
Exploring Paddle-OCR: Performance on Diverse Data Formats and Multilingual Text
This blog stems from my curiosity to research the performance of Paddle-OCR, a robust and versatile optical character recognition (OCR) toolkit. Paddle-OCR offers an array of features and capabilities for extracting text from images and documents, and I was eager to explore its capabilities and limitations.

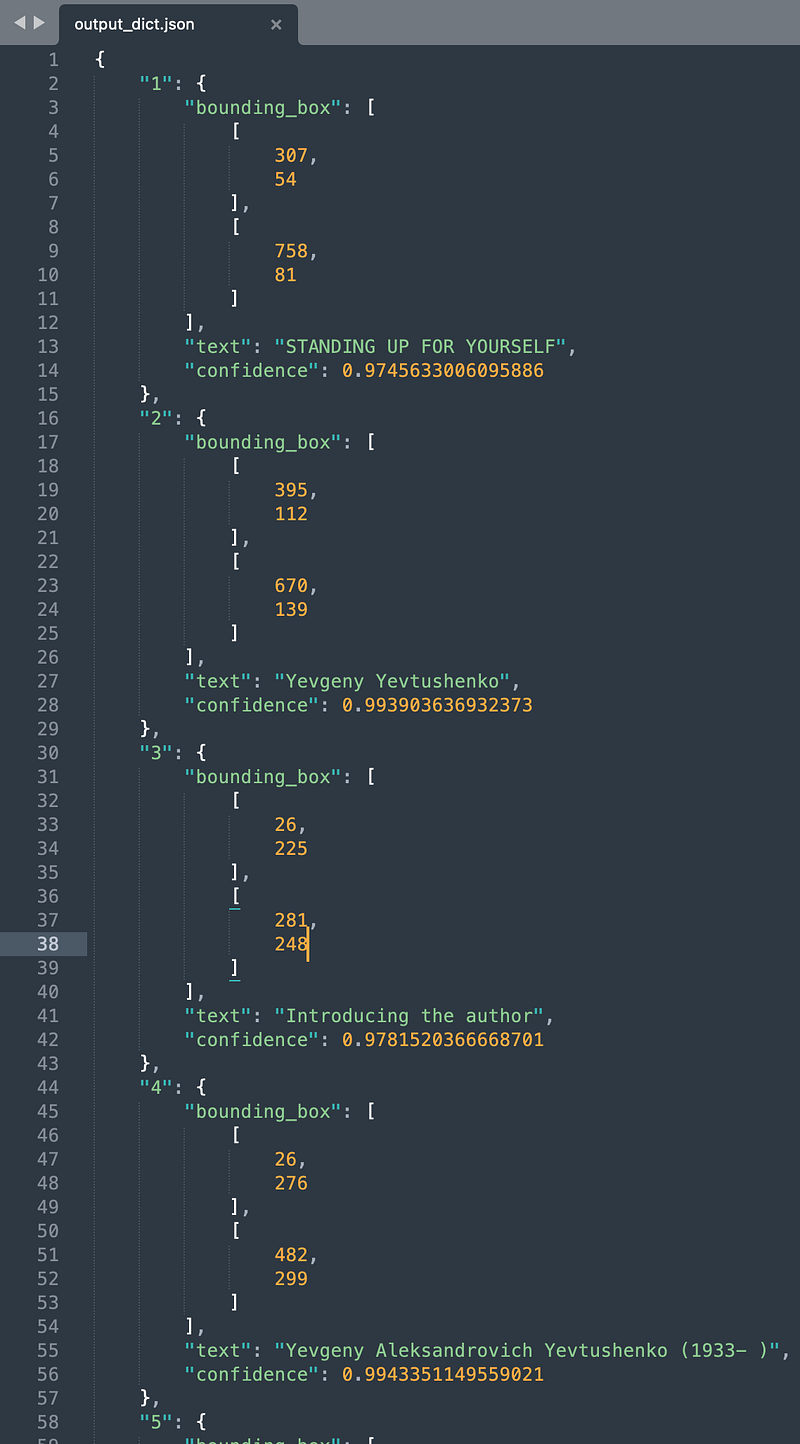
config_dict = {
"alpha": 1.0,
"benchmark": False,
"beta": 1.0,
"cls_batch_num": 6,
"cls_image_shape": '3, 48, 192',
"cls_model_dir": '/Users/prajendr/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer',
"cls_thresh": 0.9,
"cpu_threads": 10,
"crop_res_save_dir": './output',
"det": True,
"det_algorithm": 'DB',
"det_box_type": 'quad',
"det_db_box_thresh": 0.6,
"det_db_score_mode": 'fast',
"det_db_thresh": 0.3,
"det_db_unclip_ratio": 1.5,
"det_east_cover_thresh": 0.1,
"det_east_nms_thresh": 0.2,
"det_east_score_thresh": 0.8,
"det_limit_side_len": 960,
"det_limit_type": 'max',
"det_model_dir": '/Users/prajendr/.paddleocr/whl/det/en/en_PP-OCRv3_det_infer',
"det_pse_box_thresh": 0.85,
"det_pse_min_area": 16,
"det_pse_scale": 1,
"det_pse_thresh": 0,
"det_sast_nms_thresh": 0.2,
"det_sast_score_thresh": 0.5,
"draw_img_save_dir": './inference_results',
"drop_score": 0.5,
"e2e_algorithm": 'PGNet',
"e2e_char_dict_path": './ppocr/utils/ic15_dict.txt',
"e2e_limit_side_len": 768,
"e2e_limit_type": 'max',
"e2e_model_dir": None,
"e2e_pgnet_mode": 'fast',
"e2e_pgnet_score_thresh": 0.5,
"e2e_pgnet_valid_set": 'totaltext',
"enable_mkldnn": False,
"fourier_degree": 5,
"gpu_mem": 500,
"help": '==SUPPRESS==',
"image_dir": None,
"image_orientation": False,
"ir_optim": True,
"kie_algorithm": 'LayoutXLM',
"label_list": ['0', '180'],
"lang": 'en',
"layout": True,
"layout_dict_path": None,
"layout_model_dir": None,
