
Finding Important Features Using XGBoost
XGBoost is a short form for Extreme Gradient Boosting. It gained popularity in data science after the famous Kaggle competition Otto Classification challenge. But how does it work exactly?

What is XGBoost?
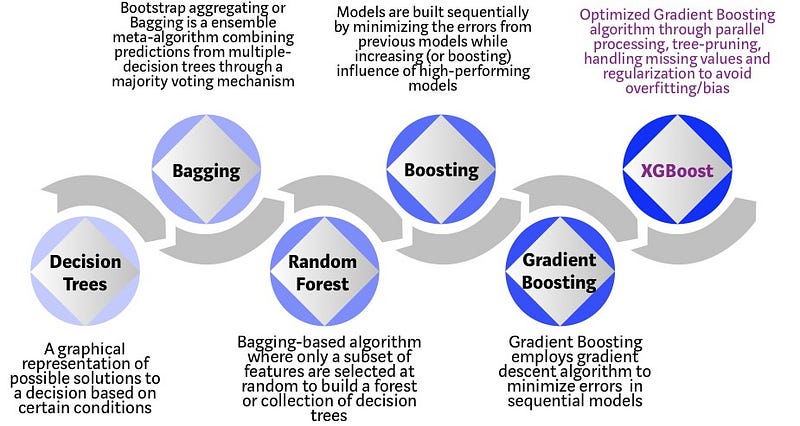
XGBoost is a decision-tree-based ensemble Machine Learning algorithm that uses a gradient boosting framework. In prediction problems involving unstructured data (images, text, etc.) artificial neural networks tend to outperform all other algorithms or frameworks. However, when it comes to small-to-medium structured/tabular data, decision tree based algorithms are considered best-in-class right now.
Why XGBoost works well?
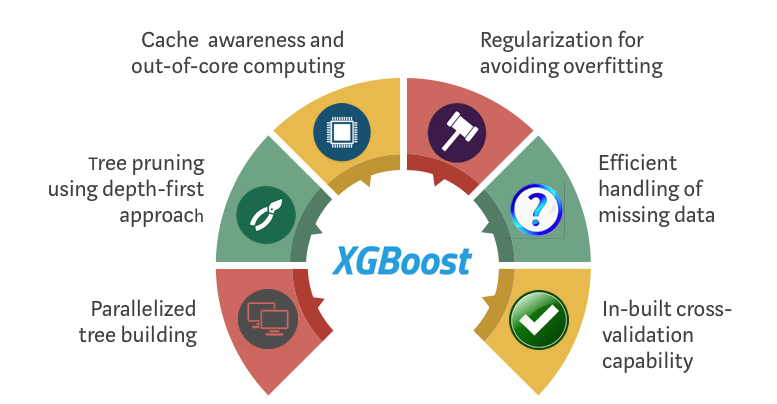
XGBoost and Gradient Boosting Machines (GBMs) are both ensemble tree methods that apply the principle of boosting weak learners (CARTs generally) using the gradient descent architecture. However, XGBoost improves upon the base GBM framework through systems optimization and algorithmic enhancements.
About XGBoost Built-in Feature Importance
- There are several types of importance in the XGBoost — it can be computed in several different ways. The default type is
gainif you construct model withscikit-learnlike API (docs). When you accessBoosterobject and get the importance withget_scoremethod, then default isweight. You can check the type of the importance withxgb.importance_type. - The
gaintype shows the average gain across all splits where feature was used. - The
weightshows the number of times the feature is used to split data. This type of feature importance can favourite numerical and high cardinality features. - There are also
cover,total_gain,total_covertypes of importance.
For more details, please find the link below:
Thanks for Reading!
If you enjoyed it, please follow me on Medium for more. It’s great cardio for your 👏 AND will help other people see the story.
If you want to continue getting this type of article, you can support me by becoming a Medium subscriber. It costs $5/month. A part of your subscription fee goes to me.