
Fine-Tuning Large Language Models: A Guide into Distributed Parallel Training with DeepSpeed, Ray, and Instruction Following
Path to Open-source LLMs
It would be hard to imagine that anyone immersed in the AI community these days would be unfamiliar with Large Language Models (LLMs). The astounding capabilities of OpenAI’s GPTs, mirroring human-like reasoning, have been capturing the world’s attention and fostering great anticipation for what comes next.
Yet, this achievement doesn’t come without its share of concerns. As these generative models continue to evolve, so does the public’s apprehension about the potential for biased and toxic content that could emanate from them. This concern is further compounded by the fact that closed-source models like GPTs pose a challenge for researchers and machine learning practitioners aiming to scrutinize and investigate the origin of datasets that fuel the training of these models.
Nevertheless, amidst these challenges, the vibrant spirit of the open-source community has been instrumental in spurring the growth of GPT-like models. The past few months have seen a surge of innovation, buoyed by the dynamism and collaborative ethos of this community.
When you take a look at the LLMs leaderboard on HuggingFace, you’ll probably be amazed by the vast number and variety of models the AI community has contributed. These are products of collective effort, showcasing the collaborative genius of academic research institutions, startups, and large corporations alike.
Memory Challenge
Navigating the terrain of training a Large Language Model (LLM) can indeed pose significant challenges due to the substantial hardware memory consumption requirements. OpenAI’s journey in developing the GPT series provides a fascinating glimpse into this process. It’s reported by a team consisting of researchers from Stanford University, NVIDIA, and Microsoft Research that to reach the current state of the art, it took not just weeks but over a month of rigorous training and an army of hundreds of NVIDIA A100 GPUs. For businesses without a robust technological arsenal or those constrained by resources, this represents a considerable hurdle.
However, it’s worth noting that these challenges have not gone unnoticed. The AI community is actively exploring ways to democratize access and make the process of developing LLMs more accessible. With innovative ideas and solutions steadily emerging, we can look forward to a future where these models become a readily available tool, within reach of businesses of all sizes and industries. As we continue to push the boundaries of AI, the hope is that every business entity, regardless of their resources, will have the opportunity to harness the power of LLMs and drive their own digital transformation journeys.
Breakthrough
In these pioneering times, extraordinary steps are certainly the need of the moment. An example of this is a research team from Stanford University, who took the world by storm with their innovative approach to fine-tuning Meta’s LLaMA model. The team curated a dataset comprising approximately 52K question-and-answer pairs.
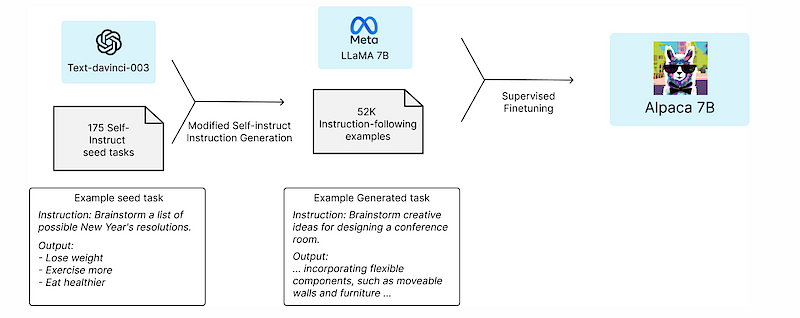
Initially, this dataset was seeded with question and answer pairs annotated by humans, and then supplemented with similar pairs generated by GPT text-davinci-003 models. Using this rich and diverse dataset, they start fine-tuning the LLaMA model. Much to everyone’s astonishment and at a fraction of the cost, the fine-tuned model demonstrated performance that was more than 90% similar to the GPT text-davinci-003 model in certain areas.
This groundbreaking work seemed to set off a ripple effect throughout the AI community. Shortly after its release, multiple teams followed suit, reporting and open-sourcing models with similar tuning approaches. Standout mentions include the Dolly models from Databricks and the Vicuna model from a research group at Berkeley University.
This wave of innovation has catalyzed a global rush among companies, each contending for creating their own version of GPT. It’s an exciting era, with this accelerated pace of development offering glimpses into the immense possibilities that lie ahead. It is indeed a thrilling time to be part of this rapidly evolving landscape.
Although fine-tuning Large Language Models using instruction following is less memory-intensive than training them from scratch, distributed parallel training is still necessary to help manage memory usage effectively.
DeepSpeed
Deep learning optimization libraries play an indispensable role in making distributed parallel training and inference LLMs possible. Typically, these libraries (e.g. DeepSpeed) consist of three core components: APIs, runtime, and ops.
