Exploring Sequence-to-Sequence Models : Understanding the power of Encoder and Decoder Architecture
Welcome to our journey into the world of sequence-to-sequence models! In this blog series, we’ll delve into the fascinating realm of Encoder and Decoder architecture, uncovering their immense power in understanding and generating sequential data. From language translation to text summarization, sequence-to-sequence models have revolutionized various fields by seamlessly capturing the dependencies within sequential data.

What is Sequential Data ?
Sequential data refers to any data that occurs in a specific order or sequence. This can include a wide range of information, such as time-series data, text data, audio signals, or even genetic sequences. Here are a few examples:
- Text Data: Sentences, paragraphs, or documents are examples of sequential data. Each word appears in a specific order and contributes to the overall meaning of the text.
- Time-Series Data: Stock prices, temperature measurements, or sensor readings over time are examples of sequential data. The values are recorded in a specific chronological order.
- Audio Signals: Sound recordings or speech data are sequential in nature. The sequence of audio samples represents the waveform of the sound.
High Level Overview of Encoder Decoder Architecture :
If we thought encoder decoder architecture as a machine translation model, then the encoder-decoder architecture functions as follows : the encoder receives input data token by token, processing each element to capture its contextual information.
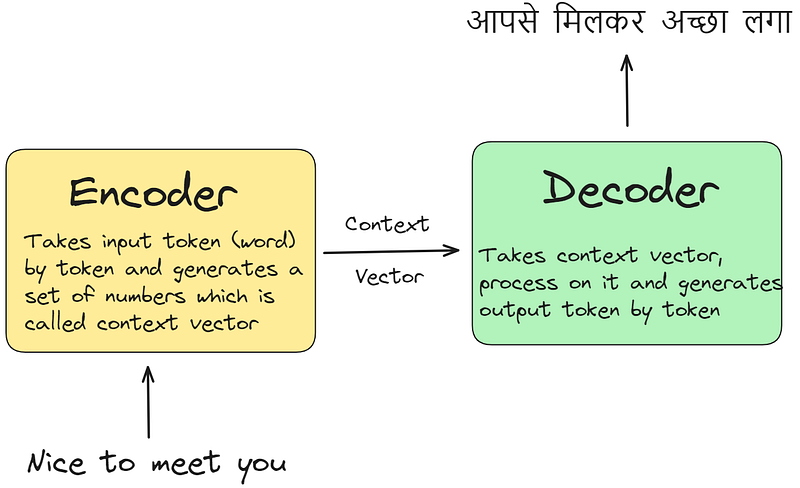
Through this process, it generates a comprehensive context vector. Subsequently, the decoder utilizes this context vector to generate the output sequence, such as a translation into another language (e.g., Hindi).
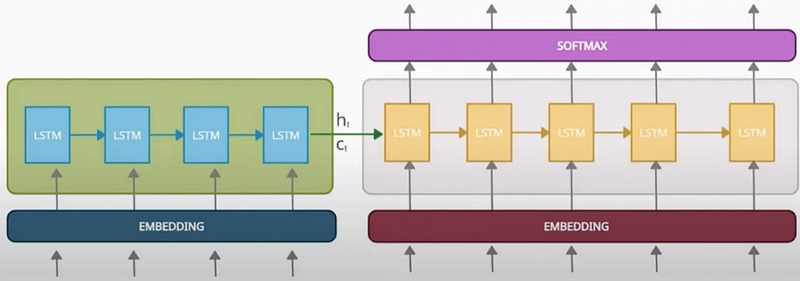
Brief overview of Encoder and Decoder Architecture :
Inside the encoder, we typically employ LSTM or GRU cells instead of simple RNNs because they are better at capturing long-range dependencies in sequences, thanks to their ability to mitigate the vanishing gradient problem and maintain long-term memory. In the diagram below, we unfold the LSTM cell across four timestamps.
