
Encoder-Decoder model for Machine Translation

In this article I will try to explain sequence to sequence model which is encoder-decoder. Initially this model was developed for machine translation but later it was useful for many other applications like text summarization, question answering and Video captioning etc.
The reader should know about neural networks, activation functions, loss functions, optimizers, RNN, LSTM, GRU, Bidirectional LSTM. If you are not aware about RNN, LSTM, GRU or Bidirectional LSTM you can take a look at my previous articles.
Sequence to sequence model can be used with below application.
- Machine Translation : In a paper which was released in 2016 Google has mentioned how sequence to sequence surpassed all the previous methods in Machine translation
- Speech Recognition : The same model can be used in recognition of speech and Google mentioned it in another paper.
- Image Captioning :- In 2015 Google mentioned a research paper implemented sequence to sequence model in captioning of image and video.
Architecture of Encoder — Decoder
In a research paper in 2014 google mentioned about sequence to sequence model and how it can be used with in difference size of input and output data. For example, if we want to convert from English words to Hindi, we can see that we have 4 words in input but 6 words in output.
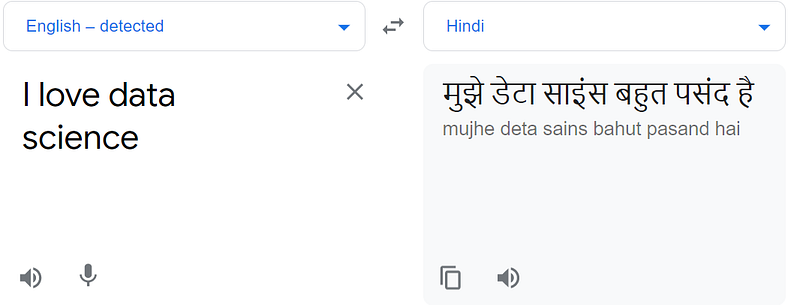
In this kind of problem traditional LSTM architecture can not work because of sequences which required for translations. That’s why sequence to sequence model was introduced for this kind of problems.
The architecture of encoder decoder contains 3 parts. Encoder, Encoder vector and Decoder.
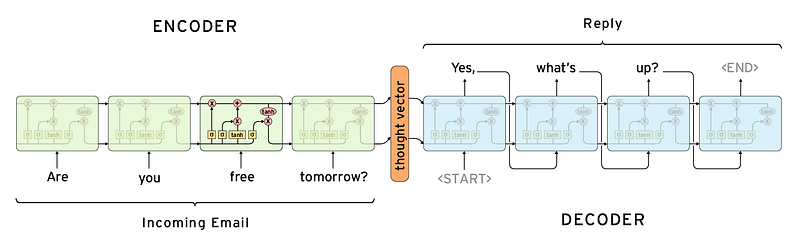
Encoder
Encoder cell are simple RNN cell (LSTM or GRU can be used for better performance ) which takes the input vectors. The input is taken as a single word vector at each and every time stamp but the out is not taken at each state. Output of each encoder cell is rejected and internal state are used to generate encoder vector. The hidden state can be calculated by this formula.
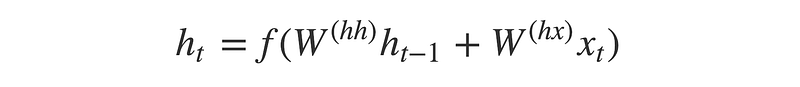
It is the simple calculation of weight applied to hidden state h at t-1 and input x at t. Now, let’s see inside of encoder.
