
Exploratory Data Analysis (EDA) using Python

“The field of exploratory data analysis was established with Tukey’s 1977 now-classic book Exploratory Data Analysis [Tukey-1977].”
Exploratory Data Analysis (EDA) is an approach to extract the information enfolded in the data and summarize the main characteristics of the data.EDA involves looking at and describing the data set from different angles and then summarizing it.
Today, this data pre-processing step is an essential one before starting statistical modeling or machine learning engines to ensure the correctness and effectiveness of data used.
Benefits of EDA:
1) It helps to clean the garbage from the dataset 2) Helps users to understand the relationship between each of the variables.
People spend more time on Exploratory data analysis and data visualization but time can be minimized through such auto visualization tools such as Pandas-Profiling, Sweetviz, Autoviz, and D-tale.
The whole process of EDA involves some steps which include statistical tests, visualize our data by creating different plots for it, Data quality check, quantitative tests, etc.
Data quality check: It can be done using pandas library function describe(),info() etc.
Statistical test: Pearson correlation, Spearman correlation, Kendall test, etc can be found using the stats library.
Quantitative Test: find the spread of numerical features, count of categorical features performed through the pandas library.
Visualization: Barplots, histograms, pie charts, scatter plots, etc are used.
But all this library can do this task in just a few lines of code automatically.
Sweetviz Library:
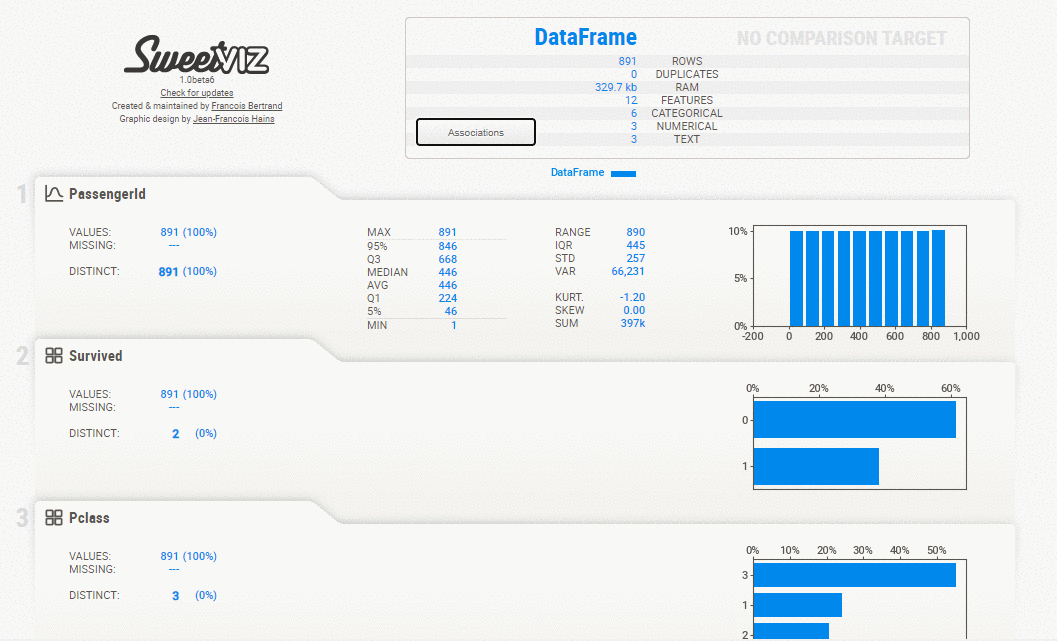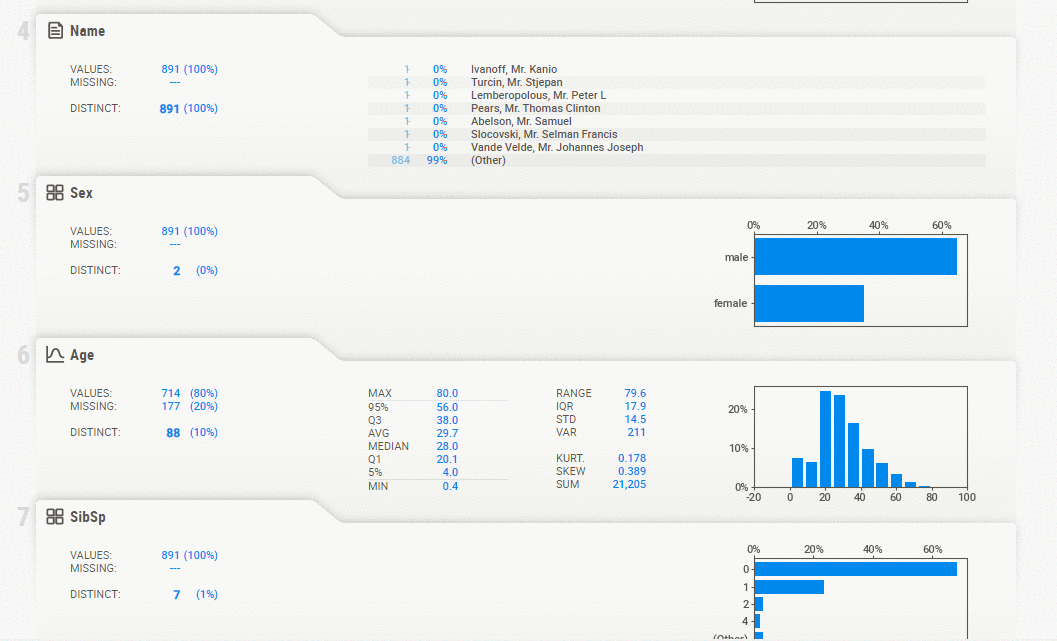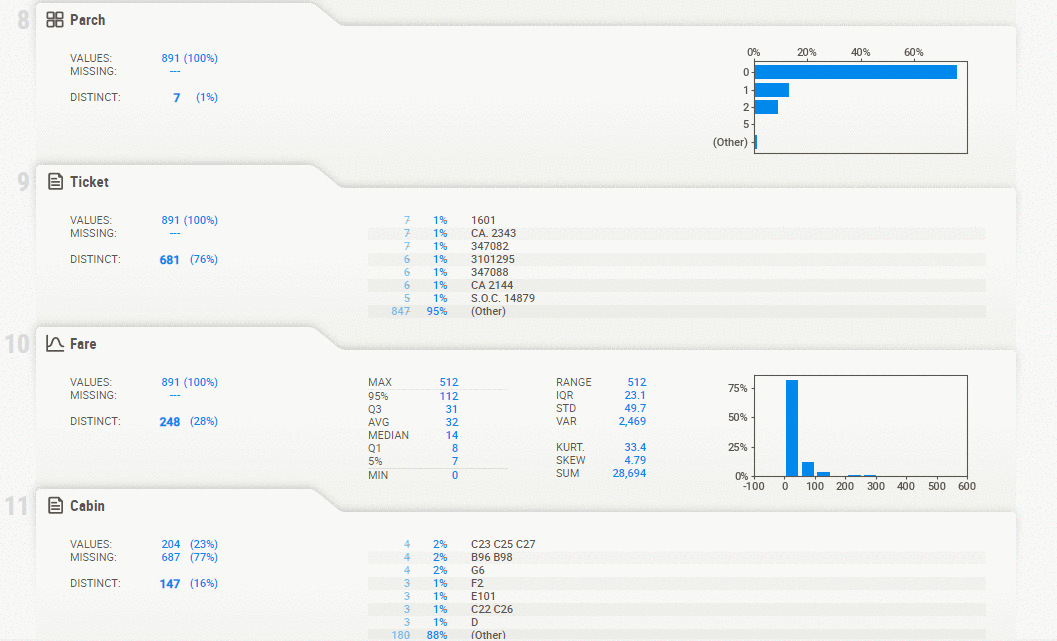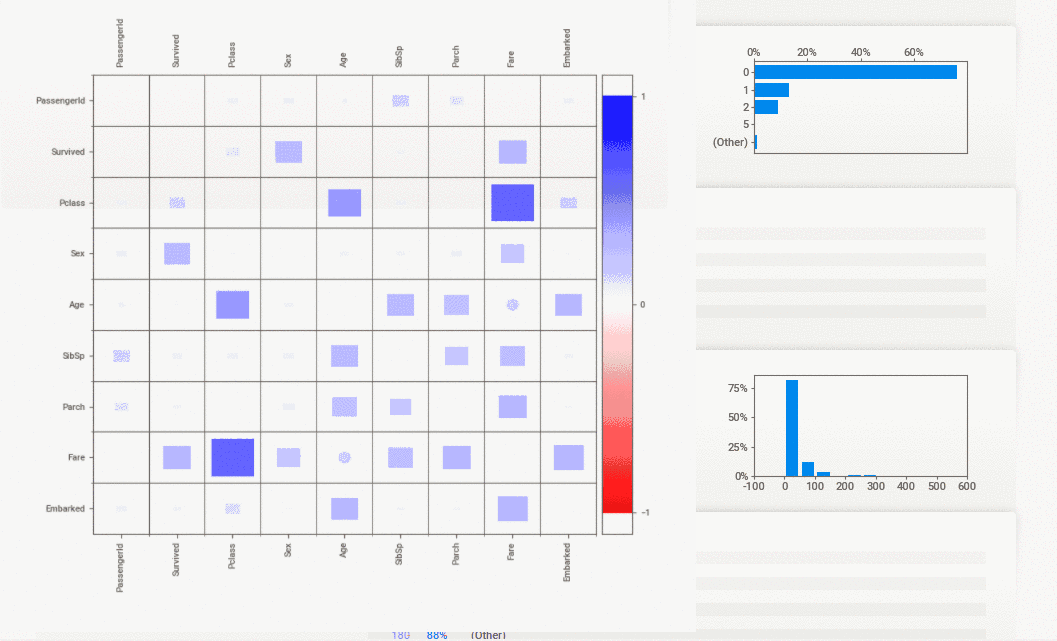
Sweetviz is an open-source python auto-visualization library that generates a report, exploring the data with the help of high-density plots. It not only automates the EDA but is also used for comparing datasets and drawing inferences from it. A comparison of two datasets can be done by treating one as training and the other as testing.
It generates a report having:
