
Fine-Tuning GPT-3.5 RAG Pipeline with GPT-4 Training Data
NVIDIA SEC 10-K filing analysis before and after fine-tuning

OpenAI announced on August 22, 2023, that fine-tuning for GPT-3.5 Turbo is now available. This update allows developers to customize models that perform better for their use cases and run these custom models at scale.
Hours later that same day, LlamaIndex announced the release 0.8.7, with the brand new integration of fine-tuning OpenAI gpt-3.5-turbo baked into LlamaIndex already! Guides, notebooks, and blog posts were shared with the open source community immediately following the new release.
In this article, let’s take a close look at this new feature in LlamaIndex by analyzing NVIDIA’s SEC 10-K filing for 2022. We will compare the performance of the base model gpt-3.5-turbo and its fine-tuned model.
RAG vs Fine-Tuning
We’ve been exploring RAG pipelines quite a bit so far. What exactly is fine-tuning? How is it different from RAG? When should you use RAG vs fine-tuning?
There are great resources online on this topic. I came across two great articles that thoroughly analyzed RAG vs fine-tuning. I highly recommend you check them out:
- RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application? by Heiko Hotz.
- AI: RAG vs Fine-tuning — Which Is the Best Tool to Boost Your LLM Application? by Raphael Mansuy.
My main takeaways from those two articles are the following two summary images:
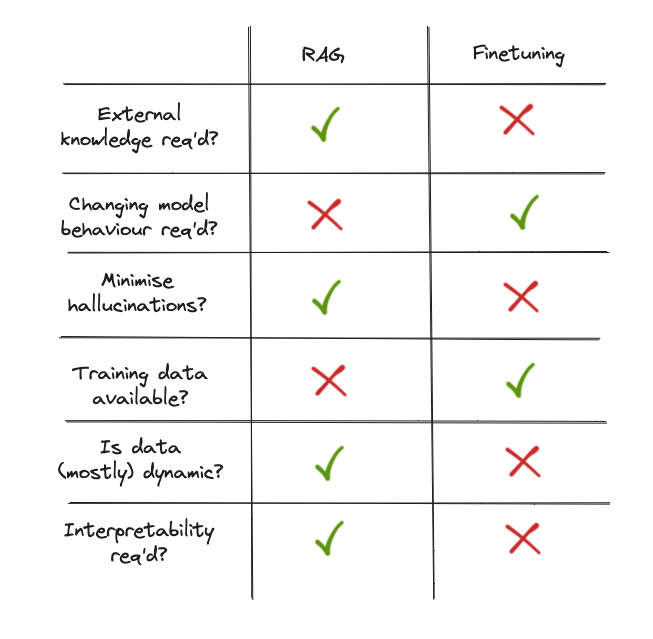
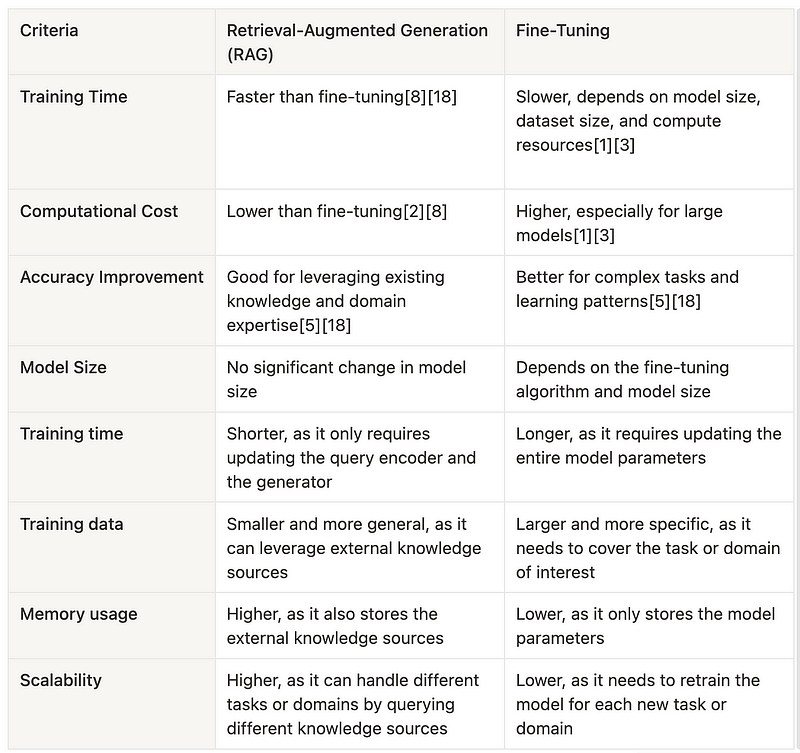
These two images summarize it all, providing us great guidance on choosing the right tool for the right use case.
