
Llama, Alpaca and Vicuna: “Chatgpt” running on your laptop
Large language models have made a revolutionary impact in the field of AI, and their influence is expected to be long-lasting.
In the past few months, we have witnessed a significant breakthrough in this field, with OpenAI’s ChatGPT showcasing impressive performance.
As a result, fierce competition has emerged among companies and researchers to develop the most advanced conversational AI to compete against OpenAI leadership.
Google’s Bard was fine-tuned on PaLM-E, and a Multi-modal LLM with GPT-4 has been developed. Additionally, Meta developed its own LLM called LLaMa.
However, recently, there has been an influx of information related to the latest LLMs, particularly since Meta decided to share the architecture of LLaMa with the research community for a non-commercial purpose only…
Until the LLaMa’s weights leaked, allowing anyone to run these high-performing models directly on your laptop!
In this article, I will take you through the development of LLMs built on LLaMa architecture: Alpaca and Vicuna.
I will then introduce the work behind llama.ccp that has made it possible to run these LLMs directly on your devices.

Meta releases LLaMA, their foundational LLM!
LLaMa was released on the 24th of February 2023 by Meta’s team.
The initial goal of Meta was to give access to this performing LLM to the academic research community. Four versions of LLaMa were provided: 7B, 13B, 33B, and 65B parameters.
Like other large language models, LLaMA works by taking a sequence of words as an input and predicts a next word to recur(sively generate text.
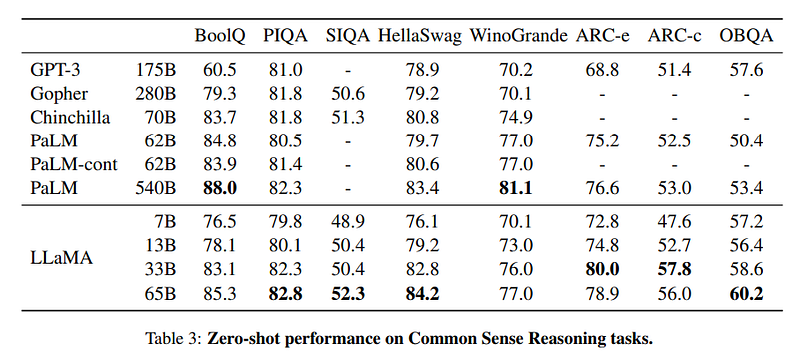
As the paper suggests, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA65B is competitive with the best models, Chinchilla-70B (DeepMind) and PaLM-540B (Google).
The LLaMa model was released publicly for the research community for a non-commercial purpose only (Facebook Research GitHub). It is worth noting that only the untrained model was made available.
However, the trained weights that result from the expensive and extensive training process are accessible through a Google form for research purposes.
For anyone curious, it took 2048 A100 GPUs to train LLaMa, each GPU costs roughly $15k, facebook probably gets some sort of discount. That’s a $30Mil if you want to train at that scale. [source]
Apart from having the necessary resources for training LLaMa, having a large and clean dataset is also crucial.
LLaMA 65B and LLaMA 33B were trained on 1.4 trillion tokens. The smallest model, LLaMA 7B, is trained on one trillion tokens. [source]
With this pre-trained LLM, it is then possible to fine-tune it to obtain a replica of ChatGPT, a conversationalist model capable of having human interactions.
There is, however, a major constraint: obtaining the data needed to fine-tune the model without spending millions of dollars on human intervention, as OpenAI did to train InstructGPT, the model behind ChatGPT.
Stanford found a way. And they spent less than 600$ to fine-tune LLaMa.
