Exploring Data Warehouse Modeling Methodologies: Kimball, Inmon, and Data Vault
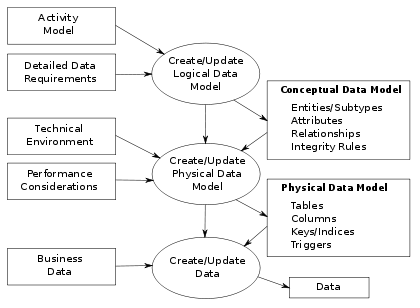
Data warehousing plays a critical role in modern businesses by facilitating data-driven decision-making and analytical insights. When designing a data warehouse, selecting the right modeling methodology is essential.
In this article, I will delve into three prominent data warehouse modeling methodologies: Kimball, Inmon, and Data Vault.
I’ll explore their characteristics, differences, and considerations to help you make an informed choice for your organization’s unique needs.
Read every story from Luís Oliveira (and thousands of other writers on Medium for a low price)
1. Data Warehouse
A data warehouse is a centralized data repository designed specifically for OLAP.
Data is extracted from multiple sources, transformed into a common format, and loaded into the data warehouse for analysis (ETL process).
Data warehouses are optimized for reading rather than writing data and are typically used for decision support and business intelligence purposes.
Advantages:
- Optimized for complex queries and analysis
- Improved data consistency and quality through data transformation and cleansing
- Supports business intelligence and decision-making
Disadvantages:
- Expensive to build and maintain
- Limited to structured data
- Time-consuming to load data
Examples of data warehouses include Amazon Redshift and Google BigQuery.
2. Data Warehouse Modeling Methodologies
2.1. Kimball Methodology: A Bottom-Up Approach
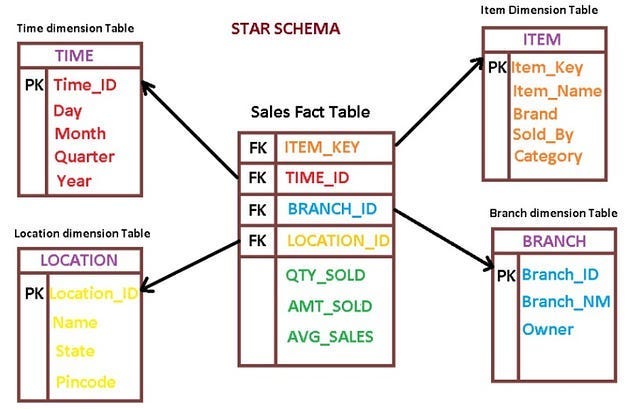
The Kimball methodology, often referred to as dimensional modeling, adopts a bottom-up approach that centers around designing the data warehouse based on business processes or subject areas. Key features of the Kimball methodology include:
- Utilization of star schema or snowflake schema to model data, with a focus on creating dimension and fact tables to support analysis.
- Renowned for its simplicity, flexibility, and ease of use, making it a popular choice for organizations looking to implement a data warehouse efficiently.
2.2. Inmon Methodology: A Top-Down Approach
The Inmon methodology, known as normalized modeling, follows a top-down approach, with a primary focus on designing the data warehouse around the data. Key characteristics of the Inmon methodology include:
- Adoption of a 3NF (third normal form) schema to model data, emphasizing the creation of a single integrated data model that supports the entirety of the organization’s reporting and analysis requirements.
- Distinguished for its data integrity, consistency, and data accuracy, making it an attractive choice for organizations with a strong emphasis on data quality.
2.3. Data Vault Methodology: A Hybrid Approach
The Data Vault methodology takes a hybrid approach, combining elements from both the Kimball and Inmon methodologies.
It features a hub-and-spoke architecture for modeling data and concentrates on creating separate entities for business processes, data sources, and data types.
The Data Vault methodology is known for its scalability, flexibility, and ability to handle complex data relationships.
If you are enjoying this article please don’t forget to clap or comment to support me!!!! Please 😊
2.4. Differences Between the Three Methodologies
While all three methodologies aim to facilitate effective data warehousing, they differ in several aspects:
- Approach: Kimball is a bottom-up approach, Inmon is top-down, and Data Vault represents a hybrid approach that combines elements of both.
- Schema: Kimball employs star or snowflake schemas, Inmon uses a 3NF schema, and Data Vault relies on a hub-and-spoke schema.
- Focus: Kimball centers on the business process or subject area, Inmon emphasizes the data, and Data Vault focuses on the relationships between the data.
- Flexibility: Kimball stands out for its flexibility, Inmon for its consistency, and Data Vault for its ability to handle complex data relationships.
- Complexity: Kimball is relatively simple, Inmon is more complex, and Data Vault is the most complex among the three methodologies.
2.5. Selecting the Right Methodology
The choice of methodology depends on the specific needs and requirements of the organization. Consider the following factors when making your decision:
- Business Needs: Assess your organization’s analytical needs, data integration requirements, and data quality expectations.
- Data Volume and Complexity: Consider the expected data size, data relationships, and the complexity of your data sources.
- Data Consistency and Accuracy: Evaluate the level of data consistency and accuracy required for your business operations.
- Project Complexity: Analyze the scope and complexity of your data warehousing project and the skills and expertise of your team.
Conclusion
Selecting the right data warehouse modeling methodology is crucial for building an effective and efficient data warehousing solution that aligns with your organization’s objectives.
By understanding the characteristics and differences of the Kimball, Inmon, and Data Vault methodologies and assessing your organization’s unique requirements, you can make an informed decision that sets the foundation for robust data-driven insights and informed decision-making.
Did you like this article? Follow me for more articles on Medium.
Read every story from Luís Oliveira (and thousands of other writers on Medium for a low price)



