
Enhance Semantic Search of Text Embeddings through Collaborative Filtering over A Knowledge Graph
Why Search by Similarity Itself Is Not Sufficient

1. The Rise of LLMs and RAG
It is almost nine months now since the first date when ChatGPT was released to the public, and since then it is almost everyday we see new ideas and projects built ontop of GPT, as well as many other Large Language Models (LLM). LLMs have revolutionized natural language processing, powering diverse applications from chatbots to content generation, enhancing user experiences with human-like interactions, and allowing for real-time, context-aware responses across industries.
Among many usage patterns of LLMs, e.g. fine-tuning, few-shot learning and etc. Retrieval Augmented Generation (RAG) has demonstrated its unique advantages.
RAG was introduced by Facebook AI in a paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” which was presented at NeurIPS 2020. The diagram below vividly explains the concept of RAG.
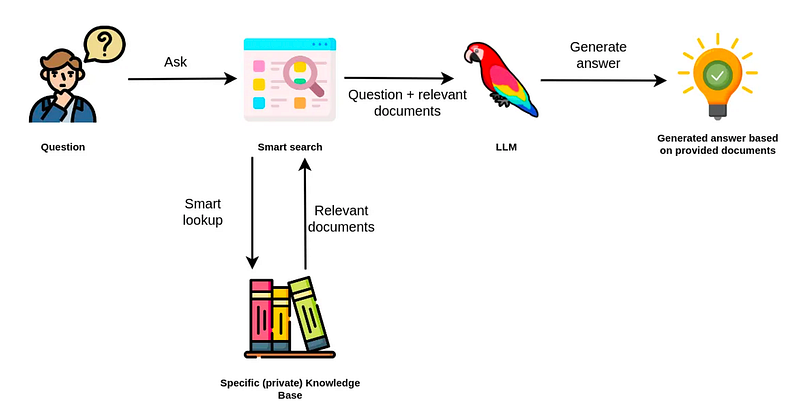
In a summary, RAG involves 2 steps:
- Retrieval Component: This uses an information retrieval system (often built over large-scale corpora) to fetch relevant documents or passages that might be beneficial for a given query.
- Generative Component: This is typically a large-scale language model which generates human-like text based on the provided input and the documents retrieved.
To improve context-awareness, explainability and relevance in NLP/NLU, RAG has certainly proven its unique value over the LLM fine-tuning approach in many places. In fact, one of my previous posts had more detailed explanation on the RAG based solution.
RAG offers a powerful approach to combine retrieval-based and generative models. However, like all models, it comes with its own set of challenges:
1. Retrieval Accuracy: The effectiveness of RAG relies heavily on the accuracy of the retrieval component. If the retrieval mechanism fetches irrelevant documents or misses important ones, the generated output can be suboptimal.
2. Data Dependency: The model is dependent on the quality and relevance of the external dataset used for retrieval. The absence of a comprehensive or up-to-date dataset can limit the system’s performance.
3. Redundancy: There’s a risk of redundancy if the retrieved documents have overlapping information. The model might repeat or over-emphasize certain aspects in the generated output.
4. Size limitation: LLMs usually put a limit on the size of the prompt provided for content generation.
5. Domain Awareness: Adapting RAG to specific domains might require domain-specific tuning of the retrieval component or retraining the entire system on domain-specific data.
As many RAG implemtations rely on text embeddings to retrieve content based on its semantics, I will demontrate an approach to improve retrieval accuracy which leverages collaborative filtering over a knowledge graph.
2. Review of Text Embedding
In my another post, Text Embedding — What, Why and How? I have explained the definition, approach of generating, storing and search of text embedding. Embedding is a process, and vector is the data type, but more than oftent the two are used interchangeably.
What I didn’t mention in the post are limitations of LLM generated embeddings. When being applied in real applications, we can often find out answers of a question are not quite relevant, when they are retrieved only by searching for the most similar text embeddings. Some of the reasons are (taking GPT as an example):
- Contextual Embeddings: One of GPT’s strengths and potential weaknesses is that it generates contextual embeddings. This means the representation for a word or phrase can change based on its surrounding context. When searching using embeddings from a specific context, they might not align perfectly with embeddings generated from a different context, even if the term is the same.
