
Ferret LLM: Apple Entry in Race of “Multimodal AI” Technology
Step into the future where AI understands images and language like never before, thanks to hybrid region representation

Introduction
Apple AI researchers have introduced Ferret, an innovative multimodal large language model (MLLM) specialized for referring and grounding in images. Published on arXiv, this paper marks the first time Apple has openly shared research on a large generative AI model.
Referring and grounding are critical spatial reasoning skills for AI systems. Referring involves comprehending semantics of a specified image region, while grounding means localizing objects or areas based on textual descriptions. Humans seamlessly integrate referring and grounding when communicating about images. However, existing ML models lack such detailed spatial understanding.
To address this limitation, Ferret employs novel techniques like a hybrid region representation and spatial-aware visual sampling. Trained on a large instruction tuning dataset called GRIT, Ferret achieves significant gains over previous models in referring, grounding and conversational tasks. Remarkably, it also mitigates object hallucination issues faced by generative models.
As one of the first few attempts at integrating multimodality in large language models by the tech giant, Ferret highlights Apple AI’s investments into impactful AI research and its effects across Apple products and services.
Keywords: Apple Ferret AI, Multimodal Large Language Model (MLLM), Referring and Grounding, Spatial Reasoning, GRIT Dataset, Hybrid Region Representation, Spatial-Aware Visual Sampling, Apple AI Research, Innovative AI, Generative AI Model, Image Semantics, Object Localization, Visual Information, Language Semantics, Free-Form Region Shapes, Spatial Understanding, Object Hallucination, Multimodal AI, Ground and Refer Instruction Tuning, Visual Grounding, Grounded Captioning

Challenges in Precise Spatial Understanding
Humans can easily point to or describe specific objects, areas or relationships in an image during communication. We take such referring and grounding abilities for granted in daily visual conversations.
However, most AI systems today lack the detailed spatial understanding required for pinpoint referring and grounding. For instance, DALL-E can generate realistic images from text prompts but cannot accurately comprehend local regions within an image.
Referring and grounding require properly associating visual information with language semantics at a fine-grained level. But existing works have focused on learning them individually using separate models.
Humans seamlessly transfer knowledge between referring and grounding tasks. Current multimodal AI models also cannot handle the free-form region shapes humans use, like dots, strokes or complex polygons. The models are limited to just points and bounding boxes.
The Apple researchers identified three key limitations in existing models:
- Inability to unify referring and grounding within one framework
- Lack of support for diverse free-form region shapes
- Lack of open-vocabulary, instruction-following and robustness
Hybrid Region Representation in Ferret
To overcome these challenges, the researchers propose Ferret, a novel MLLM architecture specialized for referring and grounding.
The key innovation in Ferret is a hybrid region representation that combines discrete coordinates with continuous visual features.
For coordinates, Ferret uses direct natural language numerals (like “100, 200, 500, 600”). The coordinates are quantized into discrete bins.
For free-form shapes, a spatial-aware visual sampler extracts continuous features. It samples points in the region mask and propagates neighborhood information to handle varying sparse shapes.
The discrete and continuous representations are combined as the hybrid input for referring regions. This allows Ferret to handle points, boxes or free-form shapes seamlessly.
For grounding, Ferret directly generates coordinate bounding boxes in text output for detected objects. The model implicitly aligns object names with their locations.