"layout_nms_threshold": 0.5,
"layout_score_threshold": 0.5,
"max_batch_size": 10,
"max_text_length": 25,
"merge_no_span_structure": True,
"min_subgraph_size": 15,
"mode": 'structure',
"ocr": True,
"ocr_order_method": None,
"ocr_version": 'PP-OCRv3',
"output": './output',
"page_num": 0,
"precision": 'fp32',
"process_id": 0,
"re_model_dir": None,
"rec": True,
"rec_algorithm": 'SVTR_LCNet',
"rec_batch_num": 6,
"rec_char_dict_path": '/Users/prajendr/opt/anaconda3/envs/paddle_env/lib/python3.8/site-packages/paddleocr/ppocr/utils/en_dict.txt',
"rec_image_inverse": True,
"rec_image_shape": '3, 48, 320',
"rec_model_dir": '/Users/prajendr/.paddleocr/whl/rec/en/en_PP-OCRv3_rec_infer',
"recovery": False,
"save_crop_res": False,
"save_log_path": './log_output/',
"scales": [8, 16, 32],
"ser_dict_path": '../train_data/XFUND/class_list_xfun.txt',
"ser_model_dir": None,
"show_log": True,
"sr_batch_num": 1,
"sr_image_shape": '3, 32, 128',
"sr_model_dir": None,
"structure_version": 'PP-StructureV2',
"table": True,
"table_algorithm": 'TableAttn',
"table_char_dict_path": None,
"table_max_len": 488,
"table_model_dir": None,
"total_process_num": 1,
"type": 'ocr',
"use_angle_cls": True,
"use_dilation": False,
"use_gpu": False,
"use_mp": False,
"use_npu": False,
"use_onnx": False,
"use_pdf2docx_api": False,
"use_pdserving": False,
"use_space_char": True,
"use_tensorrt": False,
"use_visual_backbone": True,
"use_xpu": False,
"vis_font_path": './doc/fonts/simfang.ttf',
"warmup": False
}[
{"dt_boxes num": 26, "elapse": 0.5838239192962646},
{"cls num": 26, "elapse": 0.2507450580596924},
{"rec_res num": 26, "elapse": 8.794885873794556}
]
[
{"dt_boxes num": 73, "elapse": 0.5404520034790039},
{"cls num": 73, "elapse": 0.5514864921569824},
{"rec_res num": 73, "elapse": 18.835140705108643}
]
[
{"dt_boxes num": 53, "elapse": 0.5971817970275879},
