
Exploring Classic Position Embeddings in Attention-based Models
Attention-based models, such as large language models, apply attention layers throughout their building blocks. Since attention layers typically lack positional information, it’s required to add extra transformations so the model can capture dependencies among tokens.
If you’re not a member yet, click this friend link to read the article.
Preliminary
The figure below illustrates the classic process of position embedding in transformer-based models. First, a sequence of tokens w_i are encoded into token embeddings x_i. Then, the self-attention layer take both the embedding x_i and position i as input to transform them into key, query, and value vectors through function f.
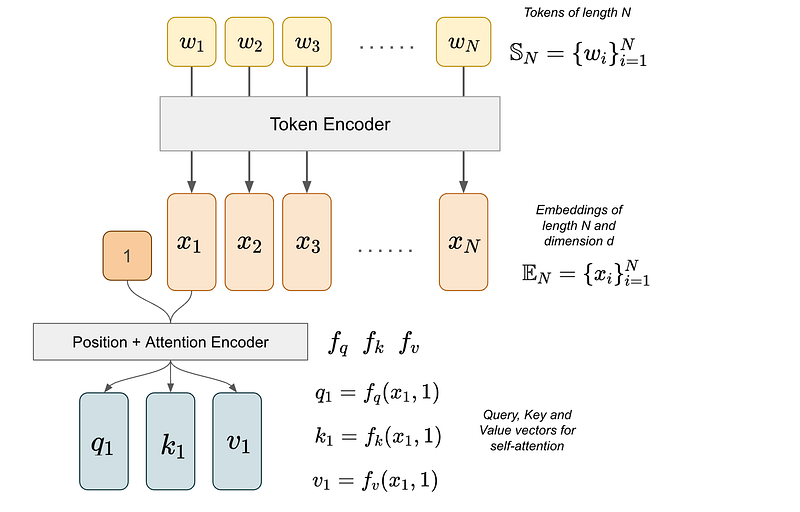
The question is: what kind of position and attention encoder function f do we use?
Absolute Position Embedding
A natural choice for the function f is to directly add position information to the token embedding before projecting it into q, k and v vectors.
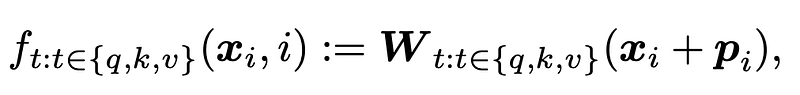
In the original paper of Transformer model, a sinusoidal position information is added, where i represents the i-th token in the sequence, and 2k and 2k+1 denote the indices of elements in the token embedding.
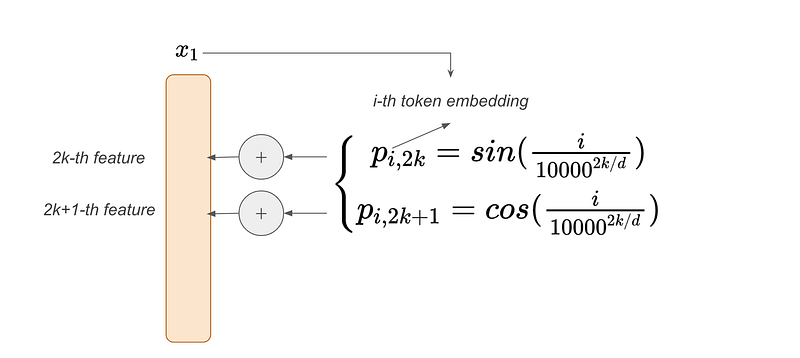
If you plot the position encoding values on the x-axis and use the y-axis to represent the feature indices within the embedding, you’ll observe an oscillating pattern.