Enabling Open-Vocabulary, Robustness via GRIT
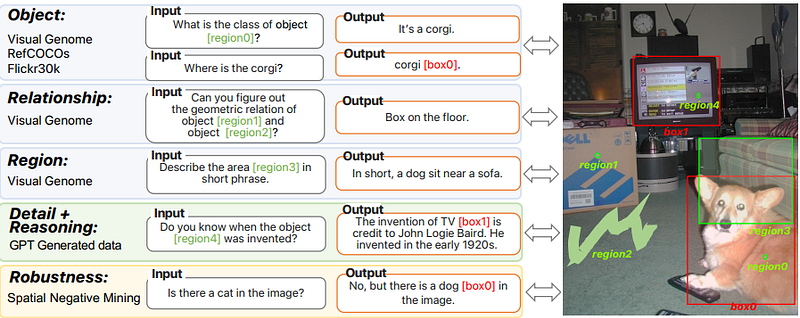
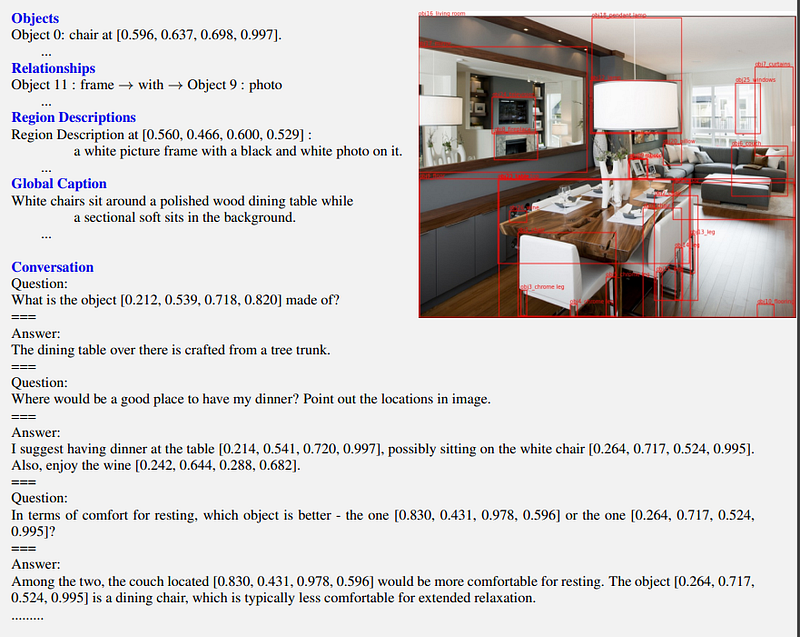
The researchers collected a large Ground and Refer Instruction Tuning (GRIT) dataset with 1.1M examples to train Ferret’s capabilities. GRIT includes:
- Data converted from existing datasets into instruction-following formats
- 34k human-annotated conversations for open-vocabulary tuning
- 95k negative samples mined to improve model robustness
It covers objects, relationships, region descriptions and reasoning across input/output combinations.
GRIT’s conversational data and negative mining are critical to make Ferret open-vocabulary, instruction-following and robust.
Here is an explanation of the model architecture for Ferret:
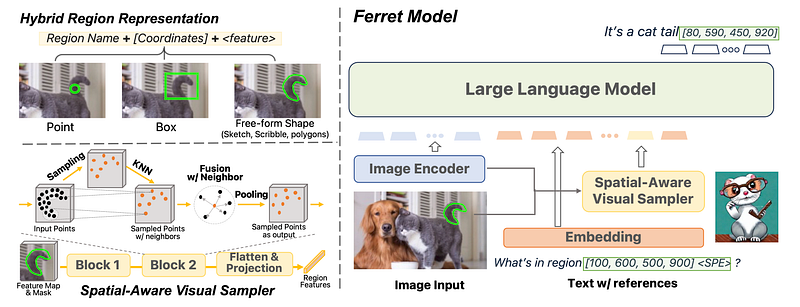
Image Encoder
- Ferret first uses a pre-trained CLIP-ViT-L/14 model to encode the input image into a feature map Z ∈ RH×W×C
- CLIP-ViT-L/14 is a convolutional vision transformer trained on large amounts of image-text pairs
- It extracts rich semantic visual features from the image
Spatial-Aware Visual Sampler
- To handle irregularly shaped regions, a spatial-aware visual sampler is proposed
- It samples points inside the region mask and propagates information from neighbors
- This accounts for varying sparsity across complex free-form shapes
- It uses techniques like farthest point sampling and gathering local neighbors
- Outputs a feature f that summarizes the continuous visual features of the region
Hybrid Region Representation
- Discrete coordinates are expressed in natural language numerals (e.g. “100, 200, 500, 900”)
- Continuous visual features f are extracted using the spatial-aware sampler
- For each region, its coordinates and visual feature f are concatenated as the hybrid representation
Language Model
- An encoder-decoder transformer (Vicuna) is used as the language model backbone
- Image features Z undergo an additional transformation to match text token dimensions
- The hybrid region representations are injected into the input text sequence
- For grounding, coordinate bounding boxes are directly generated in the text output
Training Objectives
- Ferret is trained end-to-end on the GRIT dataset via instruction tuning
- The model learns to comprehend spatial semantics from referred input regions
- It learns to ground relevant objects in output by generating coordinates
- Auxiliary losses may be applied to different modules to facilitate learning
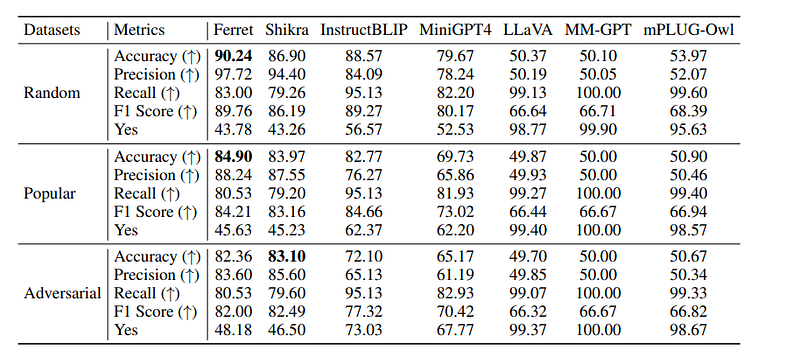
Superior Performance across Diverse Tasks
Extensive experiments demonstrate Ferret’s strong improvements over previous models like DALL-E and GLIP on:
- Input referring: 20% higher accuracy in classifying referred objects
- Output grounding: State-of-the-art on visual grounding and grounded captioning benchmarks
- Conversation: 20.4% higher on visual dialog tasks needing referring and grounding compared to leading MLLMs
Remarkably, Ferret also greatly reduces object hallucination issues faced by generative ML models. It represents a big step towards reliable and controllable multimodal AI.

