
Fine-Tune Your LLM Without Maxing Out Your GPU
How you can fine-tune your LLMs with limited hardware and a tight budget

Demand for Bespoke LLMs
With the success of ChatGPT, we have witnessed a surge in demand for bespoke large language models.
However, there has been a barrier to adoption. As these models are so large, it has been challenging for businesses, researchers, or hobbyists with a modest budget to customise them for their own datasets.
Now with innovations in parameter efficient fine-tuning (PEFT) methods, it is entirely possible to fine-tune large language models at a relatively low cost. In this article, I demonstrate how to achieve this in a Google Colab.
I anticipate that this article will prove valuable for practitioners, hobbyists, learners, and even hands-on start-up founders.
So, if you need to mock up a cheap prototype, test an idea, or create a cool data science project to stand out from the crowd — keep reading.
Why Do We Fine-tune?
Businesses often have private datasets that drive some of their processes.
To give you an example, I worked for a bank where we logged customer complaints in an Excel spreadsheet. An analyst was responsible for categorising these complaints (manually) for reporting purposes. Dealing with thousands of complaints each month, this process was time-consuming and prone to human error.
Had we had the resources, we could have fine-tuned a large language model to carry out this categorisation for us, saving time through automation and potentially reducing the rate of incorrect categorisations.
Inspired by this example, the remainder of this article demonstrates how we can fine-tune an LLM for categorising consumer complaints about financial products and services.
The Dataset
The dataset comprises real consumer complaints data for financial services and products. It is open, publicly available data published by the Consumer Financial Protection Bureau.
There are over 120k anonymised complaints, categorised into approximately 214 “subissues”.
I have a version of the dataset on my hugging face page that you can explore for yourself.
The Hardware
The hardware I used for training was a V100 GPU with 16 GB of RAM, accessed via Google Colab. This is a relatively inexpensive and accessible infrastructure, available for rent via Google Colab Pro at approximately 9.99 USD per 100 compute units.
The Large Language Model
The LLM used is RoBERTa¹ (XLM), which has approximately 563 million parameters. An overview of the model and its specification can be found here.
Though not the largest model currently available, RoBERTa still presents a demanding workload for those with access only to small-scale infrastructure. This makes it an ideal choice to demonstrate that training a relatively large model on small-scale infrastructure is feasible.
Note — RoBERTa is a pre-trained model pulled from the Hugging Face Hub.
Fine-tuning at Low Cost with LoRA
As stated in the introduction, PEFT methods have made it possible to fine-tune LLMs at a low cost. One such method is LoRA, which stands for Low-Rank Adaptations of large language models.
At a high level, LoRA accomplishes two things. First, it freezes the existing weights of the LLM (rendering them non-trainable); second, it injects trainable “lower-dimensional” layers into specified layers of the architecture.
This technique yields a model with far fewer trainable parameters while still preserving performance. LoRA has been shown to reduce GPU memory consumption by a factor of three compared to standard fine-tuning.
For further details on LoRA, please read the full paper.
Technical Details
In the past, the key challenge for training large language models on limited hardware was adapting the training parameters to prevent the process from crashing due to exceeding your GPU’s memory capacity.
With LoRA, one can push the boundaries of their hardware with just a few adjustments.
Applying LoRA
Assuming you have your dataset prepared, the first thing you need to do is set your LoRA configurations.
- task_type — The task for which you’re fine-tuning the model. For complaints classification, we are focusing on sequence classification.
- r — A hyperparameter named the LoRA attention dimension which affects the scaling.
- lora_alpha — Another hyperparameter that impacts the scaling.
- target_modules — Here we specify that the transformation should be applied to the attention modules in our transformer, hence we set this to “query” and “value”.
- lora_dropout — The dropout probability for the LoRA layers.
- bias — The bias type for LoRA.
- modules_to_save — Excluding the LoRA layers, we declare which layers of our model we wish to make trainable and save at the final checkpoint. For our purposes, we require the classification head to be trainable.
The next part of the script sets up the model itself. Here we are simply loading the pre-trained RoBERTa model from Hugging Face. The additional model parameters are simply passing dictionaries to the classification IDs such that the returned labels are in text form rather than numerically encoded.
Finally, we want to transform the pre-trained model based on our LoRA configuration. This is done with the get_peft_model function.
After applying LoRA, we are left with a network with the following structure:
trainable params: 4,110,764
all params: 562,951,596
trainable%: 0.7302162440267778Note: the original RoBERTa parameters are still in the network; they are simply frozen and therefore not trainable. Instead, we have the LoRA layers, which are fewer in number and trainable.
Initiate Training
Once we have our LoRA model, it’s simply a matter of setting up our trainer and initiating the training process.
Most aspects in the script are standard for training deep learning models; however, we have incorporated a few additional elements to improve GPU memory efficiency. Let’s briefly outline them.
- Per_device_train_batch_size — Setting this parameter to lower values maintains low RAM usage on your GPU at the expense of training speed. The lower the number, the more training steps are required to complete one epoch. Remember, one epoch is a complete run through the entire training dataset.