Overview of the dataset, variable properties, categorical associations, Numerical associations, Largest, smallest, or most frequent value for the dataset.
Dataset Name: Churn Prediction
Link:https://www.kaggle.com/shubh0799/churn-modelling
#Installing necessary packages!pip install sweetvizimport pandas as pdimport sweetviz as sv#EDA using Autovizsweet_report = sv.analyze(pd.read_csv("/content/Churn_Modelling.csv"))#Saving results to HTML filesweet_report.show_html('sweet_report.html')DTale library:
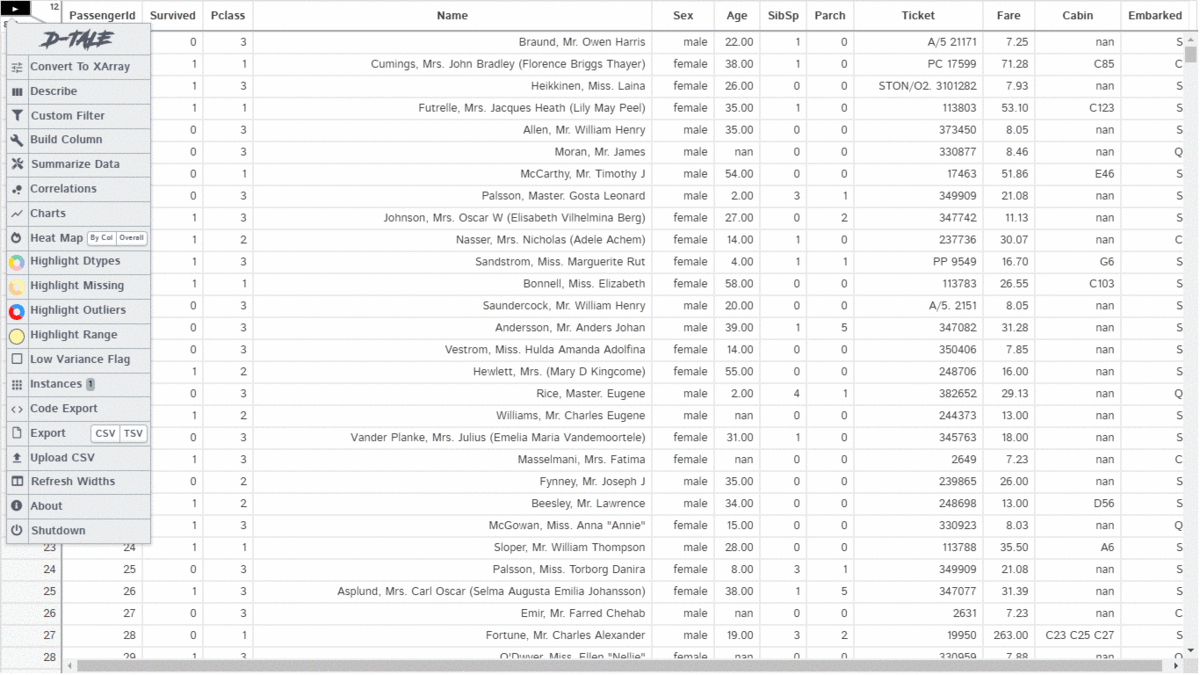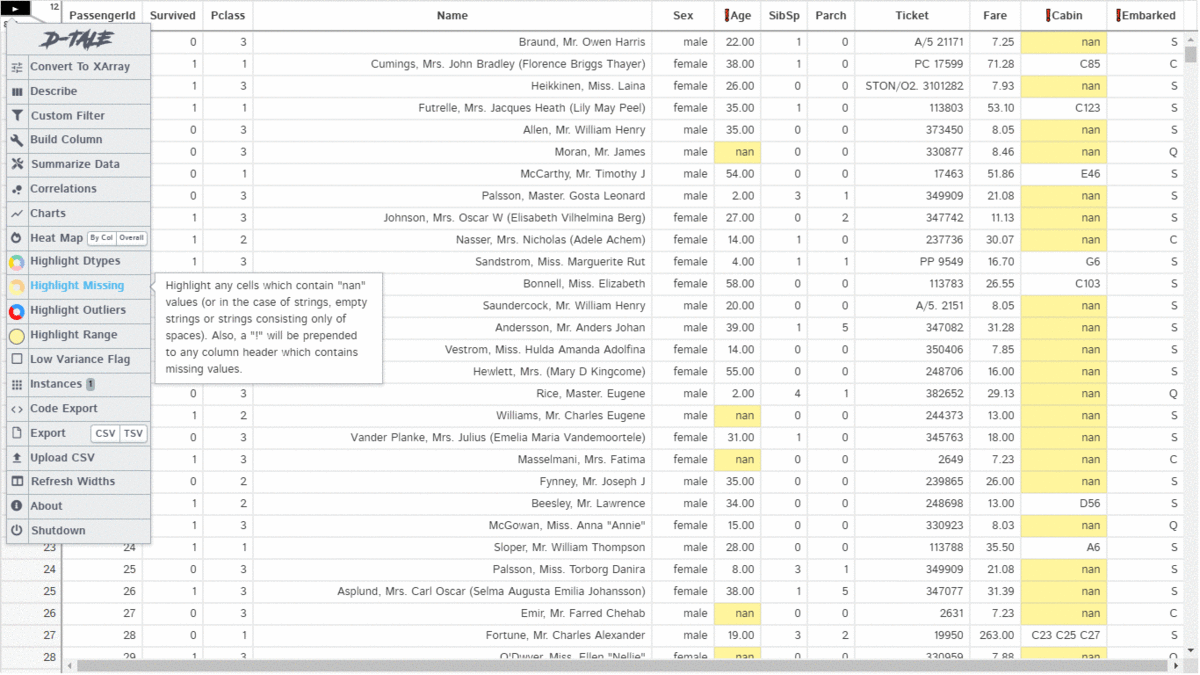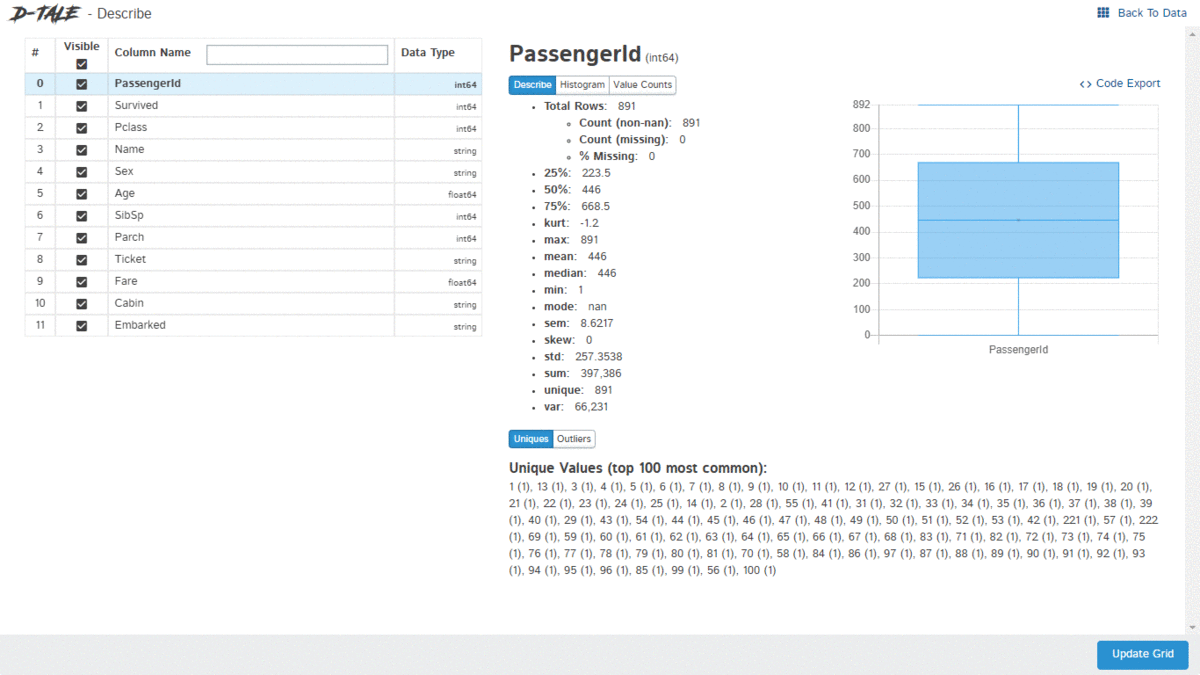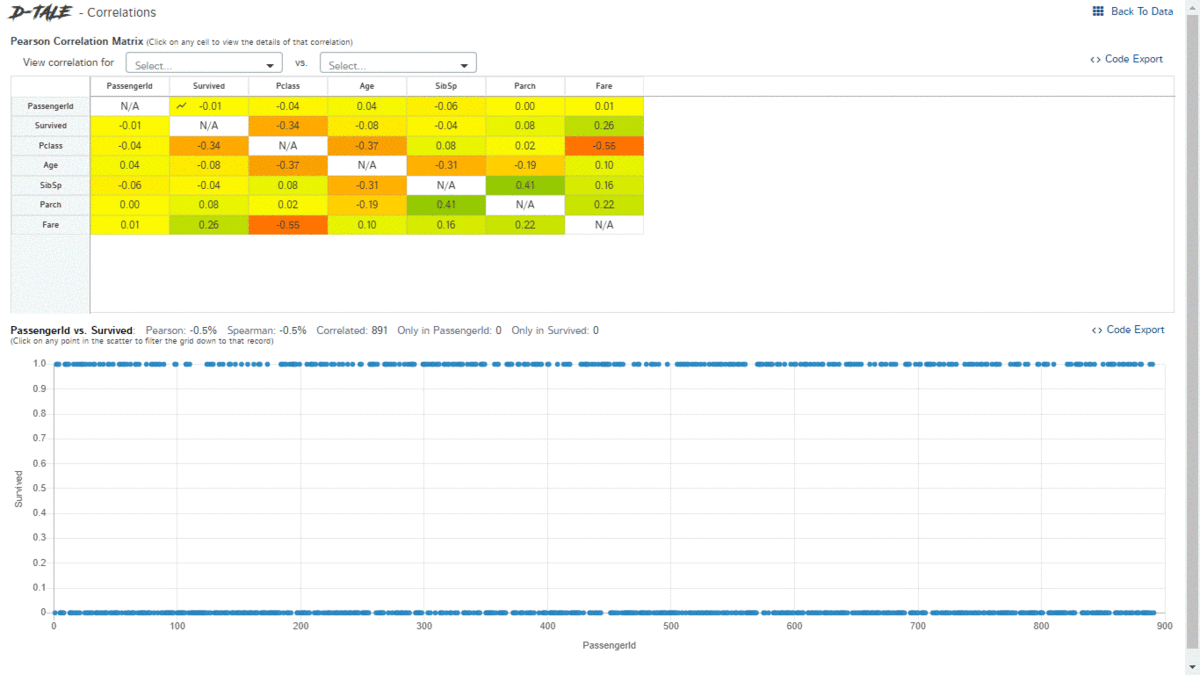
D-Tale is an open-source python auto-visualization library. It is one of the best auto data-visualization libraries. D-Tale helps you to get a detailed EDA of the data. It also has a feature of code export, for every plot or analysis in the report.
It Generates the report of having:
An overview of the dataset, Custom filters, Correlation, Charts, and Heatmaps, Highlight datatypes, missing values, ranges, Code export
Dataset Name: Churn Prediction
Link:https://www.kaggle.com/shubh0799/churn-modelling
#Installing necessary packages!pip install dtaleimport dtaleimport pandas as pddtale.show(pd.read_csv("/content/Churn_Modelling.csv"))“Exploratory data analysis is an attitude, a state of flexibility, a willingness to look for those things that we believe are not there, as well as the things we believe might be there.”