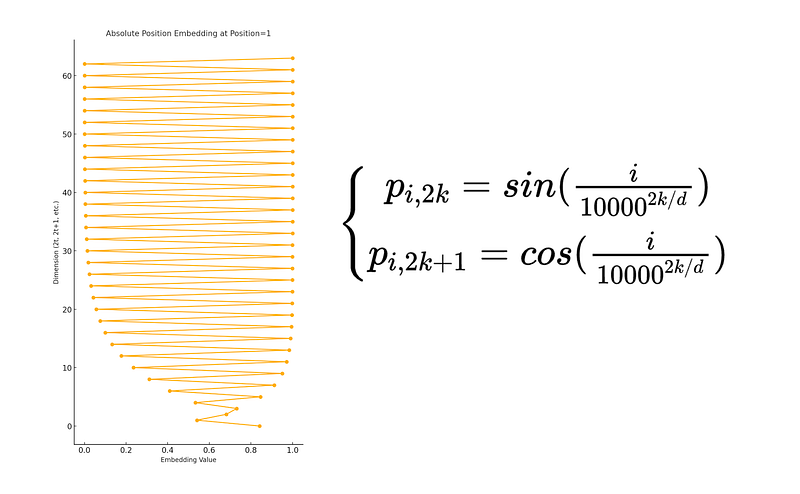
The entire process is illustrated in the following figure.
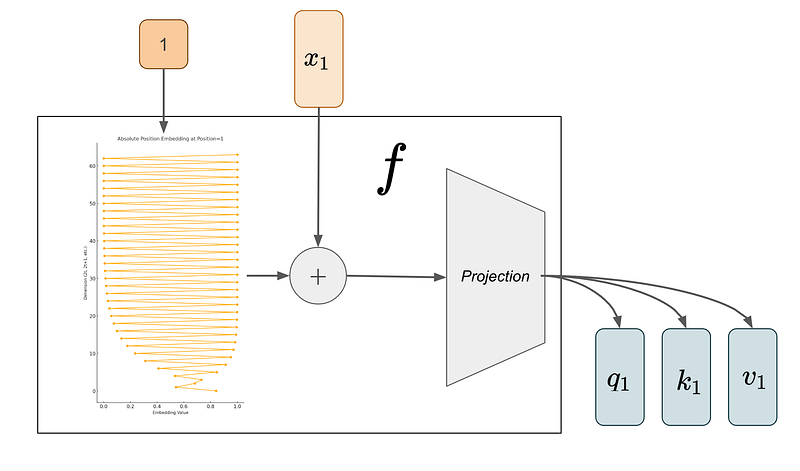
Relative Position Embedding
With relative position embedding, we consider relative distance between two tokens rather than the absolute position of toekens themselves.
First, we have to determine the relative position information r. While this can just be the distance between token m and token n, it is often paired with a clipping function, based on the assumption that relative position information is not useful beyond/below a certain threshold.
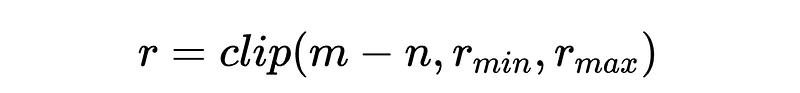
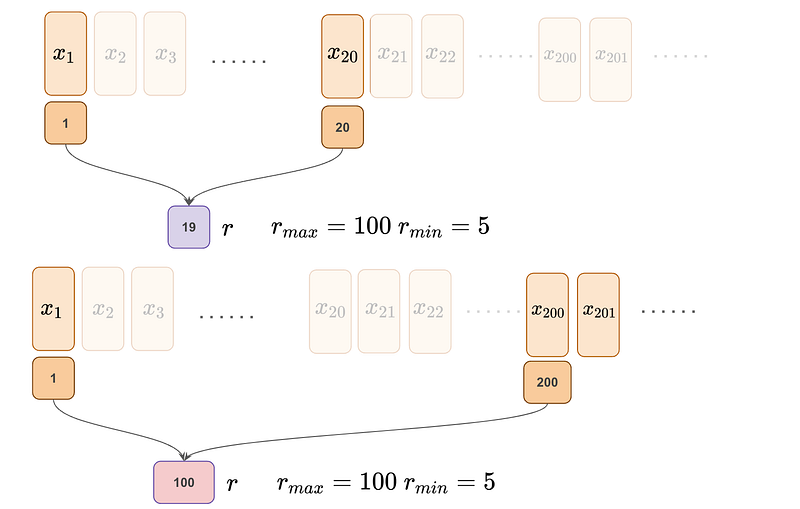
Trainable Relative Position Embedding
An example of relative position embedding comes from the paper Self-Attention with Relative Position Representations, shown in the figure below. Here, p^k and p^v are trainable position embeddings for the relative distance r.
