
LIST OF HOW TOs
Get Better at EntityFramework Core — Best Practices
Here’s a list of best practices you should use today

I’ll keep updating this article as I find new practices.
EntityFramework is a super easy to use ORM library for .NET developers. Though, despite its ease of use, and plug-and-play functionality, getting it right is honestly quite difficult.
Table of Contents
- Solution and Project Structure
- Security
- Domain Models
- dotnet ef CLI
- Migrations
Solution and Project Structure
👍 Separate layers into different projects
The solution structure below is one that I often find the most useful.
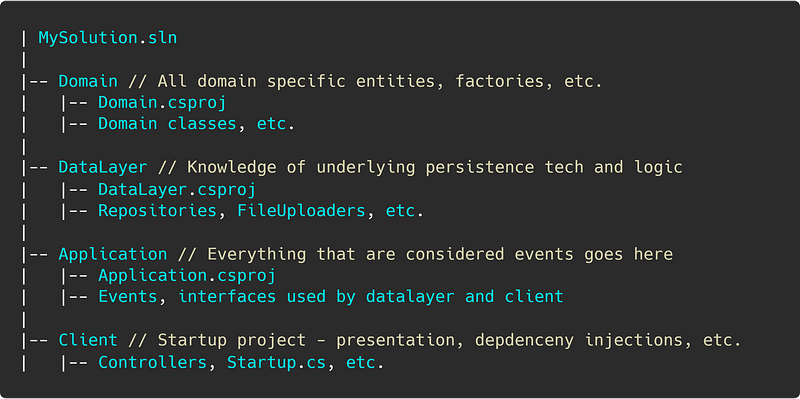
It allows you to cleanly separate the responsibilities of the application.
👍 Only the DataLayer project should have a dependency on EntityFramework — Updated 21st April 2020
Persistence implementation details should only be known to the data layer.
The data layer must implement interfaces defined in other projects, and concrete implementations of those classes should be registered with your dependency container of choice.
👍 Keep the DbContext class internal to the DataLayer project
Create an IServiceCollection extension method in the DataLayer that clients can use. The method should register the DbContext with the dependency injection framework.
The client should not know, or care, about persistence.

Use the IServiceCollection in the Startup class of the client project.
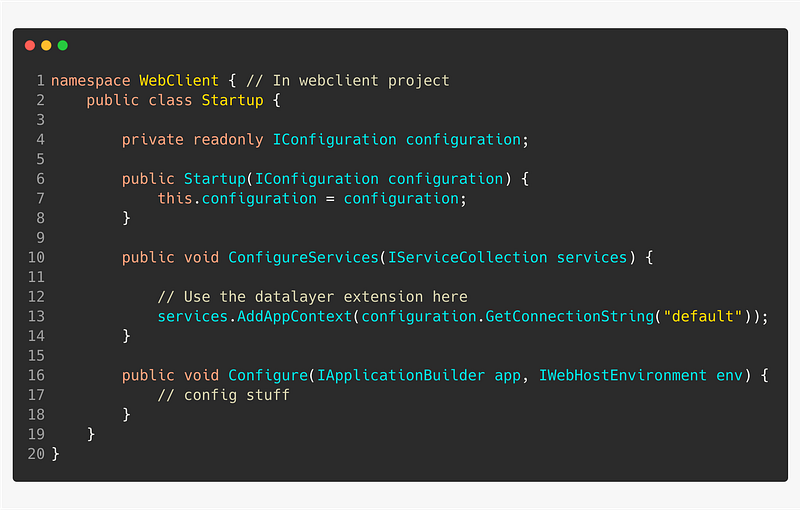
Encapsulating the database context ensures that the client won’t have direct access to making database calls, in addition, the client project won’t have an unnecessary dependency on EntityFrameworkCore.
👍 Use Type Configuration over OnModelCreating()
When creating the DbContext, it’s easy to just configure domain models directly inside the OnModelCreating(Modelbuilder builder) method. But this approach will quickly become chaotic.
Instead, only use OnModelCreating to scan for types that perform entity configurations.

Then create separate, dedicated classes for configuring the different types you’ve added to DbSet

Inside Configure(builder)` you’d write up all the database specific model configurations using FluentApi.
Security
👍 For local development, store secrets using “dotnet user-secrets”
Avoid checking in your ConnectionString at all cost by using the built-in .NET secrets manager.
Note that you may need to add this nuget package: Microsoft.Extensions.Configuration.UserSecrets to your project.