Alpaca: the “LLaMa ChatGPT”
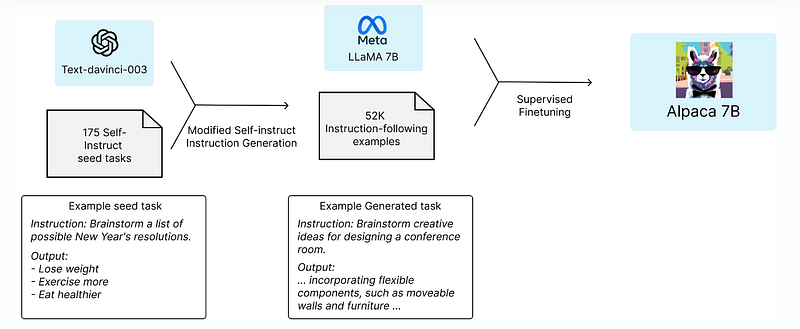
Stanford introduced Alpaca-7B, a model fine-tuned from the LLaMA-7B model on 52K instruction-following demonstrations.

The main challenge regarding instruction-following models like ChatGpt (Da-Vinci-003, Bard, etc…) is the production of false information, propagating social stereotypes, and producing toxic language.
To address this issue, OpenAI spent millions of dollars to evaluate “bad” answers from their model using human feedback (RLHF) to create InstructGPT, the model behind ChatGpt.
Unfortunately, OpenAI has not released the dataset used to train InstructGPT, which makes it challenging to replicate this kind of model.
Stanford found a way to work around this issue!
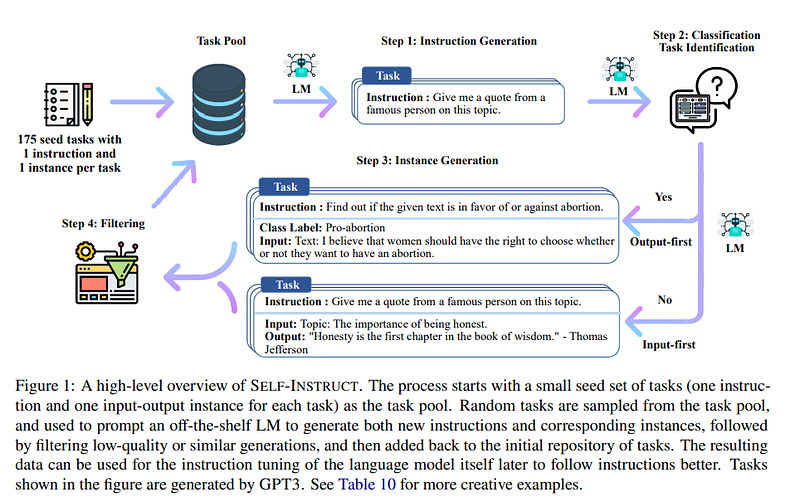
Instead of requiring human feedback to train the model, they used Da-Vinci-003 from OpenAI, which was built on InstructGPT, to generate 52K instruction-following examples from 175 self-instructed seed tasks, in the style of self-instruct.
The Self-Instruct process is an iterative bootstrapping algorithm that starts with a seed set of manually-written instructions and uses them to prompt the language model to generate new instructions and corresponding input-output instances. These generations are then filtered to remove low-quality or similar ones, and the resulting data is added back to the task pool. This process can be repeated multiple times, resulting in a large collection of instructional data that can be used to fine-tune the language model to follow instructions more effectively. [Source]
According to the Stanford team, generating the 52K instruction-following demonstrations cost around $500, while training the model on 8 80GB A100 GPUs cost approximately $100 and took 3 hours.
Despite the small size of their model, it was reported that Alpaca and Da-Vinci-003 have similar performance regarding the quality of the answers (human evaluation).
These findings have paved the way for smaller LLMs that can perform exceptionally well compared to existing large models.
Vicuna: an outperforming model?
Vicuna is built on LLaMa's original model, and it is said that it performs almost as well as OpenAI ChatGPT or Google Bard on instruction-following tasks, with an overall cost of training of 300$!

Two versions have been released: 7B and 13B parameters for non-commercial use (as all LLaMa models).
One of the main upgrades compared to previous models is the increase of the max context length, from 512 with Alpaca to 2048 tokens.
The model was trained using approximately 70K user-shared conversations from ShareGPT.
