
My Thoughts on Apple Intelligence
Leveling the Stakes & Betraying the Essence

Finally, Apple has shown its AI cards by presenting Apple Intelligence, a suite of foundation models that will significantly change how Apple consumers use their products.
While still having to prove itself ‘in the wild,’ it was a powerful presentation that, at least from the average user's perspective, levels the stakes with its competitors, mainly Google and Microsoft, regarding consumer-level AI at the UI/UX level.
However, yesterday’s presentation was also an acknowledgment of defeat in some regards and, more importantly, a potential betrayal of one of the foundations upon which Apple built its brand, data privacy, to the point that some very relevant people are already threatening to ban Apple products in their companies.
You are probably sick of AI newsletters talking about how this or that **just** happened. These newsletters abound because coarsely talking about events and things that already took place is easy, but the value provided is limited, and the hype exaggerated.
However, newsletters talking about what will happen are a rare sight. If you’re into easy-to-understand insights looking into the future of AI before anyone else does, TheTechOasis newsletter might be perfect for you.
🏝️🏝️ Subscribe today below:
The Essence of Apple Intelligence
If we have to summarize Apple Intelligence in one sentence, that would be ‘Impressive, but nothing close to extraordinary, and with quite a few catches really worth discussing.’
Capabilities
First, I will provide you with a brief summary of their announcements, as you probably already know most of them.
- Apple announced a series of AI-driven features and updates across its product lineup. iOS 18 will introduce custom emoji creation, known as Genmoji, so that you can generate brand-new emojis based on text descriptions.
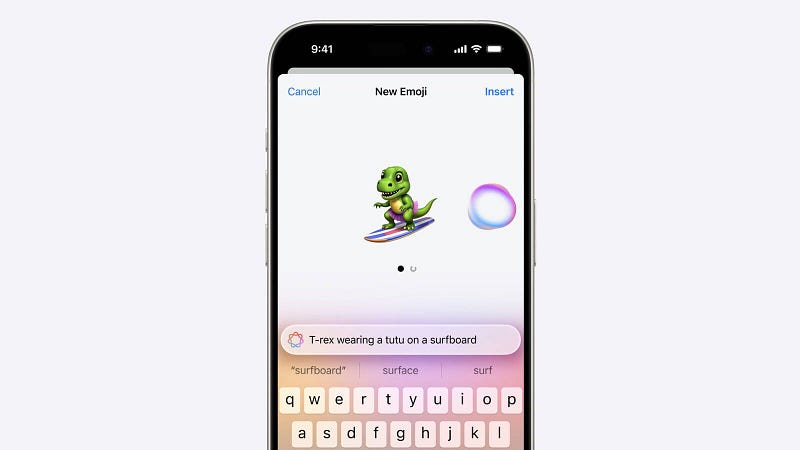
- It will include advanced photo editing via commands, audio transcription, and smart content summaries in Safari, alongside a much-desired and longed-for improvement on Siri. But more on our most hated conversational assistant ever later.
- At the laptop level, macOS Sequoia will leverage AI for enhanced writing tools and image editing, featuring improved system settings and new gaming functionalities.
- Moving on to iPad, they presented a new Calculator app — was this really worth an announcement? — advanced note-taking, and accessibility features like eye tracking.
- The iPad also got one of the coolest-looking AI enhancements with Math notes. You can perform math using the iPad pen, and the underlying AI automatically computes any calculation you write down, even matching your handwriting style. This is an absolute ‘nobody asked for’ feature, but it was quite technologically impressive nonetheless.

But now we move on to Apple Intelligence’s architecture, this was by far the most intriguing part.
Architecture
For years, Apple has been extremely zealous about protecting its users’ privacy at all costs. However, this is a huge issue when dealing with large language models (LLMs).
LLMs are very burdensome on your device's processing units and extremely memory-demanding, especially at inference, which is Apple's entire AI value proposition.