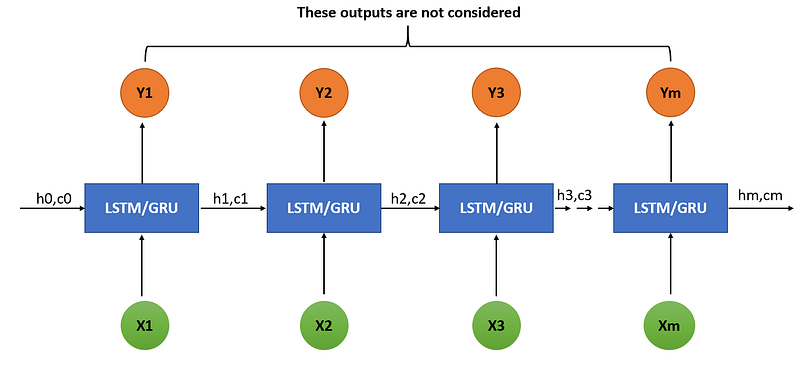
LSTM/GRU cell take one input at a time and by this way we take sequence as an input. X1, X2, X3 …Xm are the input and Y1,Y2,Y3..Ym are the output shown in the architecture. While, h0,c0…hm,cm are the internal state which would be transferred to decoder. Where h is hidden state and c is the weights, both of it can be transferred to decoder. We can take bidirectional or stacked LSTM also in this architecture according to requirement. Here, we are no considering output Y0…Ym but we will take htct as a encoder vector and it would be passed to decoder. Hidden state can be calculates with below formula. It is the simple addition of weights and previous output along with current input.
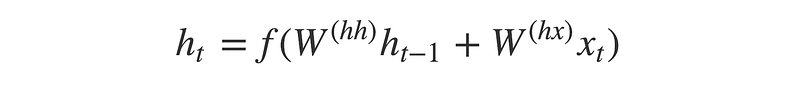
Now, let’s consider and example for better understanding. Here we are passing text in the form of vectors ( In pic original text is shown). The vectors could be in the form of embedding, word2vec or one hot representation.
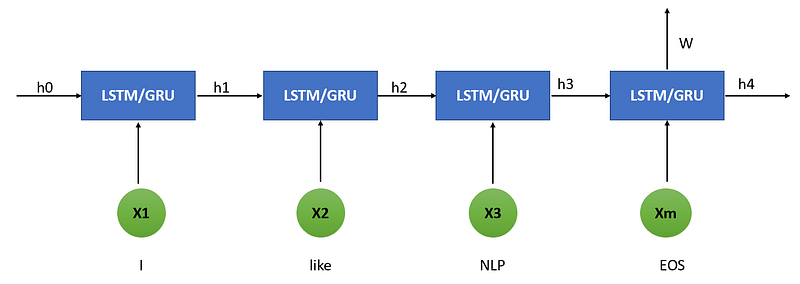
In above image we can see that X1 = I , X2 = like , X3 = NLP and X4 is End of the sentence. All these text data are given to encoder input in the form of vector.
Encoder Vector
- This is the hidden state (h4) produced from the encoder part of the model. Which is shown in above figure and formula is also given.
- This vector store the information in sequence. For example as per property of LSTM it stores the information of precious state, at h4 state it it encapsulate the information for all input elements in order to help the decoder make accurate predictions.
Decoder
- Same as encoder decoder also consist of series of RNN/LSTM. Here we are taking an output at each time stamp t.
- Each RNN cell produce output y_t with the previous output y_t-1 and hidden state ht-1. Which can be calculated with below formula
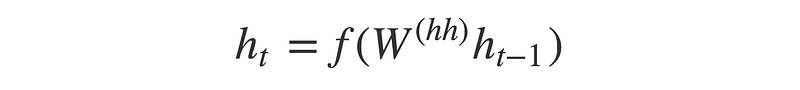
- Output y_t is calculated with ht and y_t-1. So we can calculate y_t with below formula. Also as mentioned in a research paper of encoder decoder we use softmax function to determine the output as this prediction is probabilistic.
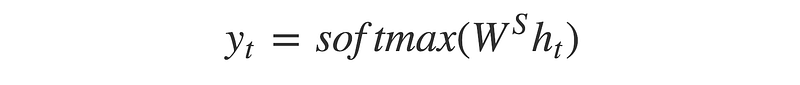
To continue with example mentioned above the embedded vector is given as an input to decoder. To understand starting and ending of the sentence we will add start_ at the starting and _end at the ending of the sentence in the training dataset. So our training data will look like this.
X = “I Love NLP”
Y = “Start_ मुझे एनएलपी पसंद है _End”
Visually this can be shown as below. Input as a encoder vector and hidden state are given to decoder input. The decoder decode the starting of the sentence from Start_ and it will convert the sentence into hindi. The decoder will understand end of the sentence with _End word.