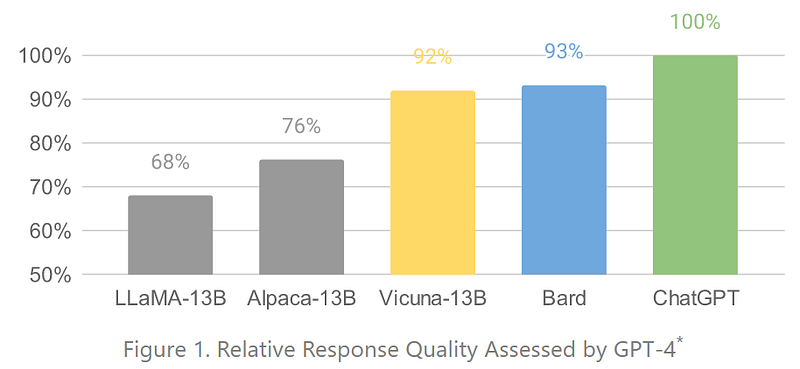
It has to be mentioned that the method used to evaluate Vicuna’s performance is based on GPT-4 evaluation, which can be contested.
The authors suggest that building an evaluation system for chatbots remains an open question for further research.
One drawback of the models we have discussed thus far is that they are still large and memory-intensive, requiring the use of GPUs to accelerate computation.
In other words, the cost of deploying these models is relatively high, both in terms of energy consumption and financial expenses. For example, the Vicuna model uses a longer maximum context length than Alpaca, which results in higher GPU memory requirements.
In theory, only corporations that have access to large-scale infrastructure to store and run these models have an advantage.
Furthermore, just thinking about using these models on devices, like laptops or even smartphones, is not even conceivable.
Until now…
LLama.ccp: an LLM in pure C/C++
Georgi Gerganov’s work took LLMs to the next level by creating a code capable of transforming popular instruction-following LLMs, originally coded in Python, into C/C++ language: llama.ccp.
C/C++ is a low-level programming language that does not require machine compilation, resulting in faster execution times.
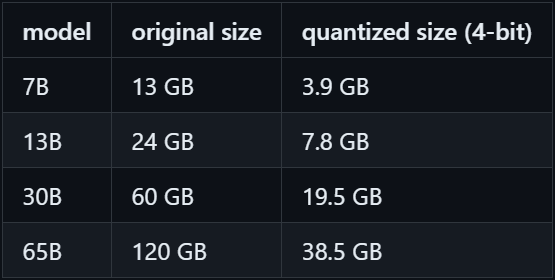
Also, the code supports 4-bit quantization.
Integer quantization is an optimization strategy that converts 32-bit floating-point numbers (such as weights and activation outputs) to the nearest 8-bit fixed-point numbers. This results in a smaller model and increased inferencing speed.
The work of Justine Tunney improved the work of Gerganov by modifying llama.cpp to load weights using mmap() instead of C++ standard I/O. That enabled us to load LLaMA 100x faster using half as much memory.
Read her blog post to get more details.
Thanks to the amazing work of the contributors to this project, in addition to the leakage of the weights we have discussed in the introduction of this article, it is now possible to run any Instruction-following model (like Alpaca or Vicuna) directly on our laptop!
For instance, Gerganov was able to run 4 different models on his Macbook on an M1 Pro 32GB.
How to run a LLaMa model on your laptop?
It is now possible for you to run your own LLMs model using llama.ccp on your own device.
I encourage you to explore the impressive work of Martin Thissen. You can find his Medium article about running Vicuna on your own CPU/GPU.

I hope you have found this article informative and have gained a better understanding of the latest developments in AI.
Personally, I found writing this article to be a rewarding experience, as it allowed me to conduct my own research and stay up-to-date with the latest advancements in the field.
If you want to know when I publish a new article, feel free to subscribe to my newsletter.
You can also follow me on Linkedin, I post content daily.
Happy coding!
Sources
- Introducing LLaMA: A foundational, 65-billion-parameter large language model
- Alpaca: A Strong, Replicable Instruction-Following Model
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
- LLaMa.ccp github repository by ggerganov
- Justine Tunney’s blog post about mmap()
- Vicuna on Your CPU & GPU: Best Free Chatbot According to GPT-4, by Martin Thissen