- High Dimensionality: GPT embeddings are high-dimensional, capturing a vast range of linguistic nuances. While this richness is beneficial, it might sometimes prioritize some dimensions that introduce noise or irrelevancies into the search.
- Training Data Biases: The embeddings produced by GPT reflect the biases and distribution of its training data. If certain topics or contexts were underrepresented in the training data, their embeddings might not be as accurate, leading to suboptimal search results.
- Semantic Overlaps: GPT might generate embeddings that are semantically close for terms or phrases that humans perceive as distinct. This can cause the retrieval of results that seem irrelevant.
In fact, witht the help of a domain specific knowledge graph which has connected pieces of knowledge, it is possible to enhance the accuracy of embedding based search using existing methods like collaborative filtering. At high level, below are required steps:
1 — For a question, get its text embedding and let’s call it emb(q).
2 — Do a search in a vector store to find contents that have the most similar embeddings as emb(q), and save the similarity score into sim(content).
3 — For returned contents, apply collaborative filtering to calculate a weight and adjust similarity score.
4 — Return contents which now have improved accuracy.
Let me show you how this works using a Movie Graph.
3. An Example: Movie Recommendations
3.1 Prepare the Movie Graph
To start the experiment as simple as possbile, I am going to create a free AuraDB instance from Neo4j for the movie graph.
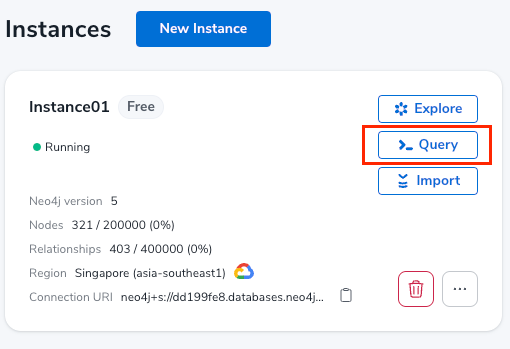
Once the instance is up and running, click _Query button to launch the Neo4j Browser. You will need to put the password generated at the time when the instance was created here. After launching Browser, in the text box, type:
:play movies
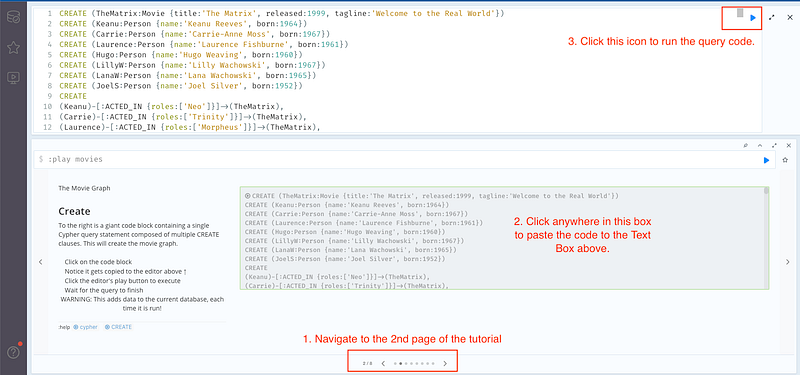
This will launch the Movie Graph Tutorial. Navigate to the 2nd page, and click the block where you see multiple lines of code. With 3 simple steps, we just create the Movie Graph.
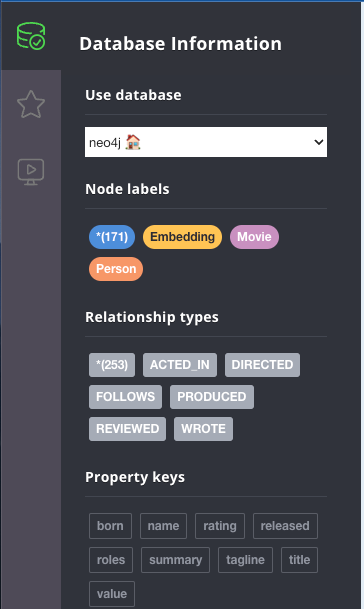
When clicking the Database icon to the left, we should be able to see the nodes and relationships created.