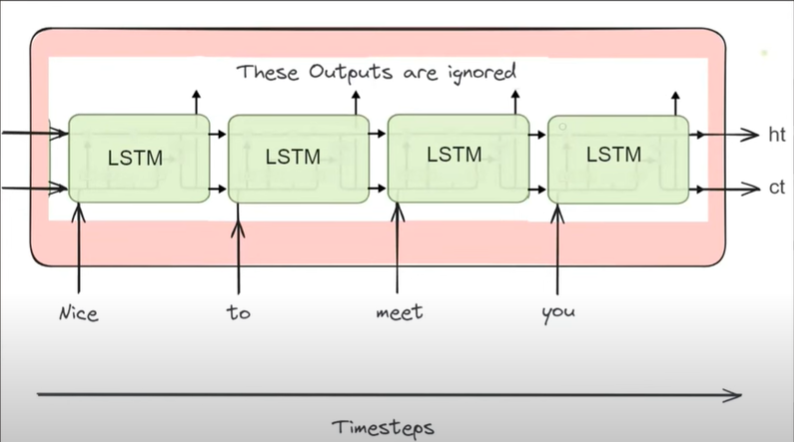
For example, at t=0, we pass the word ‘Nice’ through the LSTM cell, which generates hidden state and cell state values. Similarly, at t=1, ‘to’ is passed, at t=2, ‘meet’, and at t=3, ‘you’. Finally, the LSTM cell produces a context vector by combining the hidden and cell states. This process encapsulates how the encoder operates, efficiently capturing the contextual information of the input sequence.
Inside the decoder, we also utilize LSTM or GRU cells. Initially, we pass the exact same values of the hidden state (ht) and cell state (ct) from the last timestamp of the encoder. Additionally, we introduce a special symbol, ‘
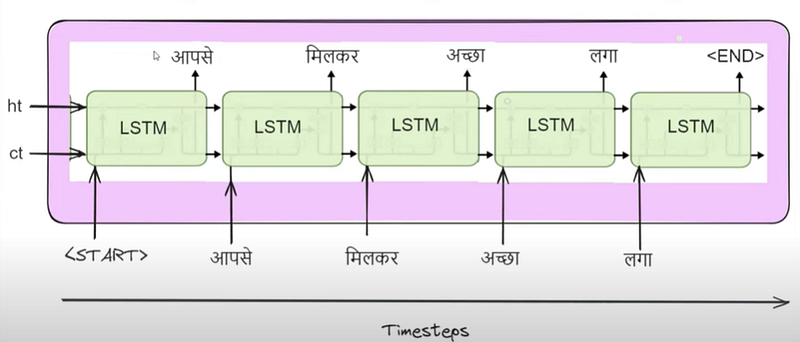
Subsequently, at t=1, this output is fed back into the LSTM, generating ‘मिलकर’, and this process continues. For instance, at t=2, ‘अच्छा’ is generated, and at t=3, ‘लगा’. Finally, when the LSTM encounters the special symbol ‘
Training Mechanism: Forward and Backward Propagation in Encoder and Decoder Architecture :
Below are diagrams illustrating the training mechanism in the encoder-decoder architecture. To begin, we convert our dataset into the required format to initiate training.

Now, we input the first sentence ‘Think it’ into the encoder. It traverses through the LSTM layer, and ultimately, the encoder yields its context vector. This vector, accompanied by a special symbol ‘
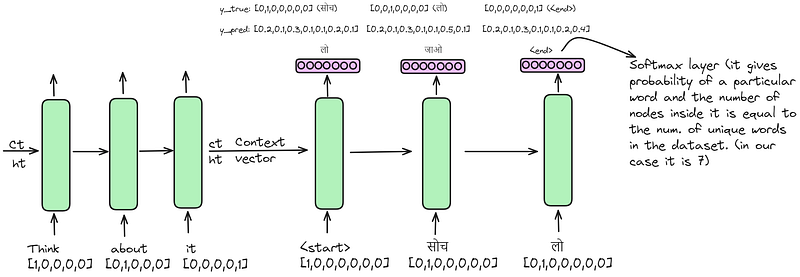
After completing the forward propagation for the first sentence, our next step is to calculate the loss function. We then adjust the gradient values and update the parameters of the encoder and decoder accordingly. This process iterates for each sentence in our dataset until all sentences have been processed. Once this is done, our training is complete, and our model is trained.