To understand this better, let’s dive a bit deeper into the process of training deep learning models. It involves a computation (updating) of parameters through a sequence of forward and backward passes across different layers of the neurons using batched data. This intricate process is where the model learns and improves over time.
Next, let’s scrutinize the memory consumption for a typical training system. Consider, for example, a 1.5 billion parameter GPT-2 model. In 16-bit precision (occupying 2 bytes), the model requires a whopping 3GB of memory just for its weights (or parameters). However, this model can’t be trained on a single GPU with 16GB memory using popular deep learning platforms such as TensorFlow or PyTorch. This naturally leads us to question: where does all the memory go?
To comprehend this, it’s crucial to realize that during model training, the model states are the main contributors to memory usage. These include tensors composed of optimizer states, gradients, and parameters. In addition to these model states, there are activations, temporary buffers, and fragmented memory, collectively known as residual states, that consume the remaining memory.
Let’s delve into the specifics of these two aspects of memory consumption — model states and residual states — to get a clearer understanding of the process and the challenges involved. This deeper insight can potentially open up new avenues for optimizing memory usage and improving the efficiency of the deep learning model training process.
Model States: Optimizer States, Gradients and Parameters
A significant portion of device memory is consumed by model states during training. Take Adam, a widely-used optimizer in deep learning training, as an example. Adam requires storing two optimizer states: i) the time-averaged momentum and ii) the variance of the gradients, to compute the updates. Therefore, to train a model with Adam, sufficient memory is needed to hold a copy of both the momentum and variance of the gradients. Furthermore, adequate memory is also needed to store the gradients and the weights themselves. Of these three types of parameter-related tensors, the optimizer states generally consume the most memory, especially when mixed-precision training is implemented.
Mixed-Precision Training
The latest way to train big models using the newest NVIDIA graphics cards uses a method known as mixed-precision (FP16/32) training. FP32 is called full precision (4 bytes), while FP16 are referred to as half-precision (2 bytes). Here, important model components like parameters and activations are stored as FP16. This storage method allows these graphics cards to process large amounts of data very quickly.
During this training process, both the forward and backward steps are done using FP16 weights and activations. However, to properly calculate and apply the updates at the end of the backward step, the mixed-precision optimizer keeps an FP32 copy of the parameters and all other states used in the optimizer.
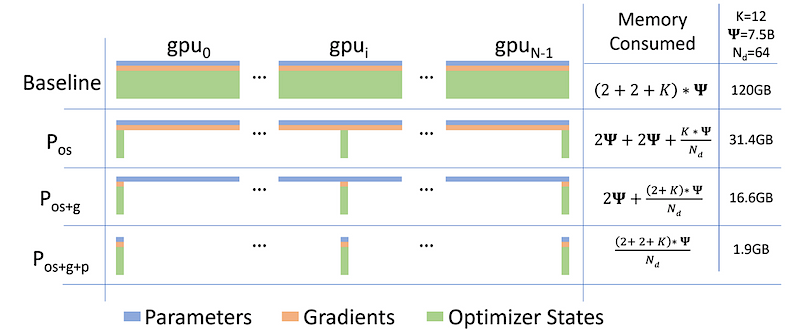
Let’s look at an example from one of the DeepSpeed Papers when using the Adam optimizer. When using mixed-precision training with a model that has Ψ parameters, the memory needs to hold an FP16 copy of both the parameters and gradients (which need 2Ψ and 2Ψ bytes of space each), along with the optimizer states, which are an FP32 copy of the parameters, momentum, and variance (each requiring 4Ψ, 4Ψ, and 4Ψ bytes of space).
If we denote the extra memory needed to store the optimizer states as K, with Adam, K equals 12. This means the total memory requirement becomes 2Ψ + 2Ψ + KΨ = 16Ψ bytes. In the case of a model like GPT-2 with 1.5 billion parameters, this equates to 24 GB of memory. This is a significant jump from the mere 3 GB required just to hold the FP16 parameters alone.
Residual Memory Consumption
During the training of large AI models, activations, or the outputs of different layers in the model, eat up a significant amount of memory. For instance, the training of a model like GPT-2, which has 1.5 billion parameters, with a sequence length of 1,000 and batch size of 32, consumes roughly 60 GB of memory. To cut down this large memory requirement, there’s a trick called activation checkpointing. This technique reduces the memory used by activations to about a square root of the total activations, but at the cost of having to do about 33% of the calculations again. This could bring down the memory consumption of this model to around 8 GB.