However, RAG and fine-tuning are not mutually exclusive. It’s perfectly fine to have both applied in the same app in a hybrid approach. Heiko Hotz dived deep into this hybrid approach in his article, with detailed use cases, and came up with the following diagram, which is quite enlightening.
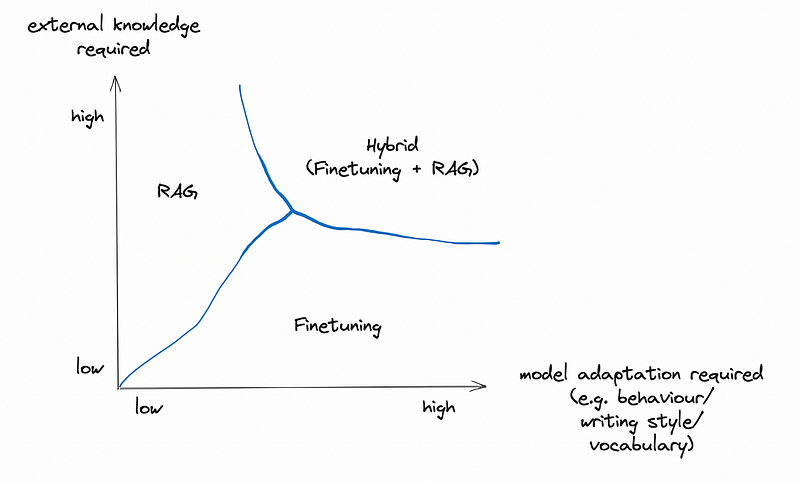
The RAG/Fine-Tuning Hybrid Approach
LlamaIndex provides detailed guide on fine-tuning OpenAI gpt-3.5-turbo in a RAG pipeline. From a high level, the fine-tuning implementation carries out these key tasks described in the diagram (and the legend section below):
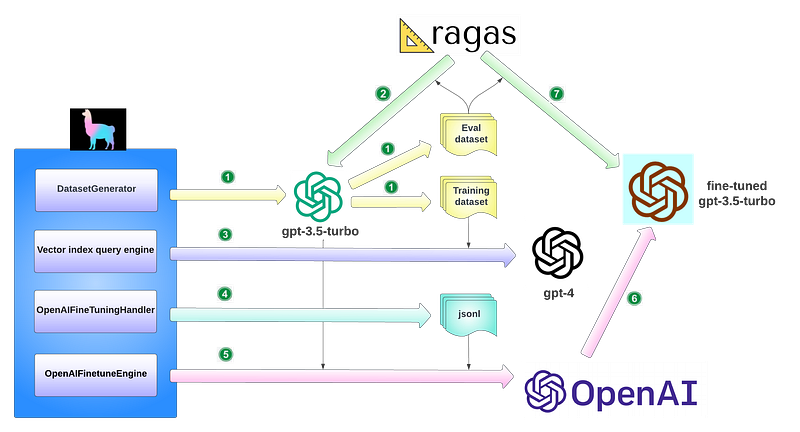
- Data generation automation for both eval dataset and training dataset, using
DatasetGenerator. - Eval for base model gpt-3.5-turbo before fine-tuning, using the eval dataset generated from step 1.
- Construct vector index query engine and call gpt-4 to collect training data based on the training dataset.
- Callback handler
OpenAIFineTuningHandlercollects all messages sent to gpt-4, along with their responses, saves these messages in a.jsonl(JSON-line) format that can be consumed by OpenAI API endpoint for fine-tuning. OpenAIFinetuneEngineis constructed by passing in gpt-3.5-turbo and thejsonlfile generated from step 4, it sends afinetunecall to OpenAI, launching a fine-tuning job request to OpenAI.- OpenAI creates the fine-tuned gpt-3.5-turbo model as per your request.
- Eval for fine-tuned model by using the eval dataset generated from step 1.
Simply put, this fine-tuning integration enables gpt-3.5-turbo to be fine-tuned on gpt-4 training data and output better responses.