{"cls num": 53, "elapse": 0.40938377380371094},
{"rec_res num": 53, "elapse": 9.467683792114258}
]
[
{"dt_boxes num": 89, "elapse": 0.5390758514404297},
{"cls num": 89, "elapse": 0.6855661869049072},
{"rec_res num": 89, "elapse": 12.754459857940674}
]List of languages supported by Paddle-ocr
languages_dict = {
'ch': 'Chinese',
'en': 'English',
'korean': 'Korean',
'japan': 'Japanese',
'chinese_cht': 'Traditional Chinese',
'ta': 'Tamil',
'te': 'Telugu',
'ka': 'Kannada',
'latin': 'Latin',
'arabic': 'Arabic',
'cyrillic': 'Cyrillic',
'devanagari': 'Devanagari',
'hi': 'Hindi'
}
[
{"dt_boxes num": 248, "elapse": 0.544651985168457},
{"cls num": 248, "elapse": 1.7124524116516113},
{"rec_res num": 248, "elapse": 16.015892028808594}
]
[
{"dt_boxes num": 248, "elapse": 0.544651985168457},
{"cls num": 248, "elapse": 1.7124524116516113},
{"rec_res num": 248, "elapse": 16.015892028808594}
]
[
{"dt_boxes num": 15, "elapse": 0.44008684158325195},
{"cls num": 15, "elapse": 0.12907814979553223},
{"rec_res num": 15, "elapse": 1.1196460723876953}
]
[
{"dt_boxes num": 28, "elapse": 0.4684789180755615},
{"cls num": 28, "elapse": 0.21653985977172852},
{"rec_res num": 28, "elapse": 7.516796827316284}
]A quick overview of py-tesseract performance in Figure 1
data = pytesseract.image_to_data(img, output_type=pytesseract.Output.DICT)
{"dt_bboxes_num":329}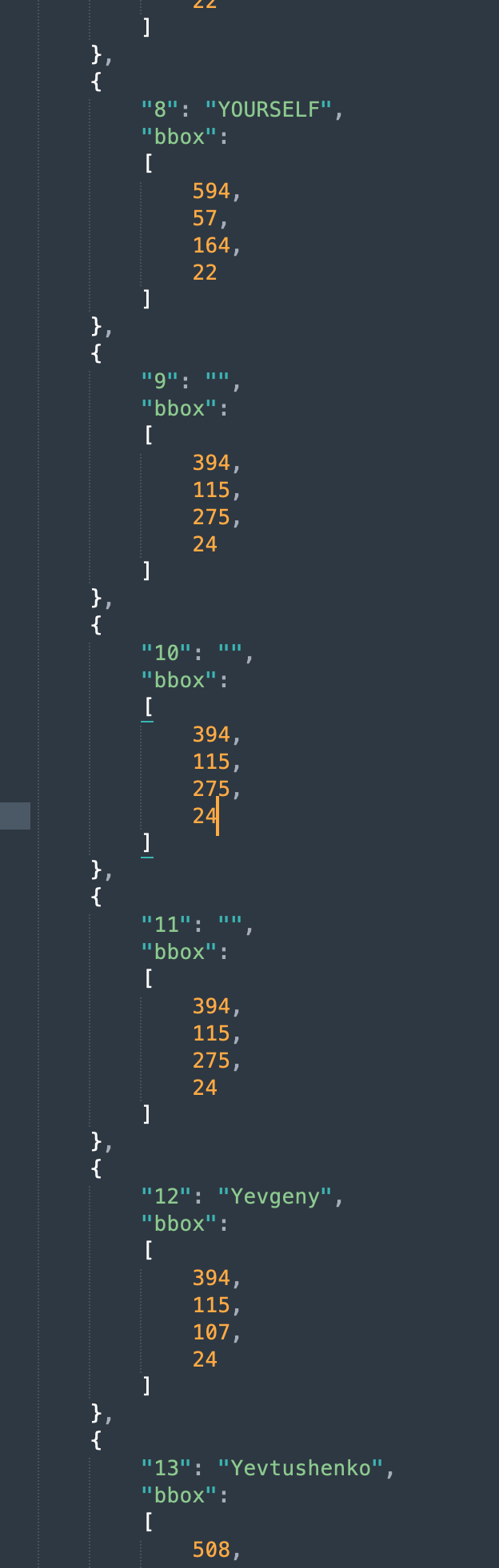

{"dt_bboxes_num":250}Conclusion :
I wanted to see how Paddle-OCR performs on different types of data. I have added a few academic documents in English and an academic document for a regional language Hindi. You may want to experience the fun I had while running all of these images through the PP-OCRv3 version of Paddle-OCR.
I have added two results from py-tesseract also for a fair comparison with their latest mode.
None of the above images were pre or post-processed.




