
Evaluate and Monitor the Experiments With Your LLM App
Evaluation and tracking of your LLM experiments with TruLens

The development of a Large Language Model application involves many iterations of experimentation. As a developer, your objective is to ensure that the model’s answers align with your specific requirements like informativeness and appropriateness. This process of retesting and evaluation can be quite time-consuming.
This article will show you step-by-step how to automate such a process using TruLens. TruLens is a Python package that contains a set of tools for evaluating your LLM applications.
A colab notebook containing all the example code can be found 👉here.
Workflow
TruLens workflow comprises five steps:
- Build your LLM application (i.e., with LangChain and ChatGPT or any other LLM)
- Connect your LLM app to TrueLens and start logging the records or interactions between your users and your app. All logs are stored in sqlite db.
- Add feedback functions to log and evaluate your LLM app’s quality (optional)
- Explore records, and evaluation results in TruLens dashboard based on streamlit
- Iterate and select the best LLM chain (version)
Before we start
- The following example creates a simple LLM application using LangChain, ChatGPT, and an alternative LLM from HuggingFace.
- TruLens offers the integration of feedback functions to evaluate the quality of our LLM app.
- In this example, we are also using HuggingFace to check if the answer is in the same language as the question and to detect any toxicity in the answer. However, this step is optional and it is also possible to write your own feedback functions.
Prerequisites
Before we can start creating our LLM application, we need to fulfill the following requirements.
Installing packages
Run the following command to install the required packages:
pip install trulens-eval langchain -q
Please note: I had an old version of
langchainalready installed but received some errors when using it in combination with TruLens. Therefore, I installed the (latest) version0.0.201.
Get API keys
The OpenAI key can be created under this link and then by clicking on the
+ Create new secret key button.
Please note: If you prefer not to spend money, you can skip this step and solely utilize the alternative LLM from HuggingFaceHub.
For HuggingFace, Access Token can be created in the user settings under Access Tokens.
Example LLM application
We start creating our example LLM application by setting our API keys as environment variables.
import os
os.environ["OPENAI_API_KEY"] = "<ADD KEY HERE>"
os.environ["HUGGINGFACE_API_KEY"] = "<ADD KEY HERE>"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "<ADD KEY HERE>"The API key and token for Hugging Face are the same. The difference is that the HUGGINGFACE_API_KEY is used by TrueLens for leveraging Hugging Face’s feedback functions, while the HUGGINGFACEHUB_API_TOKEN is later used by HuggingFaceHubto get a Text2Text Generation model as an alternative to ChatOpenAI.
After that, we can create our example application by writing the following code
# imports from LangChain to build app
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,
HumanMessagePromptTemplate)
from langchain import HuggingFaceHub
# create LLM chain
full_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="You are a tourist guide and gourmet to provide" \
"helpful information about the following question: {prompt}"\
"Name at least 2 restaurants and the dishes they are famous for.",
input_variables=["prompt"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([full_prompt])
# You can choose between gpt-3.5-turbo and google/flan-t5-xxl
google = HuggingFaceHub(repo_id="google/flan-t5-xxl",
model_kwargs={"temperature":0.9})
chat = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0.9)
# Provide here as a parameter value for llm the model you'd like to use
chain = LLMChain(llm=google, prompt=chat_prompt_template)First, we create a suitable PromptTemplate where we provide additional contextual information about the agent’s (aka model’s) role and our expectations (such as restaurants and the dishes they are famous for).
Then we can either go with a Text2Text Generation model from HuggingFaceHub or with the classic ChatOpenAI model.
Please note: Question Answering models are not yet supported by LangChain. That’s why we are using Text2Text Generation models. An overview of possible models can be found here.
Define feedback functions
As mentioned, we will create two feedback functions: one to check if the language of the answer matches that of the question, and another one to detect toxicity.
from trulens_eval import Feedback, Huggingface, Query
# Initialize HuggingFace-based feedback function collection class:
hugs = Huggingface()
# Define a language match feedback function using HuggingFace.
f_lang_match = Feedback(hugs.language_match).on(
text1=Query.RecordInput, text2=Query.RecordOutput
)
# Check if model's answer is toxic
f_toxity = Feedback(hugs.not_toxic).on(text=Query.RecordOutput)Wrap the LLM app with TruLens
To log and evaluate each interaction with our created chain or LLM app, we have to wrap it within a TruChain object.
from trulens_eval import TruChain
truchain = TruChain(
chain,
app_id='TestApp-ABC',
feedbacks=[f_lang_match, f_toxity]
)A default.sqlite file should now have been created in the directory of the Python file containing this code.
Start interacting
To interact now with the LLM app, we can run the following command
truchain("Where can I find the best tapas in Barcelona?")Please note: In case you get the following error message
App raised an exception <empty message>please check if your API keys/tokens are working and set correctly.
You will get the model’s or app answers as well as the notification that the record and feedback have been stored in the sqlite file.
Explore your records and test results
To explore your records now, you can initiate the TruLens dashboard by executing the following code snippet:
from trulens_eval import Tru
tru = Tru()
tru.start_dashboard()Please note: I faced a toml/decoder error when I executed the
.start_dashboard()method. The solution was to remove theconfig.tomlfile. More information can be found here.
