
Feature Extraction Techniques
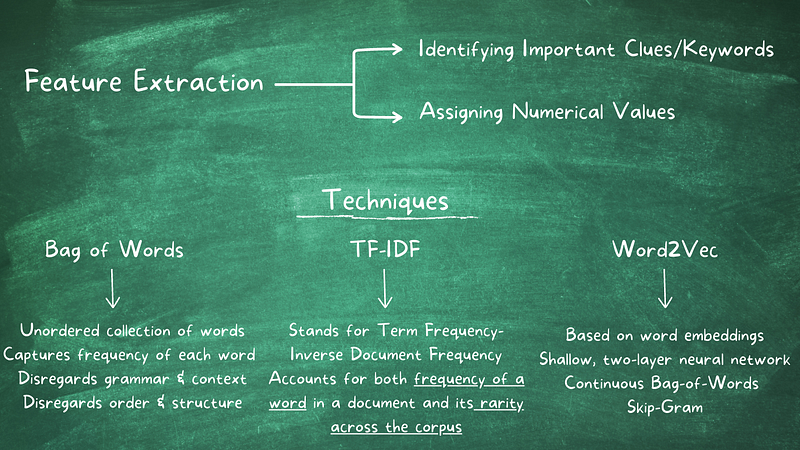
Feature extraction is an important step in Natural Language Processing (NLP) that helps improve the accuracy and performance of machine learning algorithms. Feature extraction enables the conversion of raw or unprocessed text data into a structured representation that can be processed and analyzed by machine learning algorithms. Feature extraction involves two key steps:
1. Identifying important features: Feature extraction aims to identify significant features or clues within the text. These features can be words, terms, phrases, or even structural elements of the text.
2. Assigning numerical values: Once the important features are identified, they need to be transformed into a format that can be utilized by machine learning algorithms. This typically involves assigning numerical values, often 0 or 1, to represent the presence or absence of each feature in a given text.
There are several feature extraction techniques. We will discuss Bag of Words (BoW) and TD-IDF (Term Frequency and Inverse Document Frequency) techniques in this post.
Bag of Words (BoW)
Bag of Words (BoW) feature extraction technique is a simple and widely used approach for representing text data as numerical feature vectors. BoW works by counting the number of times each word appears in a document, disregarding grammar, context, and word order. The resulting vector is a bag of words, where each element in the vector represents the count of a particular word.
Let us explore the BoW model with an example of movie reviews to categorize positive and negative reviews.
- Review 1: This movie is good.
- Review 2: Not so good.
- Review 3: Amazing movie!
Let’s discuss each of the steps involved in this technique.
1. Pre-Processing: As part of noise removal and normalization, we remove the punctuation and convert the text into lower case. Then, we tokenize each review by splitting them into individual words. The tokenized words for each review are:
- Review 1: [“this”, “movie”, “is”, “good”]
- Review 2: [“not”, “so”, “good”]
- Review 3: [“amazing”, “movie”]
2. Vocabulary Construction: We create a vocabulary or dictionary containing a unique set of words from the reviews. Let’s assume our vocabulary is as follows:
[“this”, “movie”, “is”, “good”, “not”, “so”, “amazing”]
3. Feature Vector Generation: For each review, we generate a feature vector representing the presence or frequency of words from the vocabulary. Let’s use the presence-based approach:
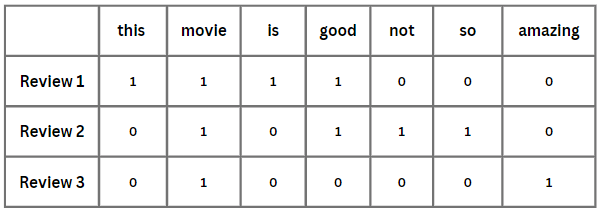
These feature vectors capture the presence(1) or absence(0) of words from the vocabulary in each review, allowing you to analyze or apply machine learning algorithms to classify or categorize the reviews based on the word occurrences.
TF-IDF
TF-IDF, short for term frequency–inverse document frequency, is a statistical measure that is often used to reflect how important a term or word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling.
The TD-IDF score for a term within a specific document is calculated by considering two factors: term frequency (TF) and inverse document frequency (IDF).
1. Term Frequency (TF) is the number of times a word appears in a document. The intuition behind this measure is that the more frequently a word appears in a document, the more important it is in that document.
2. Inverse Document Frequency (IDF) is a measure of how much information a word or term provides across a collection of documents. It helps in identifying terms that are rare and carry more significance.
IDF of a term = Total number of documents in the collection / the number of documents containing the term.
Once the term frequency (TF) and inverse document frequency (IDF) are computed, they are multiplied together to obtain the TD-IDF score for a term in a document. The resulting TD-IDF score provides a way to compare and rank terms based on their importance in a particular document relative to the entire document collection. Higher TD-IDF scores indicate more significant and relevant terms, while lower scores indicate less importance.
For example, the word “the” is very common in English, so it will have a low TF-IDF score. However, the word “apple” is less common, so it will have a higher TF-IDF score.
Consider a document containing 100 words wherein the word “apple” appears 5 times. The term frequency (i.e., TF) for apple is then (5 / 100) = 0.05.
The inverse document frequency (IDF) for apple can be calculated by taking the total number of documents in the corpus (let’s say there are 1000 documents) and dividing it by the number of documents that contain the word “apple” (let’s say there are 100 documents). The IDF for apple is then (1000 / 100) = 10.
The TF-IDF score for apple is then the product of the TF and IDF, which is 0.05 * 10 = 0.5.
This means that the word “apple” is relatively important to the document, since it appears 5 times and is not very common in general (only 100 out of 1000 documents contain it).
TF-IDF can be used to:
Rank documents in search results. Documents with higher TF-IDF scores for the search terms are more likely to be ranked higher in the search results.
Identify important words in a document. Words with high TF-IDF scores are more likely to be important to the document’s meaning.
Cluster documents. Documents with similar TF-IDF scores can be clustered together.