Step 2 and 7 are optional as they are merely to evaluate the performance of the base model vs the fine-tuned model.
Now that we understand the high-level implementation steps, let’s take a test drive, and plug in the SEC 10-K filing for NVIDIA for 2022 into LlamaIndex’s guide, walk through the steps. The full notebook is here. Please follow the instructions/comments in the notebook to experiment fine-tuning gpt-3.5-turbo.
A few key highlights:
OpenAIFineTuningHandler
This is a callback handler for OpenAI fine-tuning, mainly to collect all training data messages sent to gpt-4, along with their responses. It then saves these messages in a .jsonl (JSON-line) format that can be consumed by OpenAI’s API endpoint for fine-tuning.
OpenAIFinetuneEngine
The core of this fine-tuning integration lies in OpenAIFinetuneEngine, which takes care of launching a fine-tuning job and getting a fine-tuned model that you can directly plugin to the rest of LlamaIndex workflows.
With OpenAIFinetuneEngine, LlamaIndex brilliantly masks all the implementation details of calling OpenAI APIs for fine-tuning, which is not trivial:
- Prepare your fine-tuning data and convert it into
jsonlformat. - Upload fine-tuning data using OpenAI’s
File.createendpoint and get the file id from the response. - Create a new fine-tuning job by calling OpenAI’s
FineTuningJob.createendpoint. - Wait for the new fine-tuned model to be created, and then use your fine-tuned model.
With OpenAIFinetuneEngine, we can use gpt-4 and OpenAIFineTuningHandler to collect data that we want to train on. The handler then saves fine-tuning events to a jsonl file. With both the gpt-3.5-turbo and the jsonl file, we construct OpenAIFinetuneEngine. This engine then calls finetune, which in turn calls OpenAI API FineTuningJob.create to fine-tune gpt-3.5-turbo based on the training data in the jsonl file. We also use this engine to get the fine-tuned model by calling get_finetuned_model once the fine-tuned model is created.
See the code snippet below, especially the last four lines where OpenAIFinetuneEngine is constructed and does its fine-tuning workload. There is no need for developers to write OpenAI API calls at all. The implementation offered by LlamaIndex is simple, concise, and really pleasant for developers to consume.
from llama_index import ServiceContext
from llama_index.llms import OpenAI
from llama_index.callbacks import OpenAIFineTuningHandler
from llama_index.callbacks import CallbackManager
# use GPT-4 and the OpenAIFineTuningHandler to collect data that we want to train on.
finetuning_handler = OpenAIFineTuningHandler()
callback_manager = CallbackManager([finetuning_handler])
gpt_4_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-4", temperature=0.3),
context_window=2048, # limit the context window artifically to test refine process
callback_manager=callback_manager,
)
# load the training questions, auto generated by DatasetGenerator
questions = []
with open("train_questions.txt", "r") as f:
for line in f:
questions.append(line.strip())
from llama_index import VectorStoreIndex
# create index, query engine, and run query for all questions
index = VectorStoreIndex.from_documents(documents, service_context=gpt_4_context)
query_engine = index.as_query_engine(similarity_top_k=2)
for question in questions:
response = query_engine.query(question)
# save fine-tuning events to jsonl file
finetuning_handler.save_finetuning_events("finetuning_events.jsonl")
from llama_index.finetuning import OpenAIFinetuneEngine
# construct OpenAIFinetuneEngine
finetune_engine = OpenAIFinetuneEngine(
"gpt-3.5-turbo",
"finetuning_events.jsonl"
)
# call finetune, which calls OpenAI API to fine-tune gpt-3.5-turbo based on training data in jsonl file.
finetune_engine.finetune()
# check current job status
finetune_engine.get_current_job()
# get fine-tuned model
ft_llm = finetune_engine.get_finetuned_model(temperature=0.3)Please note, the finetune function takes time, so it is the underlying OpenAI API call for FineTuningJob.create. For the 169-page PDF document I tested with, it took about ten minutes between kicking off finetune on finetune_engine and receiving an email from OpenAI informing me that my new fine-tuning job had completed and the new fine-tuned model had been created for my use. See the email below.