However, even with activation checkpointing, memory consumption can still skyrocket for bigger models. For example, a model similar to GPT3.5, but with a 100 billion parameters, needs about 60 GB of memory for a batch size of 32, even with activation checkpointing.
Temporary buffers are another memory eater. They store intermediate results during model training. Sometimes, all the gradients, or changes calculated for each parameter in the model, are bundled together into a single buffer before an operation is applied to improve speed. This “fused” buffer can be a larger tensor depending on the operation. So, for big models, these temporary buffer sizes can be quite large. For example, a model with 1.5 billion parameters would need a 6 GB memory buffer.
Then there’s memory fragmentation. This is like a messy room where things are strewn about. There may be plenty of space in total, but if there isn’t enough clean, contiguous space to place something large, you’re stuck. The same happens in memory management. When training very large models, memory can get fragmented, and even if there’s lots of memory left, you could run into a roadblock if there isn’t enough contiguous memory to fit in a request. In some extreme cases, memory fragmentation can lead to an out-of-memory error despite over 30% of the memory still being free.
In essence, training large models is a memory management puzzle. You need to account for memory consumed by both the model and extra bits like activation and temporary buffers. Tricks like mixed-precision training and activation checkpointing can help manage memory usage. But, you also have to watch out for hidden traps like memory fragmentation, which might cause disruptions in the training process. With a good understanding of these factors, you can better navigate the challenge of training large deep learning models.
ZeRO
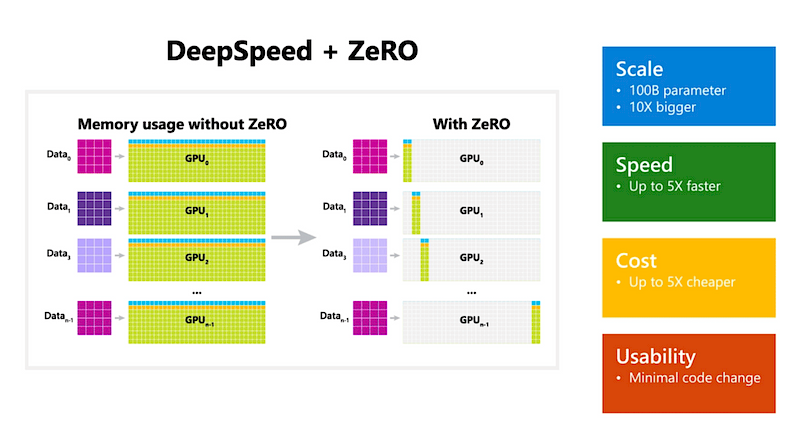
Model parallelism is a technique to tackle the size of LLMs, allowing to train such models at scale. If a model can fit into the memory of a device for training, we use a method called data parallelism (or DP) to train the model on multiple devices at the same time.
In DP, the model parameters are copied onto each device. For each step, a small batch of data is divided equally among all the DP processes. So, each process works on a different subset of data samples, running the forward and backward propagation. Then, each process uses the average of the gradients from all processes to update its own model locally.
But there’s a catch. The traditional DP approach duplicates the model’s states on each device, which can take up a lot of memory. Simple data parallelism (DP) doesn’t decrease the memory used per device, so it can run out of memory for models with more than 1.5 billion parameters on the graphics cards that have 16 GB of memory (Remember the Adam example from the mixed-precision training section above).
To tackle these memory challenges, DeepSpeed implements a three-stage strategy known as ZeRO (Zero Redundancy Optimizer) for managing memory.
- Optimizer State Partitioning (ZeRO Stage 1): This initial stage involves sharding (partitioning) optimizer states across data parallel workers or GPUs. Instead of every GPU holding a complete set of optimizer states, each one only stores a fraction, thus reducing the overall memory requirements.
- Gradient Partitioning (ZeRO Stage 2): Building upon the first stage, ZeRO stage 2 also partitions gradients across data parallel workers or GPUs. This means that each GPU holds only a portion of the gradients, further decreasing the memory footprint.
- Parameter Partitioning (ZeRO Stage 3): This final stage takes things a step further by partitioning not only the optimizer states and gradients but also the model parameters across data parallel workers or GPUs. Now, each GPU holds only a fraction of the model parameters, which allows even larger models to fit within a GPU machine.
In addition to these stages, DeepSpeed also introduces two offloading strategies, offering a lower GPU memory usage in exchange for a slower model training speed:
a. Optimizer Offload: Building upon ZeRO Stage 2, this strategy offloads the gradients and optimizer states to CPU or disk. This effectively frees up the GPU memory for other computations, providing further reduction in memory usage.
b. Param Offload: This strategy builds on top of ZeRO Stage 3 by offloading the model parameters to CPU or disk. Similar to the optimizer offload, this approach provides an additional reduction in memory requirements, allowing even larger models to be trained with the available resources.
