
Exploring the Cutting-Edge: A Comparative Analysis of SDXL in Image Generation

Introduction
“In the ever-evolving landscape of image generation, remarkable strides have been made, thanks to the advent of various generative models. Among these pioneers, one class stands out with exceptional prowess — Stable Diffusion Models. Renowned for their ability to produce high-quality images marked by remarkable stability and diversity, these models have become a focal point of research and innovation.
In this article, we embark on a journey to explore the world of Stable Diffusion Models, with a particular focus on the revolutionary Stable Diffusion XL 1.0 (SDXL). Image generation is an art, and these models are the brushes, each with its unique stroke and style. We will delve deep into their architectural intricacies, the training methodologies that underpin their strength, and their overall performance.
Join us as we unravel the secrets behind these generative marvels, discovering their strengths, limitations, and the artistic horizons they unlock. By the end of this journey, you will gain a profound understanding of how Stable Diffusion Models, including the advanced SDXL 1.0, are shaping the future of image generation.”
I. What are Stable Diffusion Models?
Stable Diffusion Models, the foundation upon which SDXL 1.0 is built, are a class of generative models designed for image synthesis. They are known for their training stability and their unique approach to high-resolution image generation. These models harness the power of diffusion processes, inspired by stochastic differential equations, to unveil images step by step. At their core, they slowly reveal an image by systematically adding controlled Gaussian noise, resulting in a gradual but refined image generation process.
A defining trait of SDXL 1.0 is its knack for generating images that feature remarkably realistic faces, legible text embedded within images, and superior overall composition. What sets this achievement apart is the model’s proficiency in achieving these results with concise and straightforward prompts, simplifying the user experience. Moreover, SDXL offers a rich spectrum of features, encompassing image-to-image prompting, inpainting, and outpainting, amplifying its adaptability for a wide range of creative and practical applications.

II. Dataset
SDXL’s prowess is attributed, in part, to the extensive dataset it was trained on. The dataset for SDXL’s pretraining and fine-tuning is a formidable collection, comprising 1.8 million images sourced from the ImageNet dataset and an additional 1.2 million images from the OpenImages dataset. These images underwent preprocessing, with resizing to a standardized 256 x 256 pixels and augmentation techniques, including random crops, flips, and rotations.
For evaluation purposes, the authors also made use of a subset of the COCO dataset, a well-known resource for object detection and segmentation tasks. The COCO dataset comprises over 330,000 images, encompassing 80 object categories.
The ImageNet dataset, containing over 1.2 million images with 1000 object categories, and the OpenImages dataset, with over 9 million images across 600 object categories, are prominent sources that contributed to SDXL’s comprehensive training regimen.
III. Architectural Variations in Stable Diffusion Models, Including SDXL 1.0
Stable Diffusion Models, including the innovative SDXL 1.0, encompass a wide range of architectural variations, each designed to address specific challenges in image generation. Let’s explore a few of these architectural characteristics:
Denoising Score Matching (DSM):
Architecture: DSM employs a series of denoising autoencoders, consisting of both encoders and decoders. The decoder is trained to generate high-quality images from noisy inputs, contributing to enhanced image fidelity and fine details. While DSM forms the foundation for stable diffusion models, it has evolved significantly in the context of SDXL 1.0.
Stable Diffusion XL 1.0’s Architectural Advancements: SDXL 1.0 builds upon the foundational principles of DSM but introduces architectural enhancements in the form of a more substantial UNet backbone, capable of capturing intricate details for superior image quality.
Training Method: SDXL 1.0 employs denoising score matching techniques while leveraging a richer architectural framework, allowing for greater control and precision during the image generation process.
Diffusion Probabilistic Models (DPM):
Architecture: DPM utilizes a deep neural network to parameterize the diffusion process. It adopts a predetermined number of steps to generate images, a strategy that contributes to its reputation for image quality.