- Per_device_eval_batch — Setting this parameter dictates how many data samples are processed on each GPU core. Increasing this number increases the speed of evaluation and therefore the speed of training, but at the cost of GPU memory usage.
- Gradient_accumulation_steps — Usually, when updating deep learning models, there is a forward pass through the network and a loss is calculated. Following this, through a process known as backpropagation, the gradients are calculated and used to update the model parameters. With gradient accumulation, model parameters are not updated immediately after one forward pass. Instead, the gradients are stored and accumulated over the number of batches specified. Only after all the batches have passed through the network will the accumulated gradients be applied to update the parameters in the network. The effect here is to increase the effective batch size, meaning the model can effectively train on a larger batch size enabling you to reap the benefits of training on larger batches without the cost in GPU RAM usage.
- Fp16 (mixed-precision training) — Setting mixed precision training to true can help improve training speed at the cost of GPU usage. Essentially, some calculations in the network are done in 16-bit (half precision) instead of 32-bit (full precision) to speed up the calculations. However, the method requires both a 16-bit and 32-bit version of the model to be stored on your GPU device meaning 1.5 RAM usage.
Model Diagnostics
Let’s see how everything performed. Since this is about training effectively with limited hardware, let’s start by looking at the GPU RAM diagnostics.
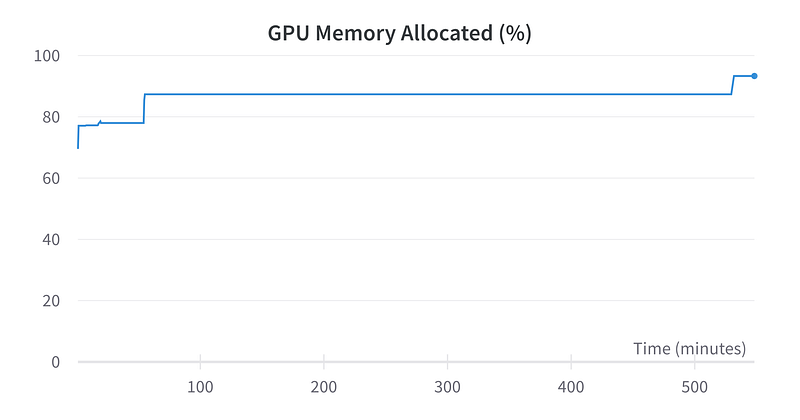
We were able to train our model for 9 hours without exceeding the RAM on our GPU. This is a good result.
What about the model performance? Let’s take a look at the validation and training loss.
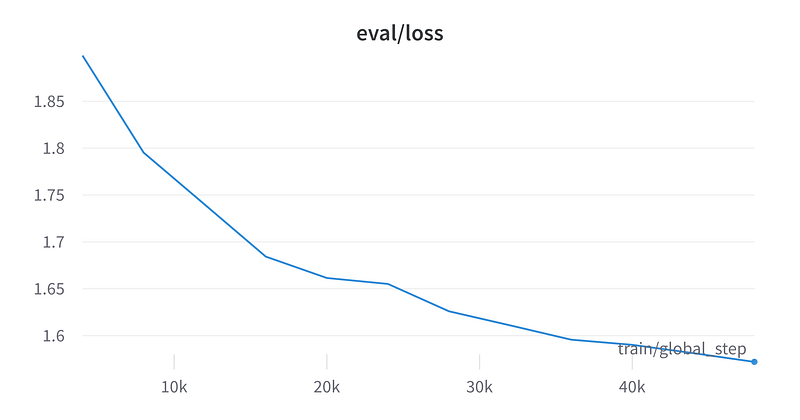
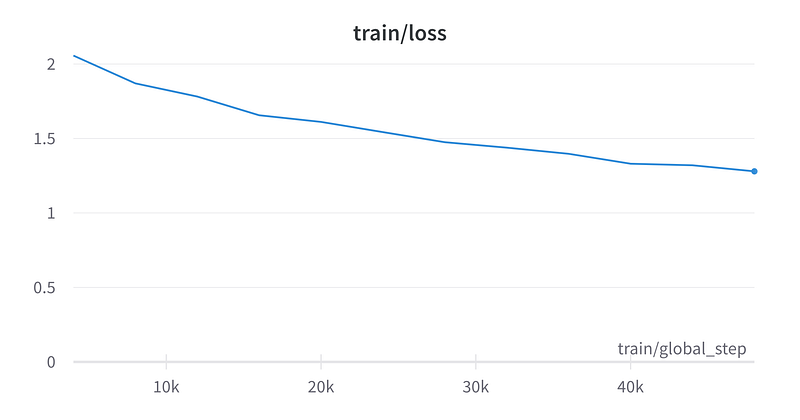
Upon examining the loss charts, it seems that the models have yet to converge, despite the training session lasting approximately nine hours.
This might not be surprising considering the substantial model size and limited infrastructure at our disposal, alongside the fact that many of the training parameter decisions were made to prioritise memory preservation over training speed.
