
Evaluation Driven Development, the Swiss Army Knife for RAG Pipelines
Using EDD to aid in choosing the right implementation strategy for your RAG pipelines

I love the concept of Evaluation Driven Development (EDD). The first time I heard it was from a tweet from Simon Suo, CTO of LlamaIndex. Coming from a Java/Spring development background, I am a big fan of TDD (Test Driven Development). EDD to RAG pipeline development is TDD to Java/Spring development.
LlamaIndex has been evolving rapidly since the beginning of the year and advanced exponentially, especially in the last few months. A colossal list of production-ready strategies has been offered for RAG pipelines. Navigating them all and figuring out which option is best for your RAG pipeline can be challenging.
Luckily, LlamaIndex also offers a comprehensive list of options in its Evaluation Modules to help you choose the right implementation strategy for your RAG pipeline based on your use case. I call this Evaluation Driven Development the Swiss army knife for your RAG pipelines.
In this article, we are going to build a multi-document RAG pipeline. We will apply the Evaluation Driven Development (EDD) methodology to decide which of the following implementation strategies is a better option for our multi-document RAG pipeline:
- Recursive retriever + document agent
- Metadata replacement + node sentence window
Why EDD?
EDD plays a critical role in the development of high-quality RAG pipelines by ensuring that the generated responses are accurate, relevant, and aligned with user expectations. EDD facilitates continuous improvement and optimization of your RAG pipelines. To summarize, EDD brings the following six main benefits.
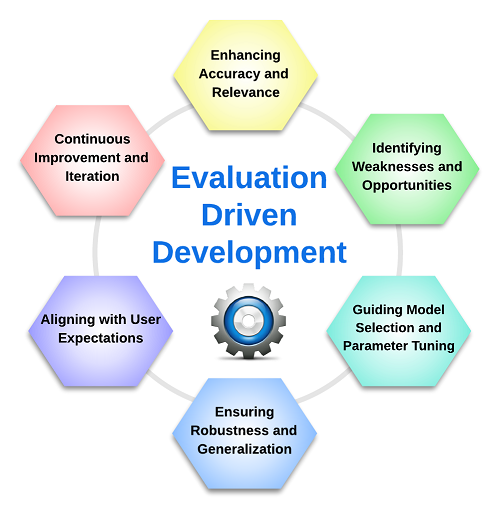
- Enhancing Accuracy and Relevance: EDD helps in identifying and addressing potential issues with the pipeline’s output, ensuring that the generated responses are accurate, relevant, and consistent with the provided context.
- Identifying Weaknesses and Opportunities: EDD facilitates the detection of areas where the pipeline can be improved, allowing developers to focus on specific aspects that require refinement. This continuous evaluation process leads to overall performance optimization.
- Guiding Model Selection and Parameter Tuning: By evaluating different models and parameter configurations, EDD guides the selection of the most suitable model architecture and hyperparameters for the specific task at hand.
- Ensuring Robustness and Generalization: EDD ensures that the pipeline performs consistently across a variety of input scenarios and data distributions, enhancing its robustness and generalization capabilities.
- Aligning with User Expectations: EDD helps in aligning the pipeline’s output with user expectations and requirements, ensuring that the generated responses are tailored to the specific needs of the target audience.
- Continuous Improvement and Iteration: EDD promotes a culture of continuous improvement and iteration, enabling developers to make informed decisions based on objective evaluation metrics.
EDD Methodology
We explored LlamaIndex’s Evaluation Module in a previous article, Exploring End-to-End Evaluation of RAG Pipelines. Since then, LlamaIndex has enhanced its Evaluation Modules to be more comprehensive in the following areas:
- Faithfulness: measure if the response from a query engine matches any source nodes.
- Relevancy: measure if the response and source nodes match the query.
- Guideline: evaluate a question-answer system given user-specified guidelines.
- Correctness: assess the relevance and correctness of a generated answer against a reference answer.
- Embedding similarity: evaluate the quality of a question-answer system via semantic similarity.