User secrets are stored at:
Windows
%APPDATA%\Microsoft\UserSecrets\
Mac
~/.microsoft/usersecrets/
Follow the steps below to add user secrets
- In your AppSettings, add the ConnectionString property. It may look like the snippet below — it’s important that the value is empty.
# appsettings.json{
"ConnectionStrings": {
"default": ""
},
// Some other properties
}2. Change directory to your client project using the terminl. E.g. the root of your ASP.NET web app.
cd To/Path/Of/Startup/Root
3. Initialize the user secrets, and set the ConnectionString
dotnet user-secrets init
dotnet user-secrets set "ConnectionStrings:default" "connection_string"
👍 For production, store secrets in a KeyVault or Environment variables
The best solution is to store secrets in a KeyVault, such as Azure KeyVault. But, it may also be sufficient to just store them as environment variables, or in an AppSettings.json file located on the web server itself.
👍 Create a separate database login and user for the app
View the application as any other regular user of the database.
In case of someone mistakenly checking in the db user and password into source control, it’s less costly to just disable the app’s db user and create a new one, than having your server administrator (sa) login and dbo user compromised.
🚨 The app’s DB user must not have unnecessary permissions
Would you give anyone in your organization or team super admin privileges to the test or production database?
Grant permissions to the app’s database user based on the principal of least privilege. The app should only have the bare minimum of permissions to perform its work.
👍 Run migration scripts from a different DB user than the app is using
This advice is related to separation of duties. The application should not be in charge of creating the database and its tables. The application should simply perform actions on those objects.
Domain Models
👍 Persistence ignorance
Focus on modeling your domain. Try as much as possible to not think about which ORM you are using.
However, be pragmatic.
Sometimes it’s simply too much of a hassle to make things work when acting like persistence doesn’t exist. Consider your use cases and how flexible and modular you want your code to be.
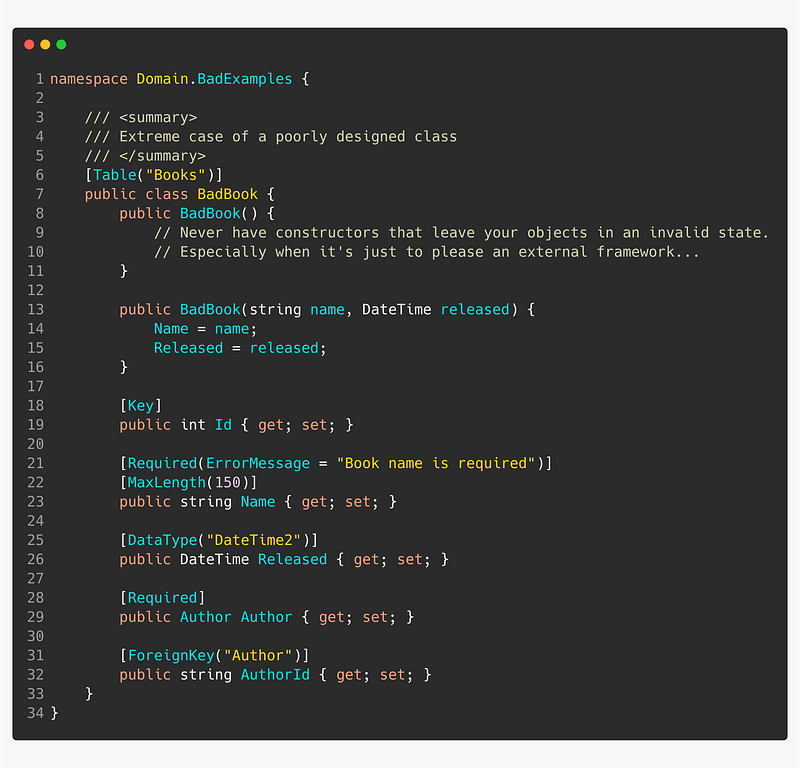
🚨 Avoid data annotations
Avoid attributes such as [Table], [Column], [Key], [ForeignKey] etc.
Use a separate data layer project that takes a dependency on the Domain project and wires up all the models using IEntityTypeConfiguration<T>.
👍 Keep IDs private
Rarely you’d want to expose IDs for anything else than convenience.
Exposing the IDs in urls like api/author/1 may lead to annoyances, such as if an MS SQL server has crashed or restarted, the next ID may be 1001. I’ve had clients commenting this, insisting it was a bug that had to be solved.