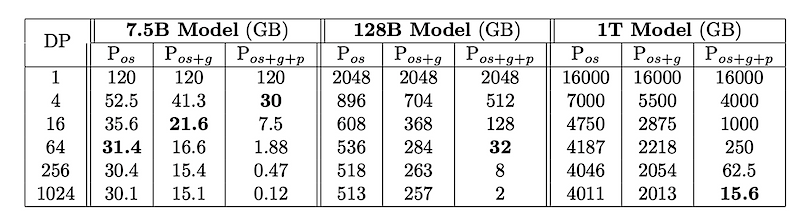
To put it simply, let’s say we’re looking at models of various sizes, from smaller ones with 7.5 billion parameters to massive ones with 1 trillion parameters. We can measure how much memory, in GB, these models use.
We have different stages of partitioning strategies, such as “os” (which stands for optimizer state), “os+g” (optimizer state plus gradients), and “os+g+p” (optimizer state plus gradients plus parameters). When we combine these strategies with data parallelism (or DP), we see a significant reduction in memory use.
In other words, these strategies help to cut down significant amount of memory the models need, making it more manageable to work with larger models
Through these innovative memory management strategies, DeepSpeed effectively navigates the challenges of memory consumption, enabling the training of larger and more complex models.
Distributed Training with Ray
To make DeepSpeed’s parallel training work on a larger scale, our infrastructure team uses Ray’s distributed architecture. Ray helps to distribute the work across multiple workers (nodes) in a Ray cluster. For more details, check out the upcoming Sage AI’s blog post on KubeRay.
Ray serves as a unified, open-source framework that empowers you to effortlessly scale your AI and Python applications, particularly in the realm of machine learning. It acts as a compute layer for parallel processing, freeing you from the need to be an expert in distributed systems. Ray simplifies the complexities associated with running your individual and comprehensive machine learning workflows in a distributed manner by offering a range of features.
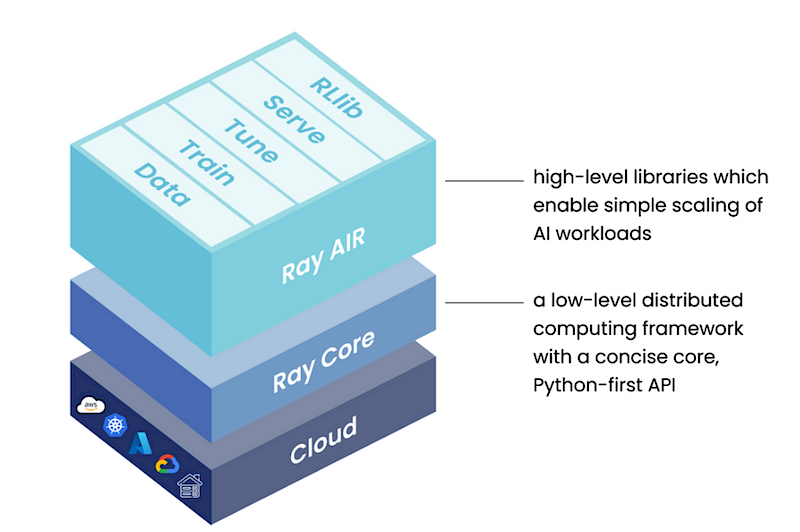
Notebook Implementation
[Update 10/20/23: Ray 2.7.0 introduces Ray Train to consolidate many Ray AIR namespaces. The migration of the demo notebook is shared here.]
In this example, we will showcase how to use the Ray AIR for Dolly v2 fine-tuning. Dolly v2 is based on the EleutherAI pythia model. This particular model has 3 billion parameters.
We will use Ray AIR (with the HuggingFace’s Transformers integration) and a pre-trained model from Hugging Face hub.
Setup Ray
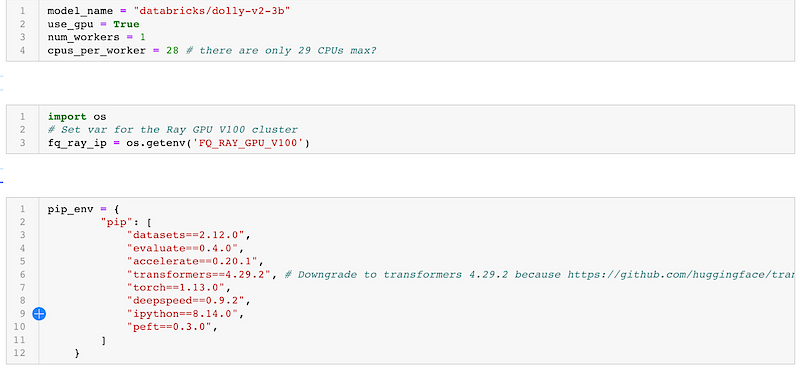
First, let’s set some global variables. For illustrative purpose, We will use 1 worker, each being assigned 1 GPU and 28 CPUs.