For reference, a very small Language Model with ‘just’ 7 billion parameters, absolutely minuscule in today’s terms, at the standard float16 (2-byte) precision level occupies a staggering 14GB of RAM.
Worryingly, some of Apple's most powerful smartphones, like the iPhone 15 family, have just 8GB RAM, which is too little even for that model.
In case you’re wondering, LLMs allegedly can’t be stored in flash memory, of which an iPhone has 128+ GB. The reason for this is that, by design, the processing units must interact with the weight files continuously, making latency unbearable unless the model is easily retrievable, aka it has to be deployed entirely on RAM.
However, last year, Apple presented research called ‘Flash LLMs’ in which they fiddled with the idea of doing per-token prediction loads from flash to RAM of certain parts of the model, but Apple has not acknowledged the use of such a technique for this announcement.
From what Apple has been publishing, the approach seems to be more like a full-RAM deployment with LoRA adapters on different fine-tuned cases depending on the user’s request, but I will leave this discussion to a future blog post this week.
Still, the demos they showed yesterday were pretty interesting, and they seem to have fully committed to the “on-device” paradigm, as they argued yesterday that most of the LLMs would be running inside the device.
This is crucial because, this way, data never leaves your iPhone, iPad, or Mac to process your request. But there’s a catch.
The Hard Truth about LLMs
The “on-device” models must be insanely small and, therefore, not state-of-the-art.
Considering that the smartphones with Apple Intelligence compatibility will be only the iPhone 15 Pro and Max models, we know they will have just 8 GB of RAM, leaving very little room not only for the models themselves (Apple Intelligence encompasses a complete family of models) but also for their KV Cache.
The KV Cache is generated by an LLM during inference to avoid redundant attention mechanism activation recomputation. In layman’s terms, avoiding recomputing redundant data.
This is key to making the entire process economically and computationally tractable, but it has serious memory constraint considerations for large sequences.
For a deep dive on the KV Cache, read here.
But how large are these models? The size could be determined by the number of parameters or the parameter precision.
- If they decided to train very small models, considering RAM capacity, their size couldn’t be larger than 3 billion parameters, period. Again, I’m assuming they aren’t storing the models in flash memory, as they didn’t explicitly mention that. Considering this, the models can’t be larger than 3B or might even be smaller, considering Apple released the OpenELM family in the 1B range not long ago.
- If they decide to perform post-training quantization instead, you can train a very large model and then quantize it to fit in smaller places. For example, if a 12 billion parameter model reduced the per-parameter precision to 3.5 bits (from the standard 16 bits), the model would go from a size of 24 GB to just 7 GB.
My bet is they did both.
We know that they compared their models to Microsoft’s Phi-3 model family, so we can assume we are talking about similar-sized models. However, they also acknowledged in a blog post that on-device models (and the KV Cache, too) were quantized to 3.5 bits.
Overall, this is quite the demonstration of how to handle LLMs in very small devices—the most impressive I have seen, at least. Yet, some requests go beyond what their current on-device models can offer.
Private Cloud Compute
For that, they also announced Private Cloud Compute, a new cloud solution running on Apple Silicon, where another set of AI models, the Apple Server family, will be stored.
This means that the devices will have an algorithm that evaluates the complexity of the user’s request, driving the request to these servers for computation when required. In other words, for the most complex requests, your data is guaranteed to leave your device digitally.
Apple knows this is a dealbreaker for some.
For that reason, they immediately mentioned how they would enable independent experts to validate that while data leaves the device, neither Apple nor any other third party has access to it.
That said, security breaches increase with this risk, and that’s a fact that Apple seems happy to deal with; we’ll have to see about users.
This Twitter thread by a cryptography professor goes into great detail on how much effort Apple put into creating this secure cloud. That said, as the proper writer mentions, your data will still go out into the Internet.
But Apple saved one final bomb for last: OpenAI.