Once training is complete, we move on to the prediction phase. In the diagram below, I’ll demonstrate how predictions are made. Unlike during training, where correct outputs are passed to subsequent timestamps in the decoder section, during prediction, we feed the output of one timestamp to the next, regardless of its accuracy. Since we lack labels during prediction, this iterative process continues until we encounter the special symbol ‘
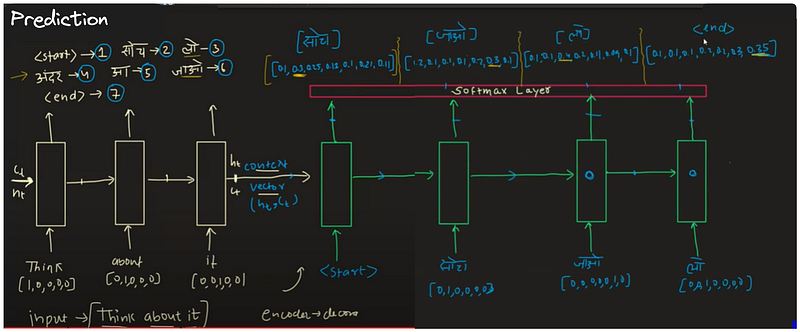

The diagram above illustrates that even though the model makes mistakes, it can still achieve high accuracy. Despite occasional errors in the generated output, the overall performance of the model remains satisfactory.
Improvements in Encoder Decoder Architecture :
1. Adding Embedding Layer:
The embedding layer converts input tokens into dense vector representations, allowing the model to learn meaningful representations of words or tokens in the input sequence.
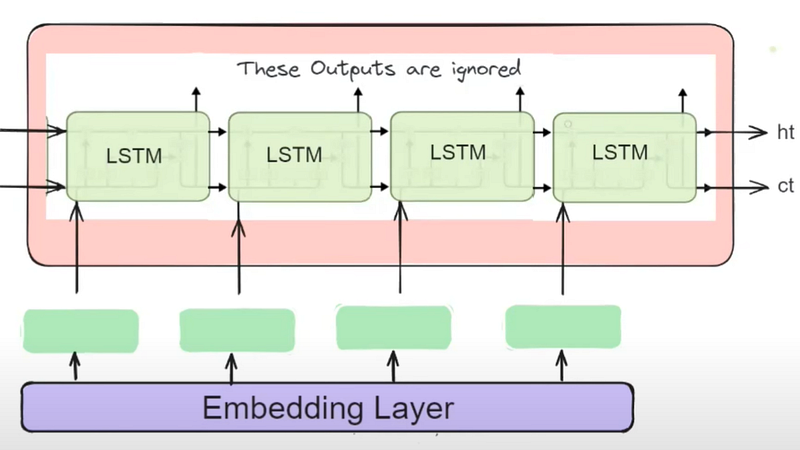
By using a trainable embedding layer and exploring techniques such as pre-trained word embeddings or contextual embeddings, we can enrich the input representations, enabling the model to capture nuanced semantic and syntactic information more effectively. This enhancement facilitates better understanding and generation of sequential data.
2. Use of Deep LSTMs :
LSTMs are recurrent neural network (RNN) variants known for their ability to capture long-range dependencies in sequential data. Deepening the LSTM layers enables the model to learn hierarchical representations of the input and output sequences, leading to improved performance.
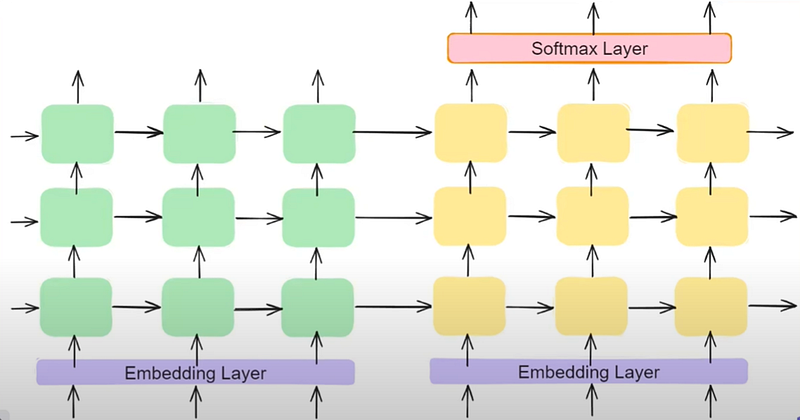
Increasing the depth of the LSTM layers and incorporating techniques like residual connections or layer normalization help mitigate issues like vanishing gradients and facilitate the training of deeper networks. These enhancements empower the model to learn more complex patterns and dependencies in the data, resulting in better sequence generation and understanding.