You can stop the dashboard any time by executing the tru.stop_dashboard() method.
Now you can open the dashboard by clicking on the local URL.
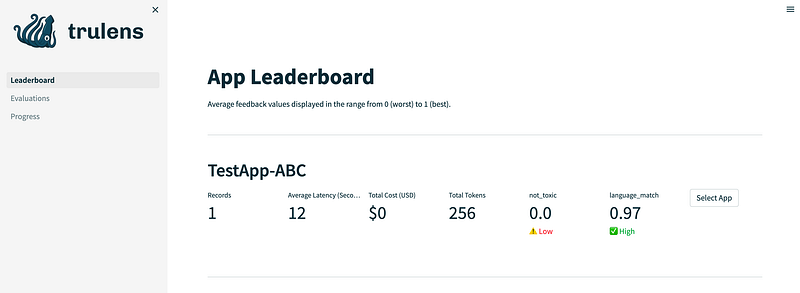
The App Leaderboard provides an overview of your LLM applications. In our example, you can view the number of existing records, the generated costs and tokens, as well as information from our two feedback functions: not_toxic and language_match.
We can get more detailed information (figure 2) by clicking on the Select App button.
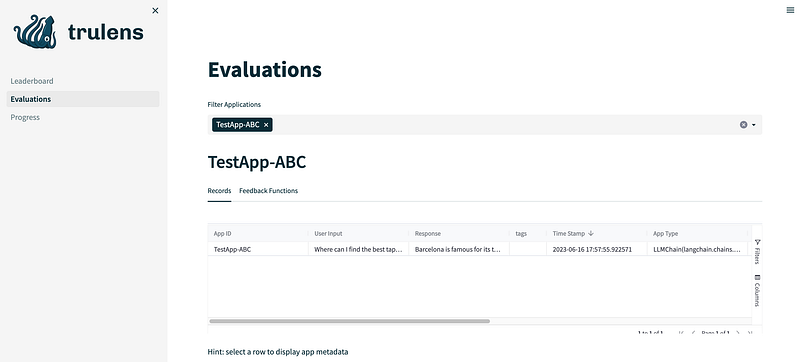
This view also shows us the generated costs per record (if you are using ChatGPT).
If we select a row, we can access additional metadata about our app. Figure 3 shows an excerpt of the available metadata.
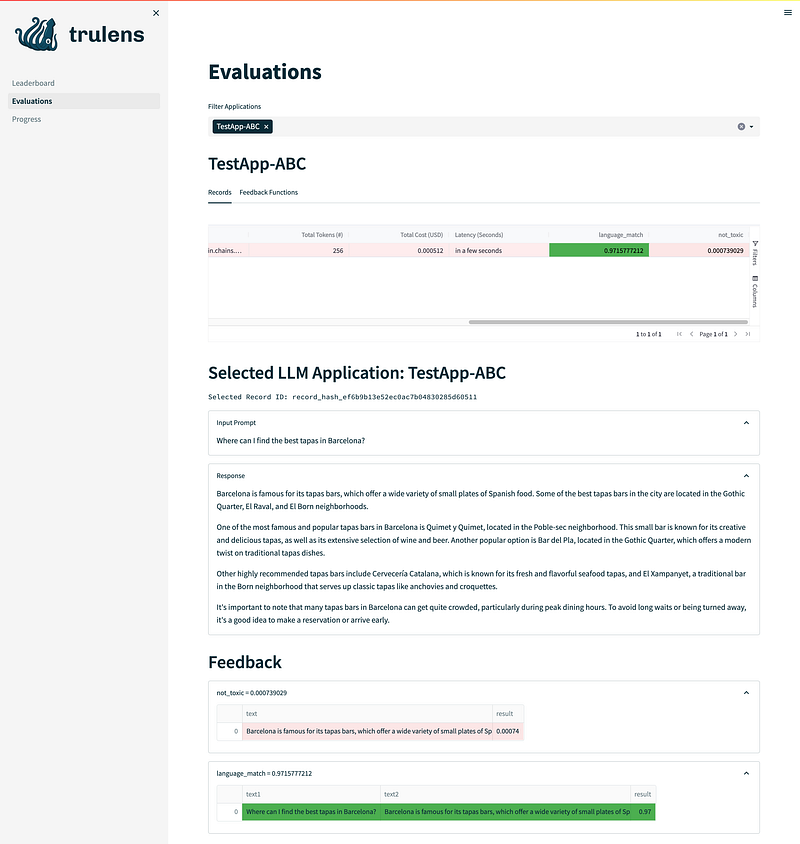
Conclusion
TruLens is a great solution for enhancing the management and analysis of experiments with your LLM application. Although the package lacked detailed documentation and code examples in the git repository at the time of writing this article, it is reasonable to expect that the developers are actively addressing these areas. Moreover, an additional valuable feature to consider would be the inclusion of session information for tracking or logging purposes, particularly when multiple users are testing your model and differentiation between them is desired.
The example code can be found 👉here.