If you try to generate a migration with a class that has a private id field, EF core will complain because it’s not able to find an ID to use as primary key. This is easily fixed using type configuration as shown below.
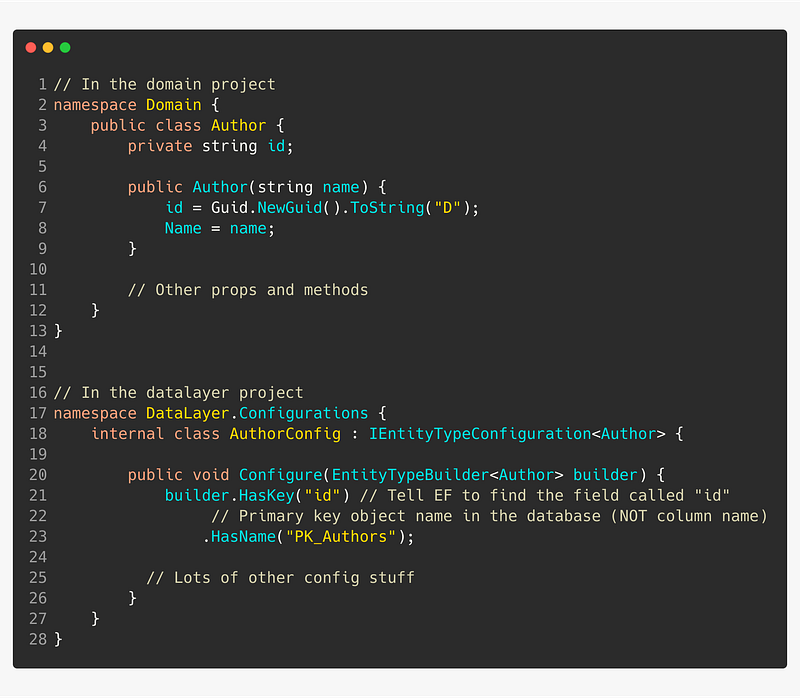
Instead of querying using IDs, you’d use another property that is unique, or, a combination of properties.
Without being certain, Medium articles seems to use a mix of Author handle, article name and a random string.
nmillard/entityframework-core-dont-get-burnt-in-production-335ddfcfdfda
If you’d have to expose IDs publicly, try use something else than an integer.
👍 Generate IDs yourself
Don’t let third-party software like a database generate your domain IDs. You should be in full control of generating them. They’re simply too important.
I’ve usually went with one of two ways to deal with this: 1) let the domain model generate the ID itself, such as assigning a GUID on instantiation, or 2) use an ID factory, and pass the generated ID to the model’s constructor.
🚨 Avoid foreign key properties in domain models
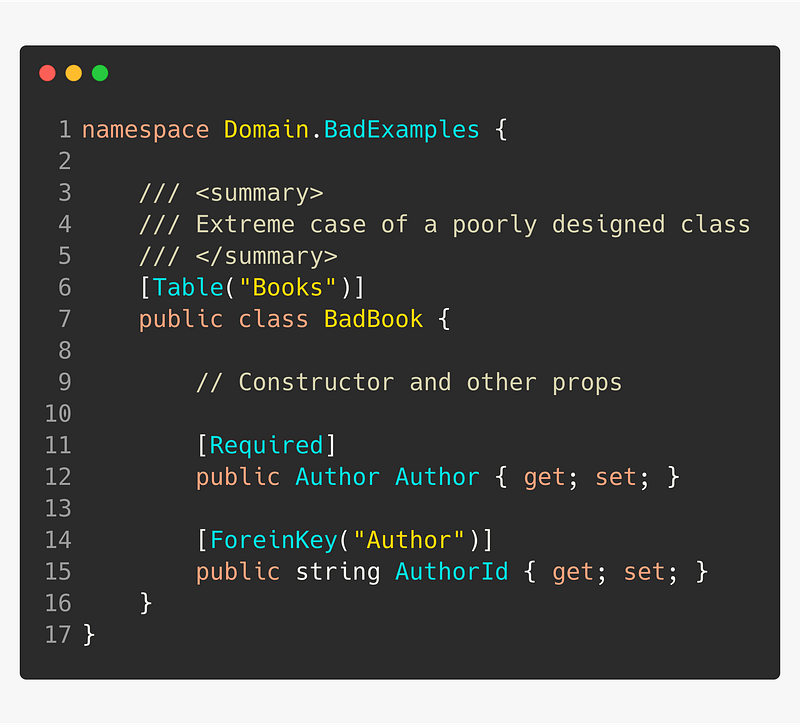
👍 Use shadow properties when EF can’t generate a foreign key column — Added 1st April 2020
🚨 Avoid public default constructors
Don’t make public default constructors just to make EF Core happy, instead, make the the default constructor private.