For a more comprehensive tutorial on the Movie Graph and Neo4j, here is a great resource.
3.2 Adding Text Embeddings to Movie Titles & Taglines
In the Movie Graph, every Movie node has 2 text properties: title and tagline. Let’s generate text embeddings for both title and tagline using the Python code below.
from neo4j import GraphDatabase
from openai.embeddings_utils import get_embedding
import openai
"""
LoadEmbedding: call OpenAI embedding API to generate embeddings for each proporty of node in Neo4j
Version: 1.1
"""
OPENAI_KEY = "OPENAI-KEY"
EMBEDDING_MODEL = "text-embedding-ada-002"
NEO4J_URL = "neo4j+s://INSTANCE_ID.databases.neo4j.io:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "NEO4J_PASSWORD"
class LoadEmbedding:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
openai.api_key = OPENAI_KEY
def close(self):
self.driver.close()
def load_embedding_to_node_property(self, label, property):
with self.driver.session() as session:
result = session.run("MATCH (n:" + label + ") WHERE n." + property + " IS NOT NULL RETURN id(n) AS id, n." + property + " as " + property)
# call OpenAI embedding API to generate embeddings for each proporty of node
# for each node, update the embedding property
count = 0
for record in result:
id = record["id"]
text = record[property]
# Below, instead of using the text as the input for embedding, we add label and property name in front of it
embedding = get_embedding(label + " " + property + " - " + text, EMBEDDING_MODEL)
# key property of Embedding node differentiates different embeddings
cypher = "CREATE (e:Embedding) SET e.key=$key, e.value=$embedding"
cypher = cypher + " WITH e MATCH (n) WHERE id(n) = $id CREATE (n) -[:HAS_EMBEDDING]-> (e)"
session.run(cypher,key=property, embedding=embedding, id=id )
count = count + 1
print("Processed " + str(count) + " " + label + " nodes for property @" + property + ".")
return count
if __name__ == "__main__":
loader = LoadEmbedding(NEO4J_URL, NEO4J_USER, NEO4J_PASSWORD)
loader.load_embedding_to_node_property("Movie", "title")
loader.load_embedding_to_node_property("Movie", "tagline")
print("done")
loader.close()I hope the code above is clear enough to understand. What I want to highlight here is the way embeddings are modelled.

For a movie e.g. Apollo 13 above, it is connected to two Embedding nodes, one for title and another for tagline. The main consideration here is future scalability, when we want to store embeddings of same content from different LLMs and/or versions.
3.3 Create Vector Index
Vector or embedding indexing is an essential part of similarity search and nearest neighbor queries, especially in the fields of machine learning, information retrieval, and natural language processing. Similar to normal index, vector index is to provide highly efficient search response.
Type the following Cypher query in the Text Box in Neo4j Browser:
CALL db.index.vector.createNodeIndex('embedingIndex', 'Embedding', 'value', 1536, 'COSINE')Parameter definition:
- embeddingIndex: index name
- Embedding: label name
- value: property name
- 1536: dimension of vectors. For GPT model, embedding has 1536 dimensions.
- COSINE: similarity function
3.4 First Test: Similarity-based Search
Now let’s do the first test. Assume we want to recommend movies which are similar to The Matrix. In our Movie Graph, we have tagline and title to use for similariy match.