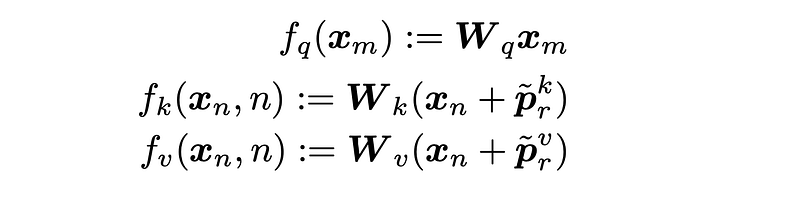
Mixed with Sinusoidal Relative Position Embedding
Another example comes from Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, which combines sinusoidal encodings with trainable encodings.
They begin with the standard approach used in absolute position embedding, where query and key vectors are formed by adding position encodings to token embeddings, followed by a projection.
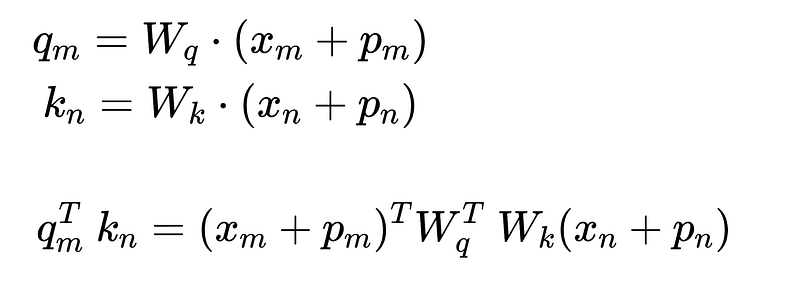
Then, they expand the equation to find out modifications that could make it a relative position function. The expansion results in four terms. The authors decide make the following changes:
- The absolute position of the key token (p_n) is replaced with a sinusoidal encoding, using the relative position index r = m-n.
- The absolute position of the query token (p_m) is replaced with trainable vectors u and v in the third and fourth term.
- They also introduce an additional key projection matrix ~W_k when handling the term related to the position encoding of the key token.

The replacement is somewhat complex, but it highlights the key idea that the query-key product can be interpreted as a combination of contextual terms (i.e. related to token embeddings themselves) and position terms.
Simple Combinations of Contextual Term and Position Bias
In the original paper of T5 model, the query-key product is further simplified as
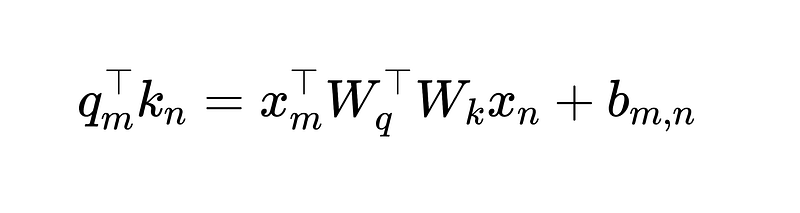
where b is a trainable position bias based on the positions m and n.
They also try to use different projection matrices for position terms and contextual terms:
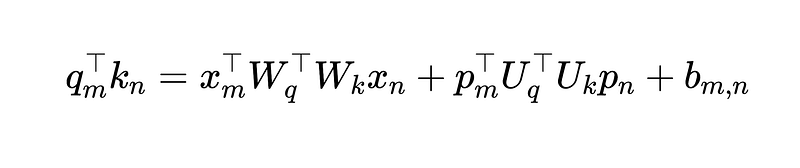
Only Cross Terms are Required
While in DeBERTa: Decoding-Enhanced BERT with Disentangled Attention, the authors argue that relative position information can only be fully captured through the cross terms in the product expansion (i.e., the product of token embeddings and position embeddings).
They do these changes:
- Start with the product form of the query and key vectors.
- Replace absolute position encoding with relative position encoding.
- Discard the final position product term.