It is also possible to have parameterized constructors, if not even a private one is good enough. However, you should be aware of this behaviour:
- Parameter and property types and names must match — but parameter names can be camel-cased (likeThis)
- Navigation properties cannot be set

Notice the model above has no default public constructor. EF Core matches the constructor argument with the auto-property.
👍 Remove unnecessary setters for properties and fields
Use a data layer project to let EF Core know how to populate properties and fields without setters.
This is done using classes that implementIEntityTypeConfiguration<T>.
I’m using an example of an owned type that will be used as value object — that’s why you’ll see all the additional methods and operator overrides to check for equality.
I’m using a value object example because that’s when you’d usually want to get rid of all setters — even internal or private ones.
👍 Make collections readonly
Use private fields for collections and expose them using immutable collections, such as IReadOnlyCollection
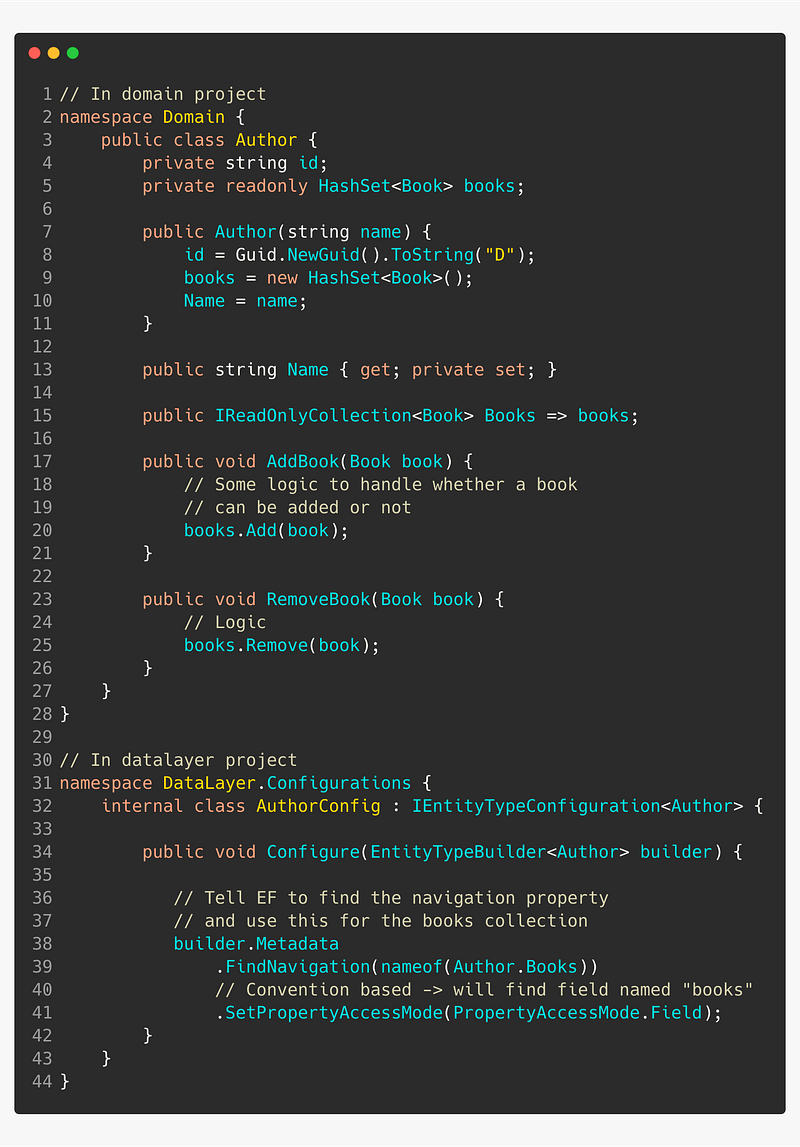
By only allowing addition and removal of books thru calling Author’s methods, you’ve centralized the logic.