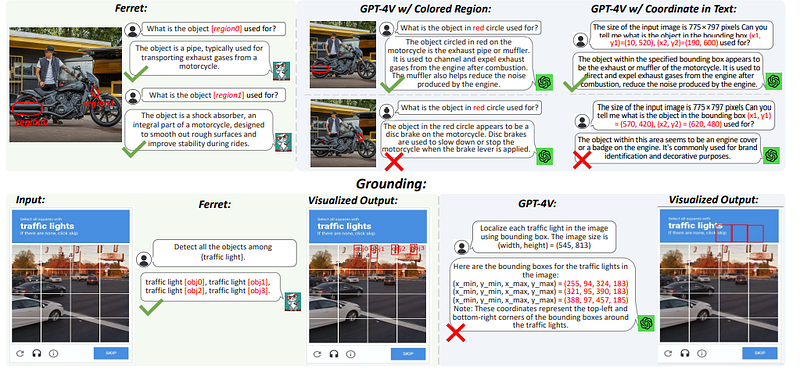
FERRET v.s. GPT-4V(ISION): A QUICK GLANCE AT REFERRING & GROUNDING
Referring
- For GPT-4V, referred regions are specified either by coloring them or providing coordinates in text
- But it struggles with precise understanding of small local regions compared to Ferret
- In the motorcycle example, GPT-4V fails to comprehend the ‘shock absorber’ accurately
- Ferret is specialized for fine-grained spatial semantics, outperforming GPT-4V for small details
Grounding
- GPT-4V can localize objects when prompted to provide bounding boxes
- But it fails to accurately ground small objects in complex scenes, like traffic lights
- Ferret precisely identifies most objects even in cluttered images, as in the traffic light example
- Specialized techniques like spatial-aware sampling help Ferret’s precision
Let’s Try
Install
- Clone this repository and navigate to FERRET folder
git clone https://github.com/apple/ml-ferret
cd ml-ferretInstall Package
conda create -n ferret python=3.10 -y
conda activate ferret
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install pycocotools
pip install protobuf==3.20.0Install additional packages for training cases
pip install ninja
pip install flash-attn --no-build-isolationTrain
FERRET is trained on 8 A100 GPUs with 80GB memory. To train on fewer GPUs, you can reduce the per_device_train_batch_size and increase the gradient_accumulation_steps accordingly. Always keep the global batch size the same: per_device_train_batch_size x gradient_accumulation_steps x num_gpus.
Hyperparameters
We use a similar set of hyperparameters as LLaVA(Vicuna) in finetuning.
HyperparameterGlobal Batch SizeLearning rateEpochsMax lengthWeight decayFERRET-7B1282e-5320480FERRET-13B1282e-5320480
Prepare Vicuna checkpoint and LLaVA’s projector
Before you start, prepare our base model Vicuna, which is an instruction-tuned chatbot. Please download its weights following the instructions here. Vicuna v1.3 is used in FERRET.
Then download LLaVA’s first-stage pre-trained projector weight (7B, 13B).
FERRET Training
The scripts are provided (7B, 13B).
Evaluation
Please see this doc for the details.
Checkpoints
We extracted the delta between our pre-trained model and Vicuna. Please first download weights of Vicuna following the previous instruction. Then download our prepared offsets of weights: 7B, 13B using wget or curl, and unzip the downloaded offsets. Lastly, apply the offset to the Vicuna's weight by running the following script:
# 7B
python3 -m ferret.model.apply_delta \
--base ./model/vicuna-7b-v1-3 \
--target ./model/ferret-7b-v1-3 \
--delta path/to/ferret-7b-delta
# 13B
python3 -m ferret.model.apply_delta \
--base ./model/vicuna-13b-v1-3 \
--target ./model/ferret-13b-v1-3 \
--delta path/to/ferret-13b-deltaNotices: Apple’s rights in the attached weight differentials are hereby licensed under the CC-BY-NC license. Apple makes no representations with regards to LLaMa or any other third party software, which are subject to their own terms.