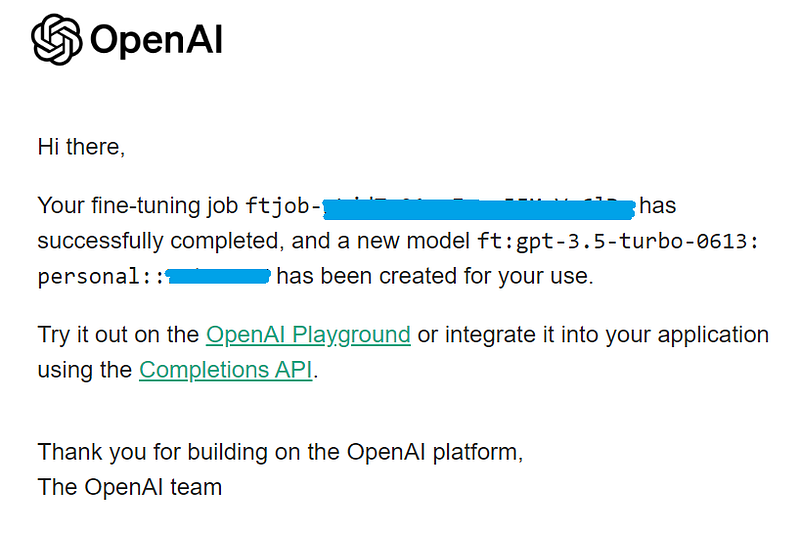
Before you receive that email, if you run get_finetuned_model on the finetune_engine, you will get an error complaining that the job does not have a fine-tuned model id ready yet.
The ragas framework
ragas, short for RAG Assessment, provides tools based on the latest research for evaluating LLM-generated text to give us insights into our RAG pipelines.
ragas measures your pipeline’s performance against different dimensions: faithfulness, answer relevancy, context relevancy, context recall, Aspect Critiques. For this demo app, we will focus on measuring faithfulness and answer relevancy.
- Faithfulness: measures the information consistency of the generated answer against the given context. If any claims are made in the answer that cannot be deduced from context, it is penalized.
- Answer Relevancy: refers to the degree to which a response directly addresses and is appropriate for a given question or context. This does not consider the factuality of the answer but rather penalizes the presence of redundant information or incomplete answers given a question.
Detailed steps to apply ragas in our RAG pipeline are as follows:
- Collect a set of eval questions (min 20, in our case, 40) to form our test dataset.
- Run our pipeline using the test dataset before and after fine-tuning. Each time, record the prompts with the context and generated output.
- Run ragas evaluation for each of them to generate evaluation scores.
- Compare the scores, and we will know how much the fine-tuning has affected our pipelines’ performance.
contexts = []
answers = []
# loop through the questions, run query for each question
for question in questions:
response = query_engine.query(question)
contexts.append([x.node.get_content() for x in response.source_nodes])
answers.append(str(response))
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import answer_relevancy, faithfulness
ds = Dataset.from_dict(
{
"question": questions,
"answer": answers,
"contexts": contexts,
}
)
# call ragas evaluate by passing in dataset, and eval categories
result = evaluate(ds, [answer_relevancy, faithfulness])
print(result)
import pandas as pd
# print result in pandas dataframe so we can examine the question, answer, context, and ragas metrics
pd.set_option('display.max_colwidth', 200)
result.to_pandas()Eval Results
Let’s review the notebook and compare the eval results before and after the fine-tuning.
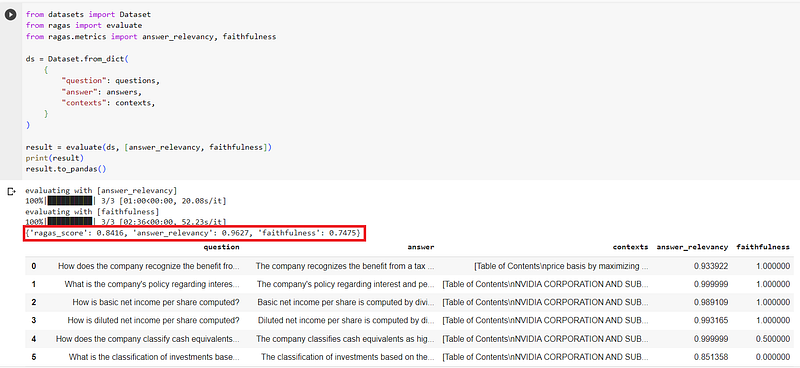
Eval for the base model gpt-3.5-turbo
See the screenshot below. answer_relevancy has a good rating but faithfulness is a bit low.