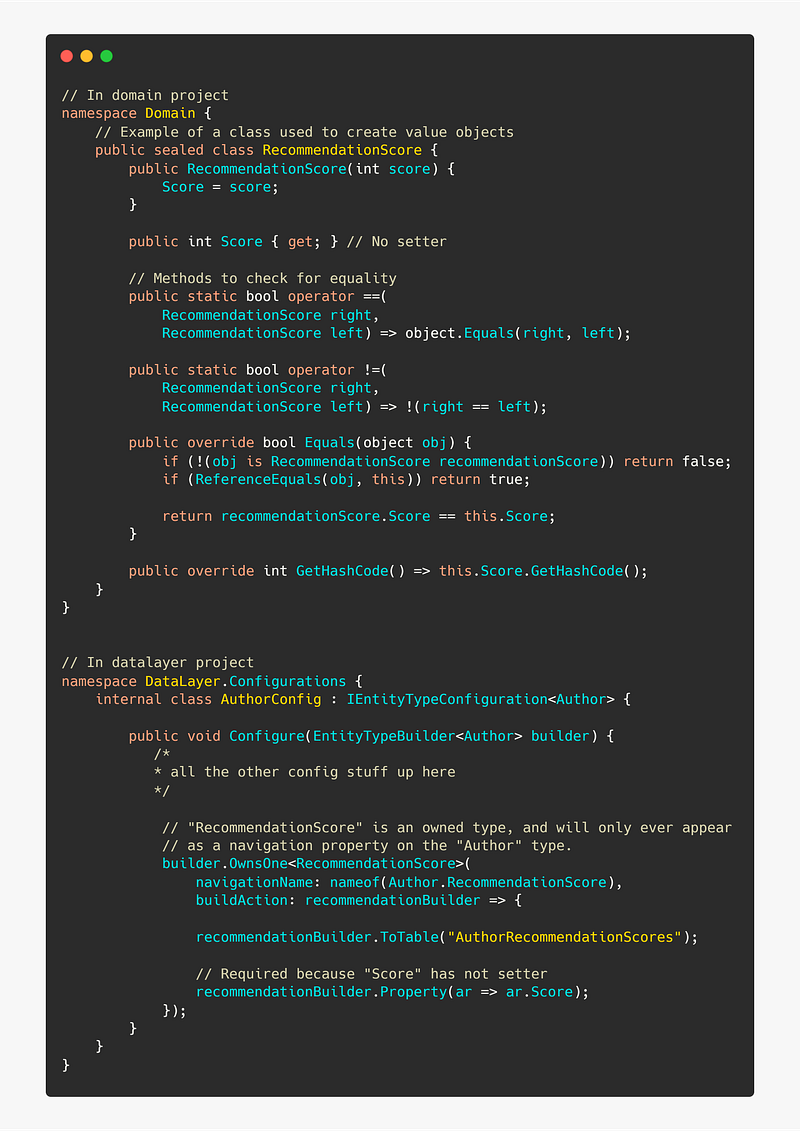
👍 Use owned types
An owned type is a type that will only ever appear on navigation properties of other types.
Owned types are often not entities per se, but rather types that depend on some other type to exist or value objects. These should ideally not have an id.