Please refer to the next section about how to set up a local demo with pre-trained weight.
Demo
To run our demo, you need to train FERRET and use the checkpoints locally. Gradio web UI is used. Please run the following commands one by one.
Launch a controller
python -m ferret.serve.controller --host 0.0.0.0 --port 10000Launch a gradio web server.
python -m ferret.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --add_region_feature
Launch a model worker
This is the worker that load the ckpt and do the inference on the GPU. Each worker is responsible for a single model specified in --model-path.
CUDA_VISIBLE_DEVICES=0 python -m ferret.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path ./checkpoints/FERRET-13B-v0 --add_region_feature
Wait until the process finishes loading the model and you see “Uvicorn running on …”. Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
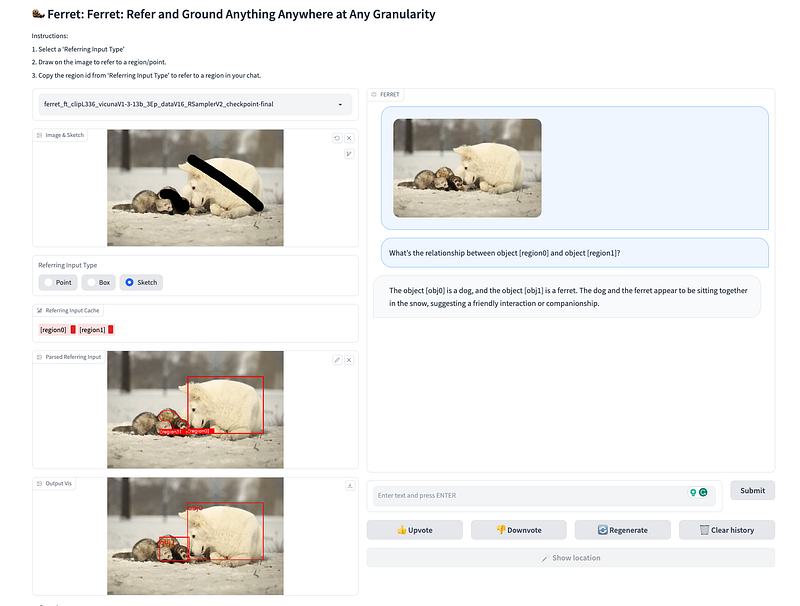
Example of Ferret Interactive Demo.
Conclusion
With techniques like hybrid region representation and spatial-aware sampling, Ferret sets a new bar for multimodal AI on precise spatial understanding. The large GRIT dataset was key in training these capabilities.
This work is an impressive demonstration of Apple’s AI research investments into impactful generative models. Integrating referring and grounding abilities in ML systems could enable more natural and interpretable human-AI interaction.
Github Link:
References
- Ferret: Refer and Ground Anything Anywhere at Any Granularity. Haoxuan You, Haotian Zhang, Zhe Gan, et al. arXiv preprint arXiv:2310.07704, 2022.
- Large Language Models are Few-Shot Learners. Tom Brown, Benjamin Mann, Nick Ryder, et al. Advances in Neural Information Processing Systems, 2020.
- Flamingo: a visual language model for few-shot learning. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, et al. arXiv preprint arXiv:2204.14198, 2022.
- Uniter: Universal Image-Text Representation Learning. Yen-Chun Chen, Linjie Li, Licheng Yu, et al. European Conference on Computer Vision (ECCV), 2020.
- Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. Keqin Chen, Zhao Zhang, Weili Zeng, et al. arXiv preprint arXiv:2306.15195, 2023.
- Kosmos-2: A Calibration of Large Language Models for Spatial Common Sense. Gucheng Li, Siyu Ren, Zhe Gan, et al. arXiv preprint arXiv:2302.13969, 2023.
- LLaVA: Towards All-Purpose Vision-and-Language Assistance. Xiujun Li, Yi Ren, Xu Tan, et al. arXiv preprint arXiv:2302.05132, 2023.
- Unifying Grounding and Vision-and-Language Understanding. Gengyu Wang, Liqun Chen, Zhe Gan, et al. arXiv preprint arXiv:2302.00294, 2023.
- Exploring the Limits of Large Vision-and-Language Models. Gucheng Li, Bin Bi, Xu Tan. arXiv preprint arXiv:2302.05267, 2023.