
Fine Tuning a T5 transformer for any Summarization Task
Doing cool things with data!

Introduction
I am amazed with the power of the T5 transformer model! T5 which stands for text to text transfer transformer makes it easy to fine tune a transformer model on any text to text task. Any NLP task event if it is a classification task, can be framed as an input text to output text problem.
In this blog, I show how you can tune this model on any data set you have. In particular, I demo how this can be done on Summarization data sets. I have personally tested this on CNN-Daily Mail and the WikiHow data sets. The code is publicly available on my Github here.
T5-small trained on Wikihow writes amazing summaries. See snippet below of actual text, actual summary and predicted summary. This model is also available on HuggingFace Transformers model hub here. The link provides a convenient way to test the model on input texts as well as a JSON endpoint.
WikiHow Text: Make sure you've got all the cables disconnected from the back of your console,
especially the power cord., You'll need the straight end to be about 2-3 inches long.You will need a
large size paper clip for this method because it will need to go in about 1 and a half inches to
push the disc out., It's located on the left side of the console, right behind the vents.The eject
hole on an Xbox One S is located at the second hole on the left from the right corner and the third
hole up from the bottom. It can be more difficult to spot, so it's best to have a good amount of
light available. Doing so will cause the disc to pop out a little bit., Carefully pull the disc the
rest of the way out with your fingers. It might be a good idea to use a cloth or soft fabric to
protect the disc from fingerprints and scratching.
Actual Summary: Unplug all cables from your Xbox One.Bend a paper clip into a straight line.Locate the orange circle.Insert the paper clip into the eject hole.Use your fingers to pull the disc out.
Predicted Summary: Gather the cables.Place the disc on your console.Section the eject hole on the left side of the console.Pull out the disc.Remove from the back of the console.I run a machine learning consulting, Deep Learning Analytics. At Deep Learning Analytics, we are very passionate about using data science and machine learning to solve real world problems. Please reach out to us if you are looking for NLP expertise for your business projects. Original full story published on our website here.
T5 Transformer Model
T5 model which was released by google research adds the following to existing research:
- It creates a clean version of the massive common crawl data set called Colossal Cleaned Common crawl(C4). This data set is s two orders of magnitude larger than Wikipedia.
- It pretrains T5 on common crawl
- It proposes reframing of all NLP tasks as an input text to output text formulation
- It shows that fine tuning on different tasks — summarization, QnA, reading comprehension using the pretrained T5 and the text-text formulation results in state of the art results
- The T5 team also did a systematic study to understand best practices for pre training and fine tuning. Their paper details what parameters matter most for getting good results.
The figure below from T5 paper explains this input text to output text problem formulation.
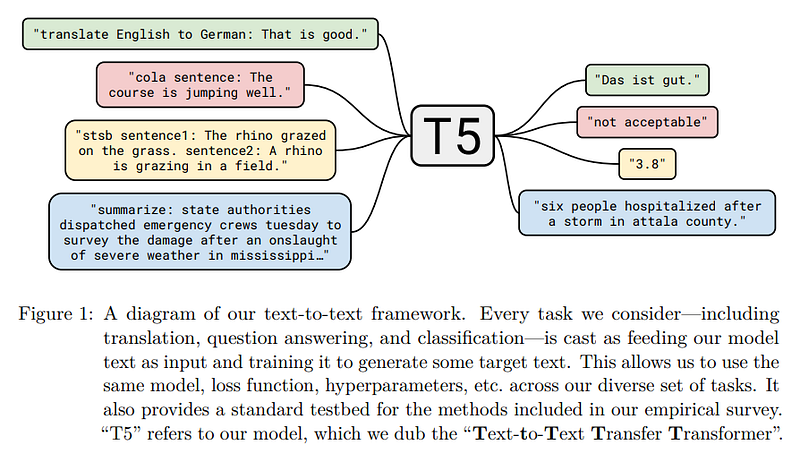
This blog from Google also explains the paper well. Lets deep dive into the code now!
T5 Fine Tuning Pipeline
We will use the HuggingFace Transformers implementation of the T5 model for this task. A big thanks to this awesome work from Suraj that I used as a starting point for my code.
Getting the data
To make it simple to extend this pipeline to any NLP task, I have used the HuggingFace NLP library to get the data set. This makes it easy to load many supporting data sets. The HuggingFace NLP library also has support for many metrics. I have used it rouge score implementation for my model.