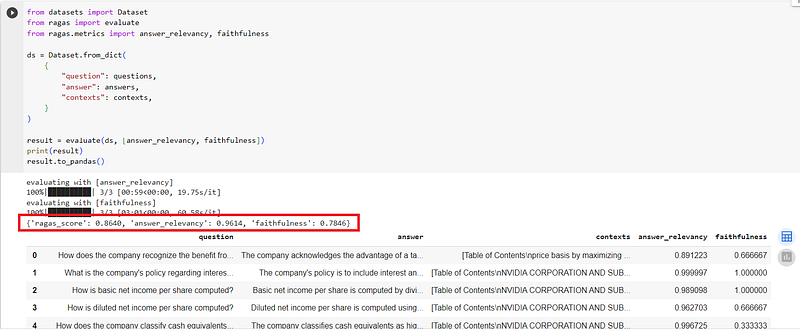
Eval of fine-tuned model
After fine-tuning, the model’s performance slightly improved in the faithfulness category, from 0.7475 to 0.7846, a 4.96% increase.
The eval results inform us that fine-tuning of gpt-3.5-turbo with gpt-4 training data does see improvement. However, I would also like to share a few observations.
A Few Key Observations
Observation #1: fine-tuning a small document resulted in degraded performance after fine-tuning
I initially experimented with a small ten-page PDF file, and I found out that the eval results actually showed the fine-tuned model had degraded performance compared to the base model. I tested two rounds; the detailed eval results were as follows:
- Round #1 base model:
ragas_score: 0.9122,answer_relevancy: 0.9601,faithfulness: 0.8688 - Round #1 fine-tuned model:
ragas_score: 0.8611,answer_relevancy: 0.9380,faithfulness: 0.7958 - Round #2 base model:
ragas_score: 0.9170,answer_relevancy: 0.9614,faithfulness: 0.8765 - Round #2 fine-tuned model:
ragas_score: 0.8891,answer_relevancy: 0.9557,faithfulness: 0.8313
I suspected the small file size may be why the fine-tuned model performed worse than the base model. So, I switched to the 169-page SEC 10-K filing for NVIDIA. I had a good experiment with the above results — the fine-tuned model performed better, a 4.96% increase in the faithfulness category.
Observation #2: Inconsistent eval results for fine-tuned model. The culprit appears to be the data size and the quality of the eval questions
Even though I got the expected eval results for my fine-tuned model for my 169-page doc, I ran a second round of tests on the same eval questions and the same document and discovered the following results:
- Round #2 base model:
ragas_score: 0.8874,answer_relevancy: 0.9623,faithfulness: 0.8233 - Round #2 fine-tuned model:
ragas_score: 0.8218,answer_relevancy: 0.9498,faithfulness: 0.7242
I am puzzled. What could be causing such inconsistency in the eval results? With some research online, I came across this article Challenges in Building Finetuned LLM Models: Quality Finetuning Data Preparation by Amjad Raza, Ph.D.
Data size, in my use case, most likely is one of the root causes of the inconsistent fine-tuning eval results. Per Dr. Raza, “To get you started, at least 1,000 samples of the finetuning Data set are needed.” I definitely did not have that much fine-tuning data set for my demo app.
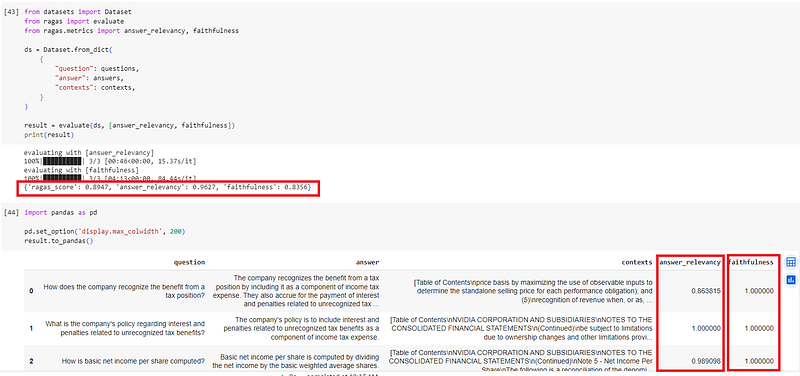
The other root cause most likely lies in the data quality, more specifically, quality of the eval questions. I printed out the eval results into a panda dataframe, which lists the question, answer, context, answer_relevancy, and faithfulness for each question. You can see a sample screenshot with a few sample records below.