Coming to your iPhone and your personal data: ChatGPT
For some requests that even the Apple Server models can’t handle, Apple announced that ChatGPT, the GPT-4o version to be precise, will be embedded into Siri, offered through a permissioned system, meaning that you will be offered the chance to decide whether the request is sent to OpenAI.
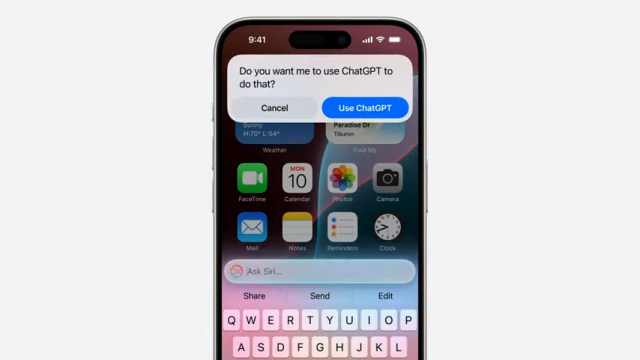
For starters, this is an outright acknowledgement that their AI practice has still to mature and, consequently, their AI models aren’t even close to what ChatGPT offers.
This is obvious, considering they knew the ChatGPT announcement would be controversial. Thus, they really must be behind in terms of the quality of their models.
And let me be clear: with Apple generating 4 times more revenue than NVIDIA’s projected revenues for 2024 and having performed the biggest stock buyback in capitalism history a month ago, it’s intolerable they are so behind in their AI efforts despite being rich enough to buy entire countries.
But enough of my rant, let’s get back to ChatGPT.
A New Era for Apple Privacy
Please do not confuse this announcement with your ChatGPT app; your current ChatGPT does not have access to your iPhone’s data, but this model will.
Focusing specifically on having to approve using ChatGPT, besides the UI nuisance of having to accept data transmission, this seems like a nice way for Apple to ‘empower’ users about their choice of sending data to OpenAI, when in fact, what they are doing is distracting media from the fact that data will indeed go into OpenAI’s servers.
Although both Apple and OpenAI have guaranteed that the data will not be used to train future OpenAI models, this claim now depends on the honesty of two actors, not just one.
In other words, Apple now has to trust that OpenAI will always hold its end of the bargain. Simply put, for the first time, Apple will have to trust your entire personal data to a third party.
Apple allowed people to share their information with companies like Meta until it regressed that possibility in 2022. But this is the first time that in a highly private-sensitive topic, such as your user’s entire private data, the company will share the penance with a third party.
Coming from a company many believe used copyrighted data to train its models without permission means many more certainly won’t trust the AI company. Examples include Elon Musk, who claimed that he could even prohibit using iPhones in his companies.
It's a nightmare for zealous privacy upholders, but let’s be honest: Overall, it’s a clear PR win for Apple.
Entering the AI game in Apple’s style
For a long time, ever since I wrote about their research, such as Flash LLMs or Ferret-UI, I’ve argued that Apple would never play the frontier AI game.
Their goal was simply to make AI totally accessible through edge devices, that’s all they had to do to win.
AI at the edge, or the capacity to run AI models on end devices, is one of the most promising ways to democratize access to these models. Sadly, besides warfare and, more recently, Microsoft’s AI Copilot PCs, the dream of having frontier AI running on small devices was just that:
A dream.
Now, Apple, the king of narrative and branding, has positioned itself as the ‘on-device’ AI company, which would be quite unfair considering how Google and Microsoft have been playing this game for months now with Google Pixel smartphones and Microsoft’s PCs.
However, I bet that’s precisely what investors will price in, desperate to buy into a company that has consistently lagged behind the other Magnificent Seven stocks (all but Tesla) for almost a year.
The stock is up 6% today, June 11th, nearing Microsoft to become the most valuable company in the world.
Moreover, Apple has historically proven an expert in not starting an industry but eventually taking the early adopter’s lunch, with examples like the phone or headphone industries.
Will consumer-end AI follow the same path once again? And what’s your take on it?
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.