We will use ray.init() to initialize a cluster. The cluster is provisioned by our infrastructure team using the KubeRay operator, orchestrating training tasks on Kubernetes (k8s).
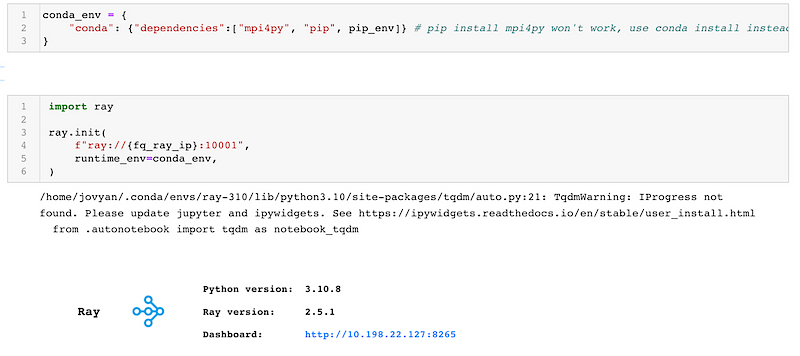
We define a runtime environment to ensure that the Ray workers have access to all the necessary packages.
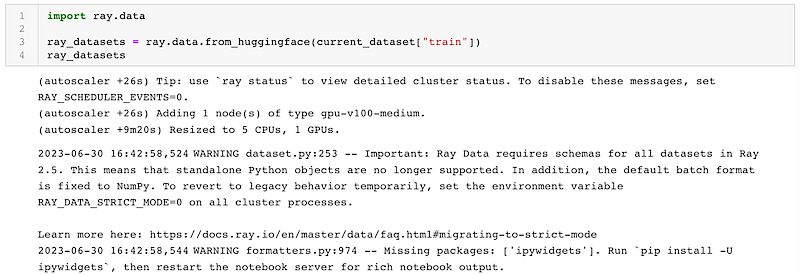
Loading the dataset
We will be fine-tuning the model on the alpaca clean dataset comprised of 52,000 lines of question and answer pairs.
Instruction Fine-tuning the model

We can now set up Ray AIR’s TransformersTrainer to do the distributed fine-tuning of the model. To make this happen, we create a function called trainer_init_per_worker, which wraps a Hugging Face’s Trainer object. This Trainer will be distributed by Ray using a technique called Distributed Data Parallelism (DDP) (i.e. one of PyTorch Distributed backends under the hood). What this means is that each worker gets its own copy of the model but works on different data. When each step is over, all the workers will sync up their learnings.
Because Dolly V2 is a big model, it might not fit on smaller graphics cards (ones with 16 GB GRAM or less). To tackle this issue, we can use the DeepSpeed library. DeepSpeed helps to streamline the training process and lets us, among other things, partition the optimizer states and gradient, which brings down the use of GRAM. Moreover, DeepSpeed’s ZeRO Stage 3 feature lets us load large models without running out of memory by offloading model parameters to CPUs and partitioning model parameters to worker GPUs.

HuggingFace Transformers and Ray AIR’s integration class object (TransformersTrainer) allow you to easily configure and use DDP and DeepSpeed conveniently. All you need to do is specify the DeepSpeed configuration in the TrainingArguments object.
Conclusion
Through this blog post, we’ve walked through the process of fine-tuning a 3 billion parameter Dolly v2 model using DeepSpeed, Ray, and instruction following. To the best of our knowledge, this demonstration is the first use of instruction following fine-tuning for LLM in a distributed cluster framework.
At Sage AI, we’re committed to being an active part of the open-source AI community. We derive immense insights from the community (e.g. Fine-tuning LLMs with ray) and consistently strive to contribute back. We firmly believe that fostering transparency regarding the datasets used to train LLMs can enhance our understanding and help mitigate the risks of generating biased or harmful outputs. To that end, we are working to contribute our solution to the Ray open source community (our code in the notebook here).
If you’re interested in building similar applications or responsibly leveraging generative AI for financial applications, don’t hesitate to get in touch. We’re always ready to explore new frontiers in AI and machine learning. Here’s to creating, learning, and building the future of AI together!