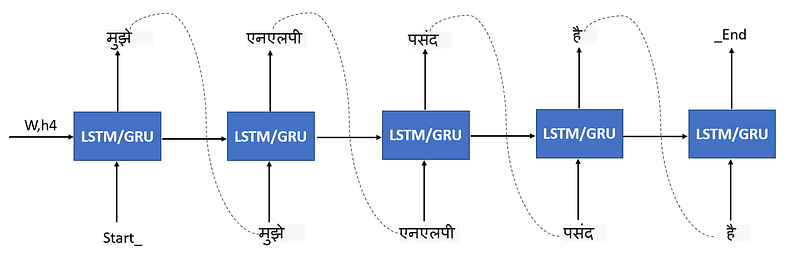
At each and every stage the loss is calculated between actual and predicted words y and ŷ. Based on calculated loss the weights are getting updated in back propagation and finally the sentence would be converted in Hindi.
Implementation of Encoder Decoder with Keras
I have taken dataset for the training from here. Code can be found here.
Import all the required libraries
import numpy as npimport tensorflow as tffrom tensorflow import kerasimport pandas as pd
batch_size = 64 # Batch size for training.epochs = 100 # Number of epochs to train for.latent_dim = 256 # Latent dimensionality of the encoding space.num_samples = 10000 # Number of samples to train on.# Path to the data txt file on disk.Import Dataset of Hindi and English sentences
hindi_sen = open('IITB.en-hi.hi').read().split("\n")[:-1]eng_sen = open('IITB.en-hi.en').read().split("\n")[:-1]Create a set of input and target character in which we will take unique character which are used in Hindi and English sentences.
# Vectorize the data.input_characters = set()target_characters = set()for char in input_text: for chars in char: if chars not in input_characters: input_characters.add(chars)for char in target_text: for chars in char: if chars not in target_characters: target_characters.add(chars)input_characters = sorted(list(input_characters))target_characters = sorted(list(target_characters))num_encoder_tokens = len(input_characters)num_decoder_tokens = len(target_characters)max_encoder_seq_length = max([len(txt) for txt in input_text])max_decoder_seq_length = max([len(txt) for txt in target_text])print(“Number of samples:”, len(input_text))print(“Number of unique input tokens:”, num_encoder_tokens)print(“Number of unique output tokens:”, num_decoder_tokens)print(“Max sequence length for inputs:”, max_encoder_seq_length)print(“Max sequence length for outputs:”, max_decoder_seq_length)The output will be like this in this we will take number of sentences, max sentences length and input / output token which will contain unique letters .
Number of samples: 10000
Number of unique input tokens: 93
Number of unique output tokens: 154
Max sequence length for inputs: 233
Max sequence length for outputs: 346Now, convert the data into dictionary which will take data from unique character and give a numerical value to it.
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])Output would be like this .
‘A’: 31, ‘B’: 32, ‘C’: 33, ‘D’: 34, ‘E’: 35, ‘F’: 36, ‘G’: 37, ‘H’: 38, ‘I’: 39, ‘J’: 40, ‘K’: 41, ‘L’: 42, ‘M’: 43, ’N’: 44,Next step would be embedding of the data. This step will take encoder input , decoder input and decoder output data. We will take dimensions according to input and output sequence length. Also the data would be one hot encoded and padded with 0 where the value is not present.
encoder_input_data = np.zeros((len(input_text), max_encoder_seq_length, num_encoder_tokens), dtype="float32")
decoder_input_data = np.zeros((len(input_text), max_decoder_seq_length, num_decoder_tokens), dtype="float32")
decoder_target_data = np.zeros((len(input_text), max_decoder_seq_length, num_decoder_tokens), dtype="float32")
for i, (input_texts, target_texts) in enumerate(zip(input_text, target_text)): for t, char in enumerate(input_texts): encoder_input_data[i, t, input_token_index[char]] = 1.0 encoder_input_data[i, t + 1 :, input_token_index[" "]] = 1.0 for t, char in enumerate(target_texts):# decoder_target_data is ahead of decoder_input_data by one timestep decoder_input_data[i, t, target_token_index[char]] = 1.0 if t > 0:# decoder_target_data will be ahead by one timestep# and will not include the start character. decoder_target_data[i, t - 1, target_token_index[char]] = 1.0 decoder_input_data[i, t + 1 :, target_token_index[" "]] = 1.0 decoder_target_data[i, t:, target_token_index[" "]] = 1.0Now we will define Encoder and Decoder model. Which contains embedded data from previous step, LSTM layer, and dense layer . Here, as per architecture we will not consider output on encoder we will only take state h and c from encoder and pass it to decoder.