// Find movie The Matrix
MATCH (m1:Movie{title:'The Matrix'}) -[:HAS_EMBEDDING]-> (e:Embedding{key:'tagline'})
WITH m1, e
// Find other movies which have high semantic similarity on tagline
CALL db.index.vector.queryNodes("embeddingIndex", 50, e.value) YIELD node, score
WITH node, score
WHERE score < 1.0 // exclude self
// From the returned Embedding nodes, find their connected Movie nodes
MATCH (m2:Movie) -[:HAS_EMBEDDING]-> (node)
WHERE node.key = 'tagline'
RETURN m2.title, m2.tagline, scoreHere, we use db.index.vector.queryNodes to return top 50 most simiar embeddings of movie tagline, by calculating COSINE similarity between embedding of tagline of movie The Matrix(which is “Welcome to the Real World”), against embeddings of other taglines. Below are the first 5 records returned:
╒═════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│m2.title │m2.tagline │score │
╞═════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The Birdcage" │"Come as you are" │0.9422817826271057│
├─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The Matrix Reloaded" │"Free your mind" │0.9407751560211182│
├─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"Cast Away" │"At the edge of the world, his journey begins." │0.9367693662643433│
├─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"Ninja Assassin" │"Prepare to enter a secret world of assassins" │0.9366204738616943│
├─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"That Thing You Do" │"In every life there comes a time when that thing you dream becomes th│0.9354331493377686│
│ │at thing you do" │ │
├─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤Apparently there are some issues, as the results didn’t seem to be highly relevant, esp. the other 2 episodes of the series were listed with lower scores (rank 2 and 14).
One potential reason is the tagline of The Matrix, “Welcome to the Real World”, didn’t really give much context. This is quite often the challenge .
3.5 Second Test: Combine Similarity-based Search with Collaborative Filtering
Now let’s try to see what other information in the Movie Graph can be leveraged to adjust scores.
One obvious strategy is to look through available relationships between movies, actors and directors. For movies that are directed by the same directors, and/or casted by same actors, they should be more relevant than other movies.
Below is the update code block.
// 1. Find movie The Matrix
MATCH (m1:Movie{title:'The Matrix'}) -[:HAS_EMBEDDING]-> (e:Embedding{key:'tagline'})
WITH m1, e
// 2. Find other movies which have high semantic similarity on tagline
CALL db.index.vector.queryNodes("embeddingIndex", 50, e.value) YIELD node, score
WITH m1, node, score
WHERE score < 1.0 // exclude self
// 3. From the returned Embedding nodes, find their connected Movie nodes
MATCH (m2:Movie) -[:HAS_EMBEDDING]-> (node)
WHERE node.key = 'tagline'
// 4. For returned Movie nodes, count number of same directors and actors
WITH m1, m2, score,
COUNT {(m1) <-[:ACTED_IN]- () -[:ACTED_IN]-> (m2)} AS sameActorCount,
COUNT {(m1) <-[:DIRECTED]- () -[:DIRECTED]-> (m2)} AS sameDirectorCount
// 5. Use sameActorCount and sameDirectorCount to calculate weights and apply to similarity score
WITH m1, m2, score, sameActorCount, sameDirectorCount,
CASE WHEN sameActorCount > 0 THEN 1+log(1+sameActorCount) ELSE 1 END AS actorWeight,
1+sameDirectorCount AS directorWeight
RETURN m2.title, m2.tagline AS tagline, sameActorCount, sameDirectorCount, score, actorWeight * directorWeight * score AS rank
ORDER BY rank DESC;The results did show even though some taglines have higher semantic similarity score, their final rankings become lower when applying collaborative filtering, e.g. Cloud Atlas. Meanwhile, the other 2 episodes of The Matrix trilogy did get a bump in ranking due to the connections of common directors and actors.
4. Future Perspectives
Integrating LLM with the Filtered Knowledge Graph has promising potentials in many aspects, esp. when graph database like Neo4j can handle vector data natively to provide efficient storing, indexing and searching capabilities on regular hardware (no GPU required).
In the future blog posts, I will dive deep into this space and cover more on subjects like: - Improved performance in downstream NLP tasks. - More accurate representation of semantic relations between entities. - Better handling of rare or niche terms that might not be adequately captured by traditional LLMs. - Better filtering and role-based access control over vector search.
Happy embedding!