- Integration with DeepEval: unit test your LLMs with DeepEval and LlamaIndex integration.
- Question Generation: use
DatasetGeneratorto generate a list of questions that could be asked about your data. BatchEvalRunner: run a series of evaluations asynchronously.- Retrieval Eval: evaluate the quality of any Retriever module.
For our multi-document RAG pipeline evaluation, we are going to take the following steps:
- Use
DatasetGeneratorto auto-generate 30 evaluation questions. - Define evaluators for
faithfulnessandrelevancy. - Use
BatchEvalRunnerto asynchronously run evaluations of the responses from the two query engines from the two strategies. - Compare the evaluation results and choose the strategy that scores better.
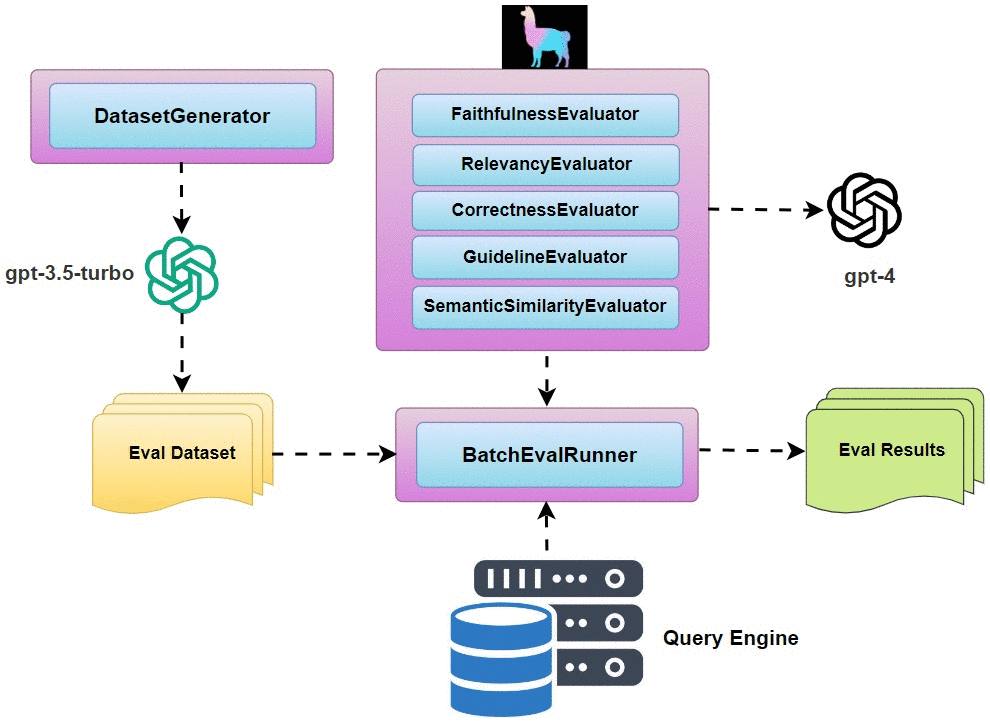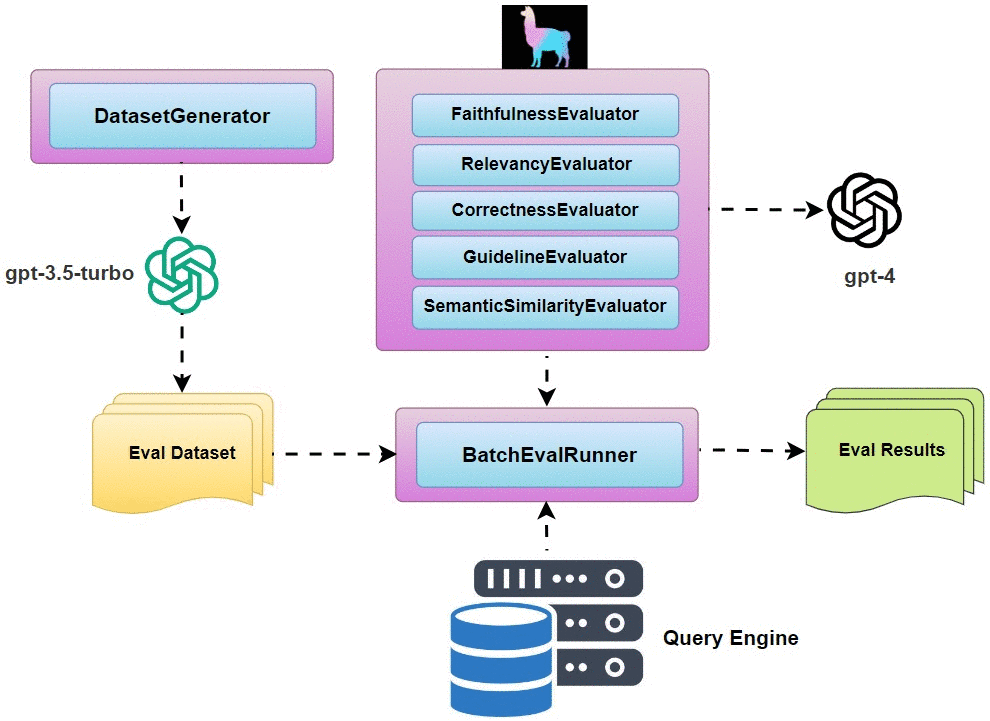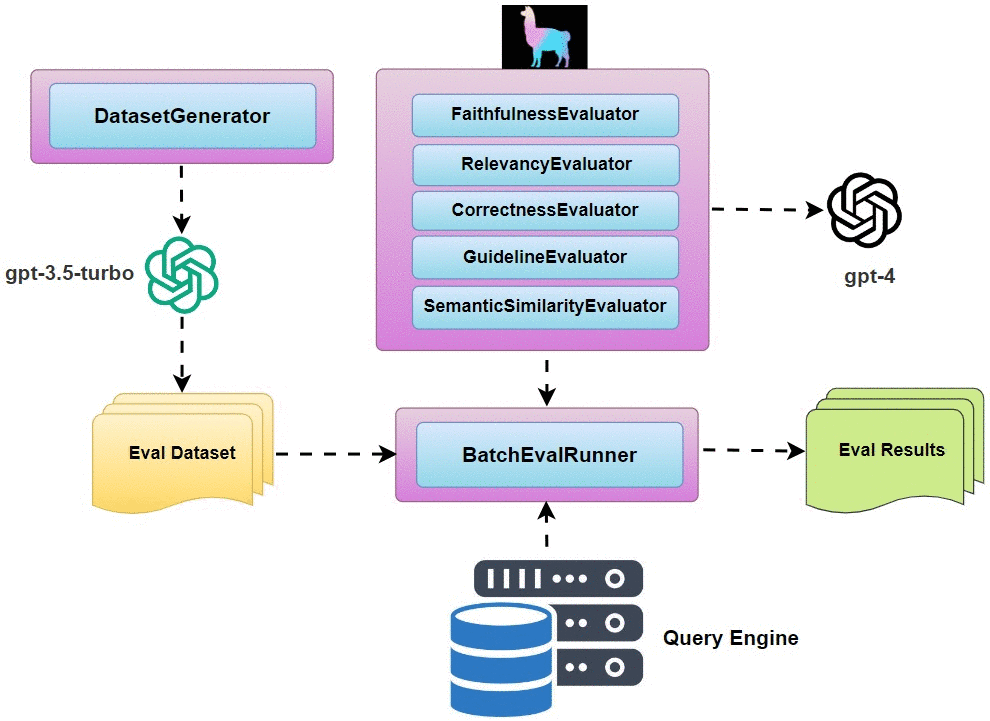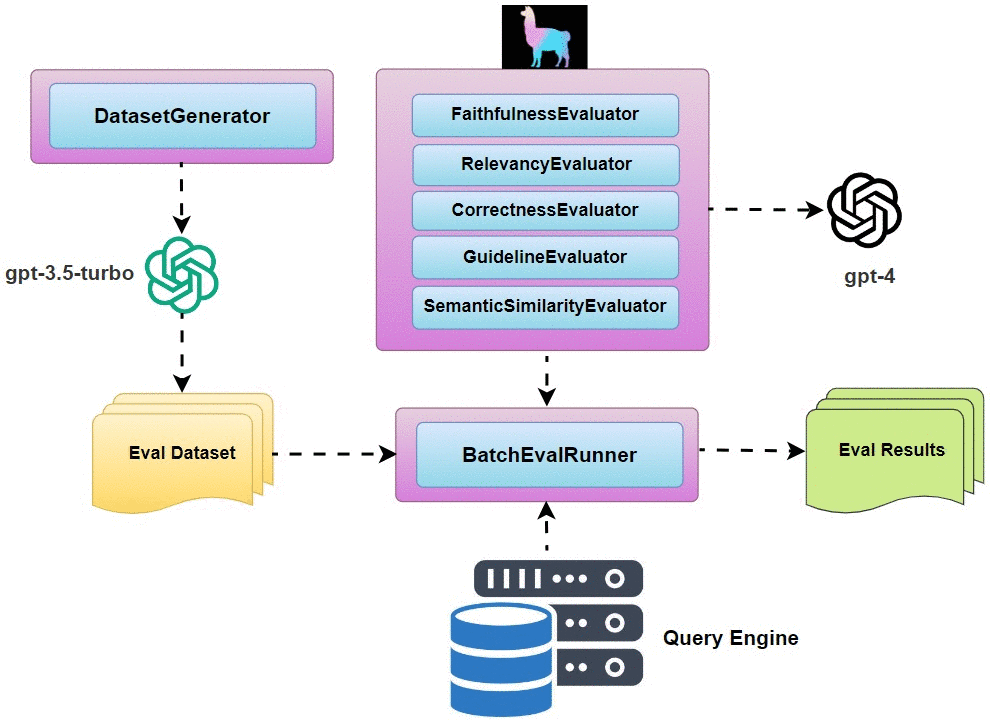
Implementation Details
The complete source code and source PDF documents can be found in my GitHub Repo or my Colab notebook.
The first step is to load my three PDF documents on the DevOps self-service model.