3. Reverse the input :
Reversing the input sequence in machine translation, such as English to Hindi or English to French conversion, has shown to enhance model performance in some cases by aiding in capturing long-range dependencies and mitigating vanishing gradient issues.
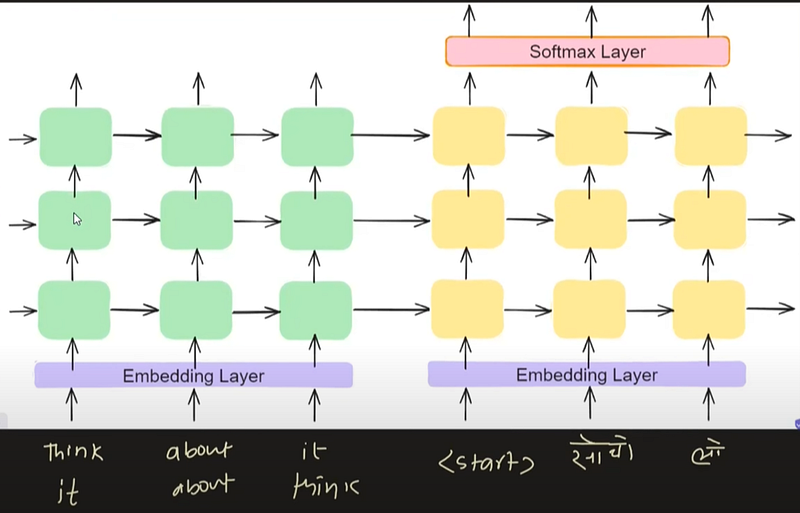
However, its effectiveness can vary depending on linguistic characteristics and dataset complexity, and it may not consistently improve performance across all scenarios. Careful evaluation and experimentation are necessary to determine whether reversing the input sequence is beneficial for a specific task and dataset.
I hope you are now understood the concept of Encoder Decoder . Now, If you go through the famous research paper “Sequence to Sequence Learning with Neural Networks,” by Ilya Sutskever, then you will definitely understood the paper concept very well. Below I summarize what inside the paper :
- Application to Translation : The model focused on translating English to French, demonstrating the effectiveness of sequence to sequence learning in neural machine translation.
- Special End of Sentence Symbol : Each sentence in the dataset was terminated with a unique end of sentence symbol (“
”), enabling the model to recognize the end of a sequence. - Dataset : The model was trained on a subset of 12 million sentences, comprising 348 million French words and 304 million English words, taken from a publicly available dataset.
- Vocabulary Limitation : To manage computational complexity, fixed vocabularies for both languages were used, with 160,000 most frequent words for English and 80,000 for French. Words not in these vocabularies were replaced with a special “UNK” token.
- Reversing input sequences : The input sentences were reversed before feeding them into the model, which was found to significantly improve the model’s learning efficiency, especially for longer sentences.
- Word Embeddings : The model used a 1000 dimensional word embedding layer to represent input words, providing dense, meaningful representations of each word.
- Architecture Details : Both the input(encoder) and output(decoder) models had 4 layers, with each layer containing 1000 units, showcasing a deep LSTM-based architecture.
- Output Layer and Training : The output layer employed a SoftMax function to generate the probability distribution over the largest vocabulary. The model was trained end to end with these settings.
- Performance — BLEU Score : The model achieved a BLEU score of 34.81, surpassing the basefile Statistical Machine Translation system’s score of 33.30 on the same dataset, marking a significant advancement in neural machine translation.
I trust this blog has enriched your understanding of the encoder decoder architecture. If you found value in this content, I invite you to stay connected for more insightful posts. Your time and interest are greatly appreciated. Thank you for reading!