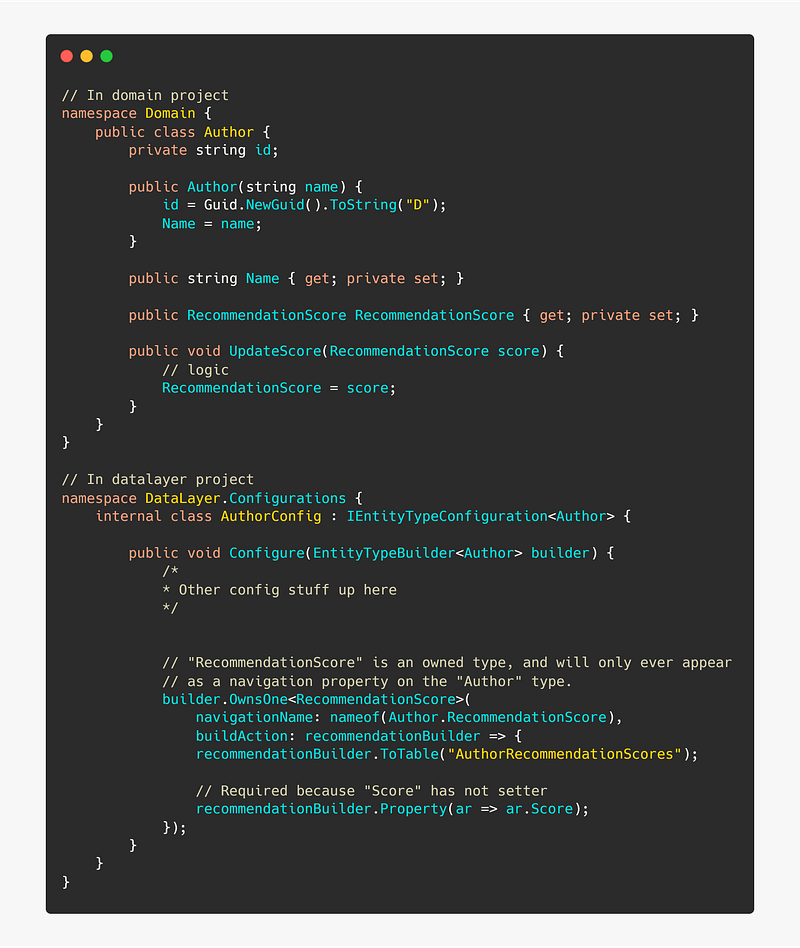
Even though RecommendationScore does not a primary key in the POCO, one will be generated for it in the database. It takes the primary key of the Author, because, as we have configured it, Author can only have one RecommendationScore.
dotnet ef CLI
🚨 Don’t use Visual Studio helper commands
In my opinion, Visual Studio is hiding too much of what’s going on when you’re working with .NET, including EF Core.
Getting used to magic hinders your abilities to troubleshoot and confines you to VS.
👍 Use the dotnet ef command line interface
Install dotnet ef to execute the EF core commands.
dotnet tool install --gobal dotnet-ef
In your data layer project, install Microsoft.EntityFrameworkCore.Design. This package is used by the EF CLI in order to perform migrations, update database, etc.
dotnet add package Microsoft.EntityFrameworkCore.Design
When using the CLI, you’re gaining some valuable, transferable skills. You’ll have an easier time setting up Code as Infrastructure, DevOps pipelines, debugging, etc.
Remember, only Visual Studio is aware of its own magic. When you start building pipelines, you can no longer rely on Visual Studio commands. Commands like Update-Database are simply not possible.
Migrations
Really, migration deserve its own article, but I’ll try poke at the monster here anyway.
👍 Create concise, manageable migrations
Run the ef migrations command everytime you make updates to your model or model configuration.
dotnet ef migrations add MigrationNameTry keep the migrations manageable by not bundling unrelated model updates into the same migration.
👍 Check if migration code is correct
Always open the newly created migrations and read through the auto-generated code.
Quite often I find that I need to tweak my model configuration, because EF Core may not register a relationship correctly.
🚨 Don’t run dotnet ef database update
Never run the database update command against anything else than your own local database.
👍 Use idempotent scripts to create and update the database
Idempotent scripts ensure that only statements that hasn’t run will be executed. When creating an idempotent database script, you can without worry execute the whole script multiple times.
dotnet ef migrations script -v \
-o ./scripts/idempotent.sql \
--idempotentThe command above will generate a script using all your existing migrations, and add IF conditions to check if a migration has already been executed.
Keep the script in source control, at a sensible location. Then pick up and execute the script during your deployment process.
👍 Create migrations for seed data
By having your seed data placed in migrations, the data will automatically be part of the idempotent script.
Doing this you’ll save yourself a lot of headache related to for example running subsequent scripts in order.
👍 Document the migrations workflow
It’s easy to forget all the steps required to re-create or update your database. Document the workflow, and save the documentation markdown file in the data layer project root.
For easy copying into your own .md file
## Intro
All commands must be executed from the root of the data layer project.1. cd to root of data layer project### Add new migration
dotnet ef migrations add <MigrationName> -s ../Path/To/StartupProj<MigrationName> ← name of the migration, without <>### Remove most recent migration
dotnet ef migrations remove -s ../Path/To/StartupProj### Update local(!) database
dotnet ef database update -s ../Path/To/StartupProj^ this must only ever be used to update your own local database### Generate idempotent script
dotnet ef migrations script -v -i \
-o ./scripts/idempotent.sql \
-s ../Path/To/StartupProj## Switches
-v ← verbose console output
-o ← path to where generated script file is placed
-i ← makes the script idempotent
-s ← Path to startup project (e.g. ASP.NET web app .csproj)