Step 1: Load documents
titles = [
"DevOps_Self-Service_Pipeline_Architecture",
"DevOps_Self-Service_Terraform_Project_Structure",
"DevOps_Self-Service_Pipeline_Security_Guardrails"
]
documents = {}
for title in titles:
documents[title] = SimpleDirectoryReader(input_files=[f"./data/{title}.pdf"]).load_data()
print(f"loaded documents with {len(documents)} documents")Step 2: Implement recursive retriever + document agent
We explored the details of this strategy in a previous article, Building Production-Ready LLM Apps With LlamaIndex: Recursive Document Agents for Dynamic Retrieval. We are not going into details again, but list the code snippet below. Please follow the comments to understand the detailed steps if you need to become more familiar with this strategy.
# define LLM
llm = OpenAI(temperature=0.1, model_name="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm)
# create document agents
agents = {}
for title in titles:
# build vector index
vector_index = VectorStoreIndex.from_documents(documents[title], service_context=service_context)
# build summary index
summary_index = SummaryIndex.from_documents(documents[title], service_context=service_context)
# define query engines
vector_query_engine = vector_index.as_query_engine()
summary_query_engine = summary_index.as_query_engine()
# define tools
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="vector_tool",
description=f"Useful for retrieving specific context related to {title}",
),
),
QueryEngineTool(
query_engine=summary_query_engine,
metadata=ToolMetadata(
name="summary_tool",
description=f"Useful for summarization questions related to {title}",
),
),
]
# build agent
function_llm = OpenAI(model="gpt-3.5-turbo-0613")
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
verbose=False,
)
agents[title] = agent
# define index nodes that link to the document agents
nodes = []
for title in titles:
doc_summary = (
f"This content contains details about {title}. "
f"Use this index if you need to lookup specific facts about {title}.\n"
"Do not use this index if you want to query multiple documents."