Stable Diffusion XL 1.0’s Architectural Advancements: SDXL 1.0 takes inspiration from DPM’s architectural approach but significantly enhances the network’s capacity, enabling it to create high-resolution 1024x1024 pixel images that are rich in detail and realism.
Training Method: SDXL 1.0 continues to employ the maximum likelihood estimation, ensuring the generation of high-quality samples. However, its architectural improvements lead to a remarkable leap in sample quality, making it a worthy successor to DPM.
Diffusion Variational Autoencoders (DVAE):
Architecture: DVAE combines the diffusion process with a variational autoencoder, utilizing a stochastic encoder to sample from a latent space. Its architectural framework enables a degree of control over image attributes.
Stable Diffusion XL 1.0’s Architectural Advancements: SDXL 1.0 builds upon the concept of combining diffusion with a variational autoencoder but refines its architectural intricacies to offer users a stronger framework for generating images with precise control over attributes.
Training Method: SDXL 1.0, like DVAE, optimizes a combination of likelihood and KL divergence terms. However, its architectural innovations provide users with enhanced capabilities, making the model accessible to a broader range of applications.
In summary, while exploring architectural variations in stable diffusion models, it’s evident that SDXL 1.0 introduces significant architectural enhancements that position it as a high-resolution image generation powerhouse. These innovations result in images of remarkable quality, detail, and realism, making SDXL 1.0 a compelling choice for a wide array of creative and practical applications.

IV. Training and Stability
One of the notable advantages of stable diffusion models is their inherent training stability. The gradual diffusion process ensures that the model can be trained effectively without facing mode collapse issues. However, each model might require specific training procedures and hyperparameter tuning to achieve the best results.
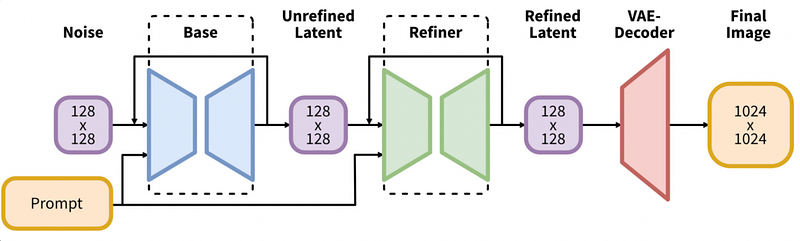
V. Use Cases
SDXL, with its remarkable capabilities, finds application in a diverse range of scenarios. Some of its notable use cases include, but are not limited to:
- Text-to-image synthesis: SDXL shines in translating textual descriptions into vivid, contextually relevant images, surpassing many of its predecessors in text-based image generation.
- Image editing and manipulation: The model’s versatility extends to image editing, enabling precise and creative adjustments to images with ease.
- Data augmentation for computer vision tasks: SDXL serves as a valuable tool for augmenting datasets in computer vision applications, enhancing the diversity and richness of training data.
- Artistic image creation: For artists and creators, SDXL offers a broad spectrum of artistic styles, empowering them to experiment, innovate, and produce images that align with their unique visions.
VI. Performance Metrics
SDXL’s performance is a testament to its capabilities and impact. It underwent rigorous evaluation on various datasets, including ImageNet, COCO, and LSUN. The results demonstrated that SDXL achieves performance levels that are competitive with state-of-the-art image generation models, including BigGAN and StyleGAN2. The evaluation was enriched with ablation studies that dissected the contributions of different components of the model to its overall performance.
To assess the quality of images generated by SDXL, the evaluation employed standard image quality metrics, including:
- Fréchet Inception Distance (FID): Measuring the distance between the distributions of real and generated images in the feature space of a pre-trained Inception network.
- Inception Score (IS): Gauging the diversity and quality of generated images based on the output of the same network.
- Learned Perceptual Image Patch Similarity (LPIPS): Quantifying the perceptual similarity between the generated and real images, grounded in the output of a pre-trained VGG network.