The full code is available on my Github. For this demo, I will show how to process the WikiHow data set. The code though is flexible to be extended to any summarization task.
The Main Steps involved are:
- Load the Wikihow data. Please note for this dataset, two files need to be download to a local data folder
- The dataset object created by NLP library can be used to see sample examples
- We want to look at the average length of the text to decide if input can be tokenized to a max length of 512
For Wikihow dataset, the average length of text is 660 words and average length of summary is 49. The graph below shows distribution of text length
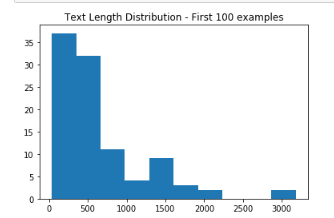
WikiHow text are usually 1–2 paragraphs instructional text on a subject. An example is shared below
WikiHow Text: Each airline has a different seat design, but you should find a lever on the side of
your seat in many cases. Pull it up to bring the seat back up. If you can't find the lever, ask a
flight attendant for help., Most airlines still use seat belts that only go across your lap. Locate
the buckle on one side and the latching device on the other. Straighten out each side, if necessary.
Insert the buckle into the latching device. Make sure you hear a click. Pull the belt until it's
snug across the tops of your thighs., Do this even if the captain turns off the “Fasten Seat Belts”
sign. If you decide to recline, make sure the belt stays snug across your lap. If you're using a
blanket, place it between the belt and your body.Creating a Pytorch Dataset Class for your data
Next, we define a Pytorch Dataset class which can be used for any NLP data set type. For the text to text T5, we have to define the fields for input text and target text. Here the ‘text’ of the article is an input text and the ‘headline’ is its summary.
I have used an input target length of 512 tokens and an output summary length of 150. The output of the wikihow dataset class are :
- source_ids: Tokenized input text length truncated/padded to a max length of 512
- source_mask: Attention mask corresponding to the input token IDs
- target_ids: Tokenized Target(summary) text length truncated/padded to a max length of 150
- target_mask: Attention mask corresponding to the target token IDs
My notebook on Github has sample code that you can use to play with the dataset class to check if the input is being encoded and decoded correctly.
Defining the T5 tuner
The T5 tuner is a pytorch lightning class that defines the data loaders, forward pass through the model, training one step, validation on one step as well as validation at epoch end.
I have added a few features here to make it easier to use this for summarization:
- I have used the NLP library to import the rouge_metric
- I have extended the code to generate predictions at the validation step and used those to calculate the rouge metric
- Added WANDB as the logger
Training the Model
I decided to train a T5 small model. I used a batch size of 4 for both train and val and could train this model on GTX 1080Ti in about 4 hours. The model was trained for 2 epochs and WANDB logger showed good improvement in Rouge1 score and Val loss as the model trained.
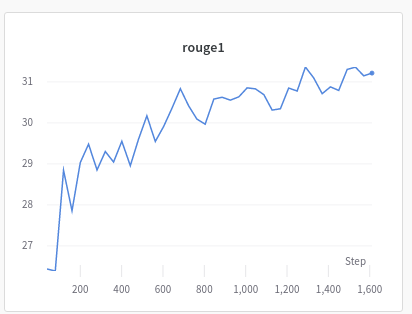
The full report for the model is shared here.
Testing the Model
I have uploaded this model to Huggingface Transformers model hub and its available here for testing. To test the model on local, you can load it using the HuggingFace AutoModelWithLMHeadand AutoTokenizer feature. Sample script for doing that is shared below.
The main drawback of the current model is that the input text length is set to max 512 tokens. This may be insufficient for many summarization problems. To overcome this limitation, I am working on a Longformer based summarization model. Will share a blog on that too soon!
Conclusion
T5 is an awesome model. It has made it easy to fine tune a Transformer for any NLP problem with sufficient data. In this blog I have created a code shell that can be adapted for any summarization problem.
I hope you give the code a try and train your own models. Please share your experience in the comments below.
At Deep Learning Analytics, we are extremely passionate about using Machine Learning to solve real-world problems. We have helped many businesses deploy innovative AI-based solutions. Contact us through our website here if you see an opportunity to collaborate.