)
node = IndexNode(text=doc_summary, index_id=title)
nodes.append(node)
# define retriever
vector_index = VectorStoreIndex(nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# define recursive retriever
# note: can pass `agents` dict as `query_engine_dict` since every agent can be used as a query engine
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=agents,
verbose=False,
)
response_synthesizer = get_response_synthesizer(response_mode="compact")
# define query engine
query_engine = RetrieverQueryEngine.from_args(
recursive_retriever,
response_synthesizer=response_synthesizer,
service_context=service_context,
)Step 3: Implement metadata replacement + node sentence window
SentenceWindowNodeParser is a tool that can be used to create representations of sentences that consider the surrounding words and sentences. During retrieval, before passing the retrieved sentences to the LLM, the single sentences are replaced with a window containing the surrounding sentences using the MetadataReplacementNodePostProcessor. This can be useful for tasks such as machine translation or summarization, where it is essential to understand the meaning of the sentence in its entirety. This is most useful for large documents, as it helps to retrieve more fine-grained details.
LlamaIndex has a detailed notebook on implementing this strategy. Quoting the code snippet as follows.
# create the sentence window node parser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
simple_node_parser = SimpleNodeParser.from_defaults()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2", max_length=512
)
ctx = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model
)
# extract nodes and build index
from llama_index import VectorStoreIndex
document_list = SimpleDirectoryReader("data").load_data()
nodes = node_parser.get_nodes_from_documents(document_list)
sentence_index = VectorStoreIndex(nodes, service_context=ctx)
# define query engine
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
query_engine = sentence_index.as_query_engine(
similarity_top_k=2,
# the target key defaults to `window` to match the node_parser's default
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)Evaluation Comparison
Now that we have both strategies implemented to query our three PDF documents, let’s look into how to evaluate these two strategies.
Define evaluators
We are going to evaluate the faithfulness and relevancy of our query responses. As a best practice, we will be using gpt-4 for the evaluation, as it’s always a good idea to use a superior model to assess a lesser model, in our case, gpt-3.5-turbo.
from llama_index.evaluation import FaithfulnessEvaluator, RelevancyEvaluator
# use gpt-4 to evaluate
gpt4_service_context = ServiceContext.from_defaults(llm=OpenAI(temperature=0.1, llm="gpt-4"))
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=gpt4_service_context)
relevancy_gpt4 = RelevancyEvaluator(service_context=gpt4_service_context)Generate evaluation questions
We will use DatasetGenerator to generate a set of evaluation questions and randomly pick 30. We will save the 30 questions in a file named question_dataset.txt. We load the questions from the file if the file exists to avoid generating questions repeatedly each time the pipeline gets triggered.
import random
random.seed(42)
from llama_index.evaluation import DatasetGenerator
import nest_asyncio
nest_asyncio.apply()
# load data
document_list = SimpleDirectoryReader("data").load_data()
question_dataset = []
if os.path.exists("question_dataset.txt"):
with open("question_dataset.txt", "r") as f:
for line in f:
question_dataset.append(line.strip())
else:
# generate questions
data_generator = DatasetGenerator.from_documents(document_list)
generated_questions = data_generator.generate_questions_from_nodes()
print(f"Generated {len(generated_questions)} questions.")
# randomly pick 30 questions
generated_questions = random.sample(generated_questions, 30)
question_dataset.extend(generated_questions)
print(f"Randomly picked {len(question_dataset)} questions.")
# save the questions into a txt file
with open("question_dataset.txt", "w") as f:
for question in question_dataset:
f.write(f"{question.strip()}\n")
for i, question in enumerate(question_dataset, start=1):
print(f"{i}. {question}")The 30 questions generated by DatasetGenerator are as follows. Feel free to modify the questions in this list to ensure they are good and valid, as this set of questions will be our “golden” set.