VII. Advantages
SDXL’s remarkable performance isn’t just theoretical; it translates into tangible advantages for users and applications. These include:
- Improved Text Generation: SDXL stands out for its ability to produce more readable and contextually relevant text within images, surpassing previous AI image generation models in this regard.
- Better Human Anatomy: The model exhibits fewer issues in rendering human anatomy, resulting in more accurate and lifelike representations of people in the generated images.
- Diverse Artistic Styles: SDXL offers a versatile palette of artistic styles, allowing users to explore and customize image outputs according to their preferences and creative requirements.
- Short Prompt Understanding: SDXL excels in comprehending and responding effectively to shorter prompts, streamlining content generation and saving valuable time for users.
- State-of-the-art Performance: On benchmark datasets such as ImageNet, COCO, and LSUN, SDXL achieves state-of-the-art performance, reinforcing its position as a leader in the realm of image generation.

Code Implementation with Stable Diffusion eXtended Learning (SDXL)
In the realm of generative models, the fusion of stability and diversity in image generation has reached new heights with the advent of Stable Diffusion eXtended Learning (SDXL). SDXL, an evolution of stable diffusion models, has garnered attention for its advanced techniques that make it possible to generate high-quality images with remarkable stability, control, and diversity. In this section, we will delve into a practical code implementation of SDXL for image generation. By the end of this section, you’ll have a clearer understanding of how to harness the power of SDXL to create stunning images with precision and versatility.

Step 1: Install and Import Libraries
!pip install diffusers==0.20.2 transformers==4.33.0 accelerate==0.22.0 xformers==0.0.20
!apt update && apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/175141 -d /workspace/model -o sdxl10ArienmixxlAsian_v30Pruned.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/185812 -d /workspace/model -o sdxl-DevlishPhotoRealism.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/174609 -d /workspace/model -o sdxl-unstable-diffusers-yamermix.safetensors
from diffusers import StableDiffusionXLPipeline, EulerAncestralDiscreteScheduler, AutoPipelineForText2Image
from compel import Compel, DiffusersTextualInversionManager,ReturnedEmbeddingsType
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
import torch
import os
import cv2
import numpy as np
import time
n_samples = 5
model_safetensors = {
"version5" : "sdxl-DevlishPhotoRealism.safetensors" ,
"version6" : "sdxl-unstable-diffusers-yamermix.safetensors" ,
"version7" : "sdxl10ArienmixxlAsian_v30Pruned.safetensors"
}
# Let's download the SDXL textual inversion embeddings
file = hf_hub_download("dn118/unaestheticXL", filename="unaestheticXLv31.safetensors")
state_dict = load_file(file)
def txt2img (model_name: str ) -> None :
model_fname = model_safetensors[model_name]
pipe = AutoPipelineForText2Image.from_pretrained(
f "safetensors/{model_fname}" ,
load_safety_checker= False ,
add_watermarker=False,
use_safetensors=True,
#extract_ema=True,
torch_dtype=torch.float16
)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.load_textual_inversion(state_dict["clip_g"], token="unaestheticXLv31", text_encoder=pipe.text_encoder_2, tokenizer=pipe.tokenizer_2)
pipe.load_textual_inversion(state_dict["clip_l"], token="unaestheticXLv31", text_encoder=pipe.text_encoder, tokenizer=pipe.tokenizer)
pipe.to( "cuda" )
#pipe.enable_model_cpu_offload()
prompt = "(high resolution)++, 8k+, photorealistic+, attractive, highly detailed, photo of pretty Japanese woman, short hair"
negative_prompt = "unaestheticXLv31, (Worst Quality)++, (low quality)+"
compel = Compel(tokenizer=[pipe.tokenizer, pipe.tokenizer_2] ,
text_encoder=[pipe.text_encoder, pipe.text_encoder_2],
returned_embeddings_type=ReturnedEmbeddingsType.PENULTIMATE_HIDDEN_STATES_NON_NORMALIZED,
requires_pooled=[False, True])
conditioning, pooled = compel([prompt])
