
Bagging, Boosting, Bootstrapping: An Intuitive Approach
Pretentious Data Science Terms That are Easy to Understand

If you’ve ever been in a room with bright data scientists throwing out vocabulary most of which doesn’t make sense to you, welcome to the club. You’re probably at the Conscious Incompetence stage of your learning. We’ve all been there (or still are). At this stage, you’re familiar with the building blocks but got to realise the depth of Data Science and probably caught an impostor syndrome on your way.
Data science is challenging, but some concepts are overrated. We often use vocabulary that sounds sophisticated and could scare off the novices. While actually, these terms stand behind concepts that are very intuitive to understand.
In this series of posts, I’ll share the list of terms I once found overwhelming to get started with but realised how intuitive they are once you actually read about them.

Note: this is an attempt to explain these concepts in a high-level intuitive approach. They say, if you can’t explain it simply, you don’t understand it well enough. So here goes my try.
In this first post we’ll try to make sense of:
- Bootstrapping
- Bagging
- Boosting
Bootstrapping
Say, you want to estimate 9th-graders’ average math score. As you don’t have access to every single 9th-grader’s score (aka your population), the best you can do is estimate an average based on your own 10 students’ grades (aka your sample):
S = {9.2, 8.5, 10, 9, 7.1, 6.8, 5.5, 7, 9.2, 8.8}.
To estimate the average, you’d go for:
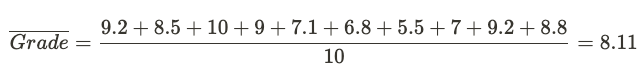
But the problem is that you only have 10 data points which might not fully represent the whole population. So, you can’t really be sure on your estimate 8.11 and need an error margin. What you can do is to make the most of the small data you have and bootstrap:
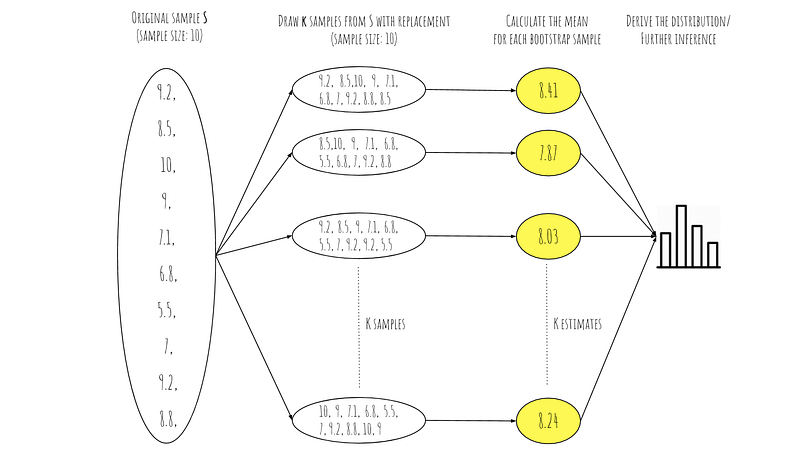
Note that as the drawn samples have the same size as the original and they’re drawn with replacement, some of the points end up duplicated in some samples while others are left out. As you can see, when doing this for K times, we end up with K different estimates that vary, in this case, from 7.87 to 8.41. Recall that our initial estimate was 8.11.
What does this give us?
In order to be able to reason about our population and how representative our parameter estimate is, we need a certain image of its variability. By continuously estimating the metric (in this case — the mean) from randomly resampled populations, we gain information about the distribution of our bootstrap metrics and their stability. Most importantly, by having a bootstrap distribution, we can derive the standard error of our estimate and know how much error to account for when considering our estimate.
What are bootstrap applications?
Apart from the discussed use-case, bootstrapping is also used for building confidence intervals, validating and stabilising predictive model performance. A widely used approach for the latter is bagging.
Bagging
The idea behind bootstrap aggregating (bagging) is the following: in order to have a more robust predictive model, bootstrap your initial training data into K samples, train predictive models on each of those and ‘average’ their results.
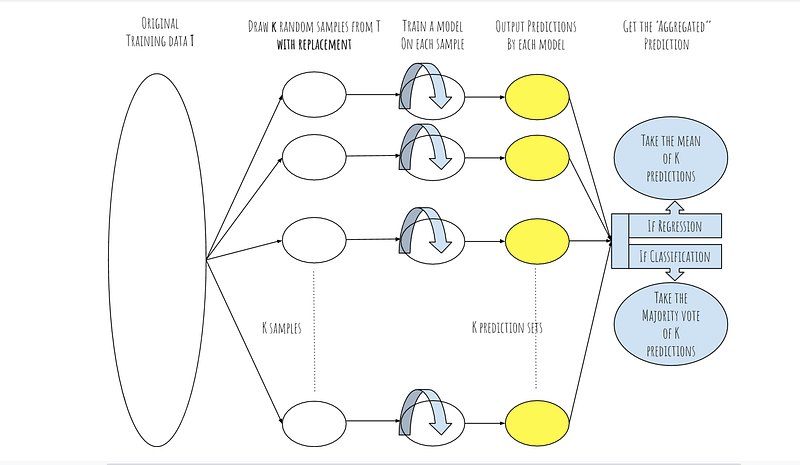
Boosting
Finally, boosting algorithms are meant to improve the overall predictive power by starting out with simple, ‘weak’ models and then iteratively improving their performance based on their predecessor. One such algorithm is AdaBoost. Starting with a simple classifier for the first iteration, the algorithm then gives higher weights to observations that were misclassified. In this way, the classifier built on the next iteration ‘pays more attention’ to those observations by improving performance compared to that of iteration one. The process then repeats.
Further reading
Once you develop the intuition behind these terms, I’d recommend reading a more technical overview like this post for bootstrapping and this for bagging and boosting.
What’s Next
In the following posts of these series, I plan to cover terms as degrees of freedom, calibration, Monte Carlo simulations and more. Would also love to hear what’s in your list and if I can give a try explaining it.
That’s about it!
Hope you find this useful. Stay home, stay safe, stay productive.