By eyeballing it, I noticed four questions scored 0 in the faithfulness category for the eval for the base and fine-tuned models. Drilling into them showed the answers stated that no context was provided in the document. Those four questions are of poor quality, so I removed them from eval_questions.txt, reuploaded the file to my notebook, reran the evals, and got better results:
- Base model eval:
ragas_score: 0.8947,answer_relevancy: 0.9627,faithfulness: 0.8356
- Fine-tuned model eval:
ragas_score: 0.9207,answer_relevancy: 0.9596,faithfulness: 0.8847
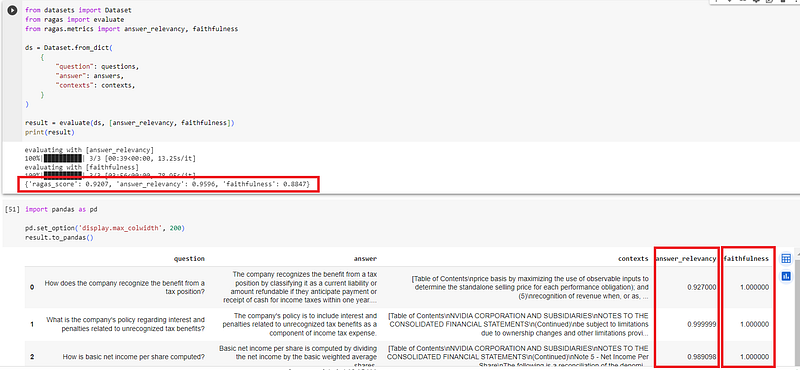
The faithfulness category bumped up 5.9% for the fine-tuned model after cleaning up those four questions of poor quality.
The eval questions and training data will need more tweaks to ensure sound data quality. This is indeed a very interesting area to explore.
Observation #3: be aware of the cost of fine-tuning
A fine-tuned gpt-3.5-turbo model costs higher than the base model. Specifically, be aware of the cost difference among the base model, fine-tuned model, and gpt-4:
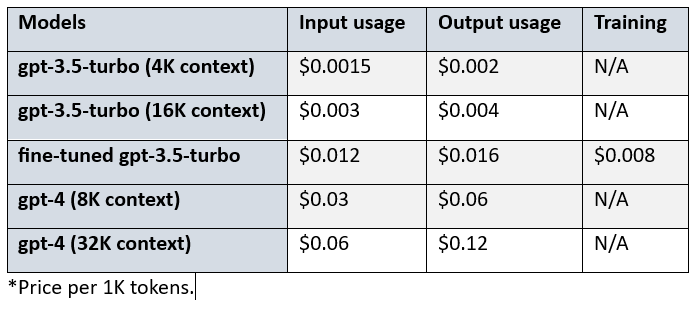
Comparing gpt-3.5-turbo (16K context), fine-tuned gpt-3.5-turbo, and gpt-4 (8K context), we realize that:
- fine-tuned gpt-3.5-turbo is four times the cost of the base model for both input and output usage.
- gpt-4 is 2.5 times the cost of the fine-tuned model for the input usage and 3.75 times for the output usage.
- gpt-4 is 10 times the cost of the base model for the input usage and 15 times for the output usage.
- using fine-tuned model incurs an additional cost of $0.008/1K tokens.
Summary
We explored LlamaIndex’s new integration of OpenAI fine-tuning of gpt-3.5-turbo. We walked through a RAG pipeline of NVIDIA SEC 10-K filing analysis, measured the base model performance, and then used gpt-4 to collect training data, create OpenAIFinetuneEngine, which carries the core logic of the fine-tuning integration with OpenAI.
We created a new fine-tuned model, measured its performance, and compared it with the base model. We also briefly looked at the ragas framework for evals.
We shared a few key observations through this exercise. It ultimately boils down to the importance of data quality and data quantity in fine-tuning a model to achieve better performance than the base model. More will be studied and uncovered.
Leave me a comment if you have run into similar issues in your fine-tuning experience. What were some ways you solved these challenges?
My source code for this article can be found in my GitHub repo and Colab notebook.
Happy coding!
References
- GPT-3.5 Turbo fine-tuning and API updates
- RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application?
- AI: RAG vs Fine-tuning — Which Is the Best Tool to Boost Your LLM Application?
- Fine Tuning GPT-3.5-Turbo
- Evaluating LlamaIndex
- The ragas framework
- Challenges in Building Finetuned LLM Models: Quality Finetuning Data Preparation
- OpenAI Pricing