neg_conditioning, neg_pooled = compel([negative_prompt])
os.makedirs(model_name, exist_ok= True )
for i in range (n_samples):
seed = 1000000 * (i + 1 )
generator = torch.manual_seed(seed)
image = pipe(
prompt_embeds=conditioning,
pooled_prompt_embeds=pooled,
negative_prompt_embeds=neg_conditioning,
negative_pooled_prompt_embeds=neg_pooled,
generator=generator,
num_inference_steps= 25 ,
width= 1024 ,
height= 1024 ,
).images[ 0 ]
image.save(os.path.join(model_name, f "{i}.png" ))
def stack () -> None :
os.makedirs( "stack_image" , exist_ok= True )
print ( " -> " .join(model_safetensors.keys()))
for i in range (n_samples):
images_list = []
for key in model_safetensors.keys():
images_list.append(cv2.imread(os.path.join(key, f "{i}.png" )))
stack_image = np.hstack(images_list)
cv2.imwrite(os.path.join( "stack_image" , f "{i}.png" ), stack_image)
if __name__ == "__main__" :
start = time.time()
for model in model_safetensors:
txt2img(model)
stack()
end = time.time()
print (f "Processing time: {end - start:.5f} seconds" )
Conclusion
In conclusion, stable diffusion models have emerged as a promising approach for image generation, offering the invaluable combination of stability, high-quality results, and a rich diversity of creative possibilities. The choice of a particular model should be guided by the specific requirements of the task at hand, and the considerations of architectural variations, training methods, and performance metrics are pivotal in making that choice.
As we’ve journeyed through the world of stable diffusion models, we’ve discovered their transformative potential in reshaping the landscape of image generation. However, it’s important to note that this field is in a constant state of evolution. Ongoing research and innovation are likely to yield even more sophisticated models in the future, pushing the boundaries of what is achievable.
As the field continues to advance, we can anticipate stable diffusion models playing a crucial role in a multitude of applications, spanning from the realms of art and entertainment to the critical domains of healthcare and beyond. These models are not merely tools; they are catalysts for the creative and practical endeavors that define our future. In a world where images speak volumes, stable diffusion models are the eloquent storytellers, poised to shape the visual narratives of tomorrow.

“Stay connected and support my work through various platforms:
- GitHub: For all my open-source projects and Notebooks, you can visit my GitHub profile at https://github.com/andysingal. If you find my content valuable, don’t hesitate to leave a star.
- Patreon: If you’d like to provide additional support, you can consider becoming a patron on my Patreon page at https://www.patreon.com/AndyShanu.
- Medium: You can read my latest articles and insights on Medium at https://medium.com/@andysingal.
- The Kaggle: Check out my Kaggle profile for data science and machine learning projects at https://www.kaggle.com/alphasingal.
- Hugging Face: For natural language processing and AI-related projects, you can explore my Huggingface profile at https://huggingface.co/Andyrasika.
- YouTube: To watch my video content, visit my YouTube channel at https://www.youtube.com/@andy111007.
- LinkedIn: To stay updated on my latest projects and posts, you can follow me on LinkedIn. Here is the link to my profile: https://www.linkedin.com/in/ankushsingal/."
Requests and questions: If you have a project in mind that you’d like me to work on or if you have any questions about the concepts I’ve explained, don’t hesitate to let me know. I’m always looking for new ideas for future Notebooks and I love helping to resolve any doubts you might have.
Remember, each “Like”, “Share”, and “Star” greatly contributes to my work and motivates me to continue producing more quality content. Thank you for your support!
Resources:
- https://huggingface.co/docs/diffusers/main/en/using-diffusers/textual_inversion_inference
- https://github.com/damian0815/compel
- https://clarifai.com/stability-ai/stable-diffusion-2/models/stable-diffusion-xl
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.





