limited. As Gary Marcus points out in relation to the technology underlying ASR in many cases (DL): deep learning has hit a wall.
ASR has hit the wall not because of DL, but because the underlying scientific model assumes languages are word sequences that can be modelled statistically. That’s too simple and we should all know it.
Natural Language is not sequential, but instead is composed of sequences of embedded phrases. As a result, a sequential system based only of word sequence probability is too small in scale to be effective at human language (for example, data training sizes of, say 10¹² is miniscule compared with the motion phrases of English alone, at roughly 10³⁰⁰⁰.
Step 1: Add error correction
A better software “seam” is needed. Receiving the wrong word sequence alone isn’t good enough. A way to access the result to validate the system is potentially far more robust.
This probably breaks the Tech Giant business model of providing an end-to-end service, but allowing an NLU engine access to check the most probable meanings or — better still — to check words that are allowed from a phoneme sequence would allow incremental improvement.
Error correction would identify an error, like ‘well-the-matter-know’ and prompt with: “What’s well the matter know?” It is “Wallumatta”.
Iterative clarifications would be better for user. This enables the system to also update itself, ideally introducing a semiotics implementation rather than just another data-driven solution per language.
Step 2: Add NLU name resolution, or integrated Named Entity Resolution
By adding meaning validation, errors like ‘well-the-matter-know’ can be clarified. Since that sequence isn’t English, perhaps at that point an error is flagged, and Named Entities are checked. They could include your current location using the existing context capabilities.
Ideally, the CoU is retained for full NLU compatibility.
Of course this introduces a number of new moving parts to what is otherwise a black-box, but if our goal is to use speech as a key component of the Next Generation of Virtual Agents, a step-up is urgently required from ASR.
Summary
The WER in ASR systems is 4–10% in the referenced Google paper above. That level may be good for benchmarks against other systems, but human-level interaction can’t cope with such a high error rate. That’s one parole wrong in most sentences (parole means word — my joke error). It is unusable in my opinion and is stopping adoption, particularly when there is no error correction without full repetition.
Today’s technology has improved since the 1980s, but remains inadequate for the main applications that people are waiting for, as promised in Hollywood productions for a long time. The HAL/9000 computer in Kubrick’s movie 2001: a space odyssey not only conversed with its crew, it also read lips! I want one of those (without the psychopathic tendencies).
It may take a little while to get there, but as our NLU systems now have capabilities to improve language understanding per PATs strategy, so too should our ASR capabilities be improved.
The promise of such an improvement remains in the imagination of us all and given the right, funded projects, could return benefits quickly.