Define evaluation batch runner
Instead of evaluating the responses using individual evaluators, we will use BatchEvalRunner, a recent addition to the LlamaIndex Evaluation Modules. BatchEvalRunner can be used to run a series of evaluations asynchronously. Constructing a BatchEvalRunner is straightforward, passing in a dictionary of evaluators, specifying the number of workers. See the code snippet below:
from llama_index.evaluation import BatchEvalRunner
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
workers=10,
show_progress=True
)Let’s also create a function to get the eval results. The key is either faithfulness or relevancy. The score is calculated by the number of correct responses divided by the total number of results for the particular category: faithfulness or relevancy. See the code snippet below.
def get_eval_results(key, eval_results):
results = eval_results[key]
correct = 0
for result in results:
if result.passing:
correct += 1
score = correct / len(results)
print(f"{key} Correct: {correct}. Score: {score}")
return scoreNext, let’s invoke BatchEvalRunner's aevaluate_queries function for both query engines.
Evaluation of recursive retriever + document agent
eval_results = await runner.aevaluate_queries(
recursive_query_engine, queries=question_dataset
)
print("------------------")
score = get_eval_results("faithfulness", eval_results)
score = get_eval_results("relevancy", eval_results)Evaluation of metadata replacement + node sentence window
eval_results = await runner.aevaluate_queries(
metadata_query_engine, queries=question_dataset
)
print("------------------")
score = get_eval_results("faithfulness", eval_results)
score = get_eval_results("relevancy", eval_results)Wait a few minutes, and the result appears like the following screenshot.

Summarizing the evaluation results side by side, we have the following table:
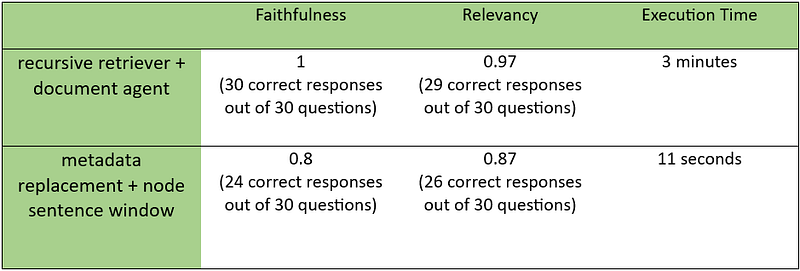
As we can see from the screenshot for the evaluation results and the summary table above, the winner is clear! For our multi-document RAG pipeline, the recursive retriever + document agent option performs well above metadata replacement + node sentence window option in the category of faithfulness and relevancy.
It’s worth noting that the time it took for the evaluations for both options differs greatly:
- 3 minutes for recursive retriever + document agent evaluation
- 11 seconds for metadata replacement + node sentence window evaluation
Please note that the evaluation results above are only for our use case of the three PDF documents on DevOps self-service model. The finding does not mean the strategy we chose for our use case applies to other multi-document use cases. Each use case is unique and should be handled with proper evaluation, as outlined in the steps above, to determine the best strategy.
Also keep in mind that evaluation is not free. Since we use gpt-4 to evaluate our RAG pipeline, it does cost us money, see OpenAI pricing for gpt-4 below. Do keep an eye on your OpenAI usage and set soft/hard limit to better manage your usage.

Summary
In this article, we explored Evaluation Driven Development (EDD), an essential and indispensable part of any RAG pipeline. We used a multi-document use case and implemented two of many strategies offered by LlamaIndex: recursive retriever + document agent and metadata replacement + node sentence window. We then evaluated both strategies using LlamaIndex’s Evaluation Module. The evaluation results measuring faithfulness and relevancy clearly showed that the recursive retriever + document agent is the winner for our use case.
We can conclude that EDD is essential to aid us in making the right design decisions during our RAG pipeline design and development. Mastering EDD is critical to delivering our RAG pipelines with confidence and insights.
The complete source code and source PDF documents can be found in my GitHub Repo or my Colab notebook.
Happy coding!
Update: please check out this LlamaIndex webinar on EDD, where I walk through the detailed steps on how to implement EDD in a RAG pipeline.





