
Few-shot Financial Sentiment Classification — Does It Work?
The toughest thing in my data science career so far is not modeling, keeping up with the latest research, or even presenting complex ideas to non-technical folks, but getting the data cleaned and labeling done right — it’s a thankless job but crucial for the model to train and work. That’s why I was excited to learn about SetFit, a few-shot text classification regime introduced by Hugging Face/Intel/UKP labs.
There have been many innovations since BERT, but this one stands out for its practical advantage — outperforming GPT3 in a few shot settings while being 1600X smaller and fast enough to be trained on a CPU!
Few-shot learning matters in finance because labeled data is often the bottleneck to training good models — it can be expensive, tricky, and boring to label data accurately. So if we can get good performance with only a few labels, we can save time and focus on curating the data carefully and making it accurate and free of bias.
I took it for a test drive here and had 3 questions I wanted to answer:
- Does few-shot learning work for financial sentiment classification? There’s no strong reason why it shouldn’t, as it does well for other sentiment classification tasks like SST-5. I do wonder if we can get the big gains in the paper and how many data points it takes to classify financial sentiment well, which can be tricky due to financial context/ambiguity.
- There are no financial sentence transformers, so would a standard MPnet sentence transformer work better than a FinBERT? It’s a question of tradeoff between embeddings that are already trained on semantic similarity to financial embeddings that ‘understand’ finance better. My initial hypothesis would be that finance is not as esoteric as the medical domain, so a general pre-trained sentence transformer may be better than using a FinBERT that was not trained on semantic similarity.
- Finally, if we fine-tune SetFit with all possible data, can it outperform FinBERT? Essentially we are asking (1) are sentence transformers superior to general pre-trained models as a base for sentiment classification and (2) does the two-stage process scale to the entire dataset.
0. Why does it even work in the first place?
Before we dive into the experiments, let’s think about why it works in the first place.
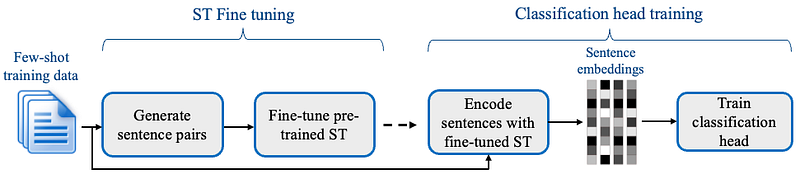
Pre-trained model: We are starting with Sentence Transformers (ST), a solid pretrained baseline that has good semantic representations of sentences based on similarity. A recent paper fine-tuned ST directly for sentiment and found it slightly better than FinBERT.
Contrastive learning: Because there’s very little training data, we need to squeeze everything we can from them — sampling and pairing positive and negative data allows the modeling process to create more examples for the model to learn from during the ST fine-tuning stage. This resampling works to an extent until the pairs themselves are repeated too often, and the model overfits (authors recommend 1 epoch and 20 resampling or iterations).
1. How does SetFit work out of the box for Financial Sentiment?
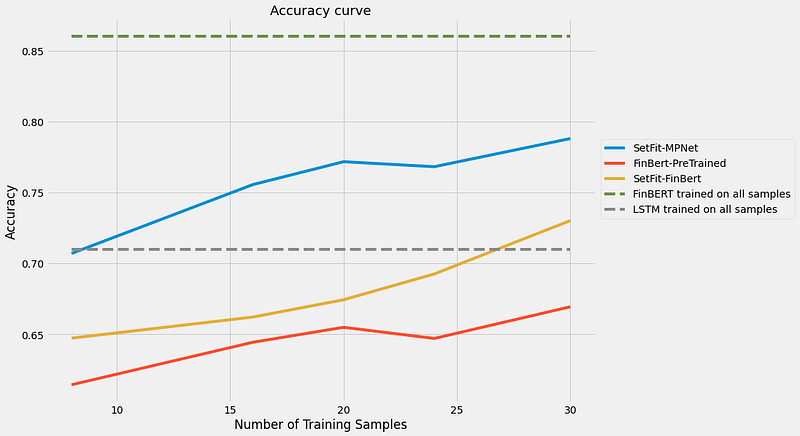
Naturally, the dataset I defer to is the Financial Phrasebank by Malo et al. Indeed, we see SetFit working on a few-shot basis a lot better than just purely fine-tuning a base FinBERT in a few-shot regime. 20 samples seem to be quite a sweet spot, as mentioned by one of the authors, where the improvement slows down a bit after. It could also be due to the number of iterations that were set as well (which was also 20). Definitely, something to test out.
That said, there is still a relatively big gap from the full model (~5%) even after training on 30 samples per label. Contrast this with the paper’s example, where after 20 samples, SetFit is close to the full model’s accuracy. But this may be due to the potential ambiguity present in the dataset, so more examples are needed to achieve decent results.
2. Can we improve SetFit by switching to a finance backbone?
One of the limitations of current sentence transformers is that there isn’t one that was already trained on financial/business domain sentences. That may be a problem as financial/business terms can have different meanings from typical terms.
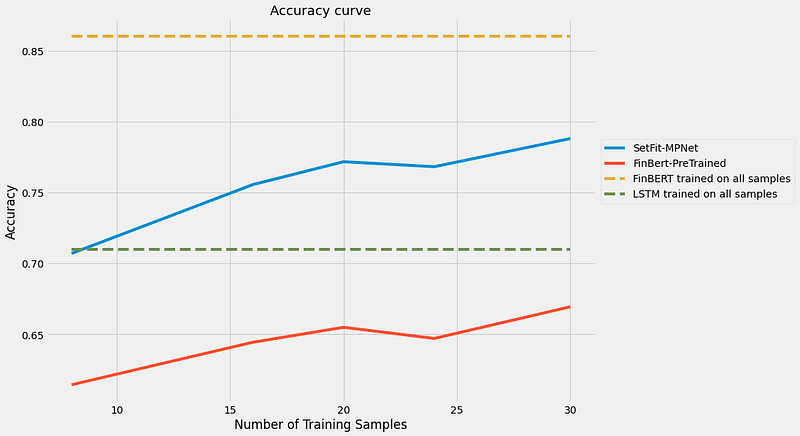
Running a pre-trained FinBERT that was trained on news, analyst reports, and filings using the SetFit setup yields results in between SetFit and FinBERT. Two observations:
(1) The SetFit 2-step training process is better than a normal fine-tuning setup in a low data regime.
(2) Financial/Business domain pre-training is not as important as the sentence embedding pre-training. It’s possible that the financial lexicon is covered well enough in the pre-training corpus, so there are not many gains from fine-tuning specifically on financial text. It could also be a consequence of our target corpus, which focuses on
3. Conclusion
Using SetFit-MPNet is probably the best approach for general financial sentiment classification in a low-data regime. I love the simplicity of the approach, and it highlights the power of sentence transformers not just for semantic tasks but also for classification.
Let me know if you do try out my code on your own dataset and see anything different.
PS: I didn’t have the patience/compute to do #3, but these folks did something similar and found sentence transformers to be superior.