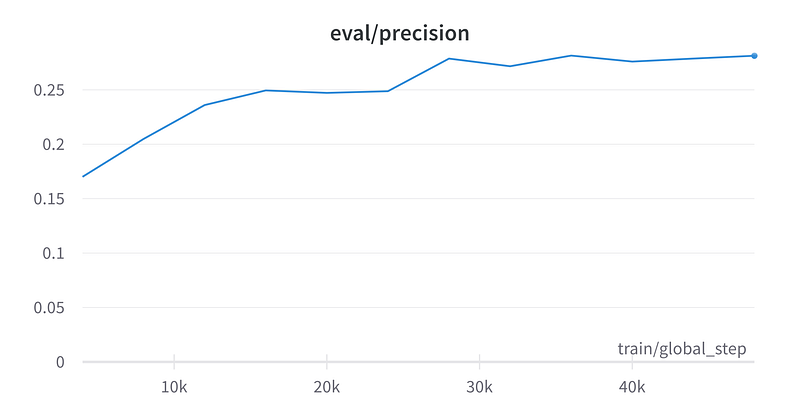
The model’s precision, recall, and F1 show that it’s prbably not ready for full production usage.
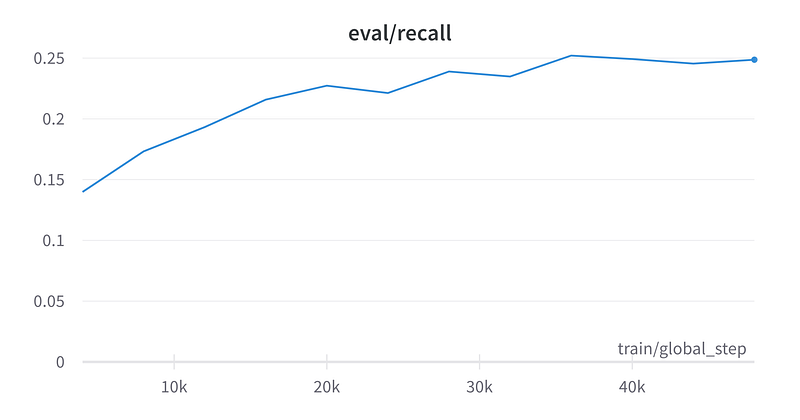
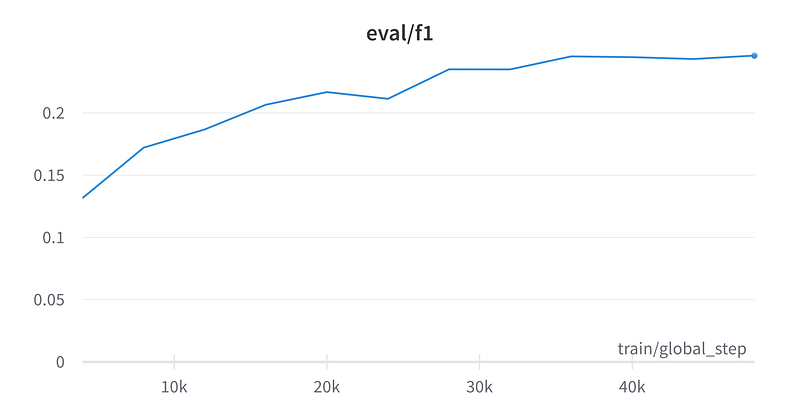
Cost
Google levies charges for renting GPUs via Colab based on compute units. Consequently, to calculate the cost of training the model for nine hours, we need to ascertain the number of compute units utilised. I was unable to locate explicit details from Google on their computation of these units, but it is suggested that a compute unit is determined as follows:
1 GB memory x 1 hour = 1 compute unit
The model was trained for approximately nine hours and utilised around 15 GB of RAM. Therefore, the training run consumed roughly 135 compute units. With a price of 9.99 USD per 100 compute units, the cost of training the model amounts to approximately 13.49 USD.
To achieve a usable state for the model, convergence may necessitate a slightly higher expenditure.
Conclusion
We have demonstrated that LoRA makes it possible for individuals with limited resources to engage in the world of LLMs. For interested readers, I recommend exploring other parameter efficient fine-tuning methods, as well as strategies for improving data efficiency in your training processes.
- The end-to-end Colab with the full model run is available here.
- I have hosted an app demonstrating the model Hugging Face for you to try for yourself.
- The full model diagnostics for the training run is available for you to review here.
- The Link to the model checkpoint is here.
- Watch a live tutorial on YouTube.
Thanks for reading.
If you’re keen to enhance your skills in artificial intelligence, join the waiting list for my course, where I will guide you through the process of developing large language model powered applications.
If you’re seeking AI-transformation for your business, book a discovery call today.
For more insights on artificial intelligence, data science, and large language models you can subscribe to the YouTube channel.
Citations
[1] Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., & Stoyanov, V. (2019). Unsupervised cross-lingual representation learning at scale. CoRR. Retrieved from http://arxiv.org/abs/1911.02116