# Define an input sequence and process it.encoder_inputs = keras.Input(shape=(None, num_encoder_tokens))encoder = keras.layers.LSTM(latent_dim, return_state=True)encoder_outputs, state_h, state_c = encoder(encoder_inputs)# We discard `encoder_outputs` and only keep the states.encoder_states = [state_h, state_c]# Set up the decoder, using `encoder_states` as initial state.decoder_inputs = keras.Input(shape=(None, num_decoder_tokens))# We set up our decoder to return full output sequences,# and to return internal states as well. We don't use the# return states in the training model, but we will use them in inference.decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True)decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)decoder_dense = keras.layers.Dense(num_decoder_tokens, activation="softmax")decoder_outputs = decoder_dense(decoder_outputs)# Define the model that will turn# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)Now we can train the model. Here optimization function is rmsprop and I have trained model up to 100 epochs.
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit([encoder_input_data, decoder_input_data],decoder_target_data,batch_size=batch_size,epochs=epochs,validation_split=0.2,)
# Save modelmodel.save("s2s")The results after training up to 100 epochs is
Epoch 93/100
125/125 [==============================] - 11s 86ms/step - loss: 0.0232 - accuracy: 0.9929 - val_loss: 0.0399 - val_accuracy: 0.9903
Epoch 94/100
125/125 [==============================] - 11s 87ms/step - loss: 0.0232 - accuracy: 0.9928 - val_loss: 0.0399 - val_accuracy: 0.9903
Epoch 95/100
125/125 [==============================] - 11s 87ms/step - loss: 0.0230 - accuracy: 0.9929 - val_loss: 0.0400 - val_accuracy: 0.9904
Epoch 96/100
125/125 [==============================] - 11s 86ms/step - loss: 0.0230 - accuracy: 0.9929 - val_loss: 0.0397 - val_accuracy: 0.9902
Epoch 97/100
125/125 [==============================] - 11s 86ms/step - loss: 0.0228 - accuracy: 0.9929 - val_loss: 0.0392 - val_accuracy: 0.9905
Epoch 98/100
125/125 [==============================] - 11s 86ms/step - loss: 0.0230 - accuracy: 0.9929 - val_loss: 0.0421 - val_accuracy: 0.9897
Epoch 99/100
125/125 [==============================] - 11s 86ms/step - loss: 0.0230 - accuracy: 0.9928 - val_loss: 0.0397 - val_accuracy: 0.9904
Epoch 100/100
125/125 [==============================] - 11s 87ms/step - loss: 0.0230 - accuracy: 0.9928 - val_loss: 0.0391 - val_accuracy: 0.9906WARNING:absl:Found untraced functions such as lstm_cell_layer_call_fn, lstm_cell_layer_call_and_return_conditional_losses, lstm_cell_1_layer_call_fn, lstm_cell_1_layer_call_and_return_conditional_losses, lstm_cell_layer_call_fn while saving (showing 5 of 10). These functions will not be directly callable after loading.
WARNING:absl:Found untraced functions such as lstm_cell_layer_call_fn, lstm_cell_layer_call_and_return_conditional_losses, lstm_cell_1_layer_call_fn, lstm_cell_1_layer_call_and_return_conditional_losses, lstm_cell_layer_call_fn while saving (showing 5 of 10). These functions will not be directly callable after loading.INFO:tensorflow:Assets written to: s2s/assetsINFO:tensorflow:Assets written to: s2s/assetsWhat’s Next :
In the next part of this series, we will use attention for english to hindi translation.
References