
SPIN: Self-play Fine-tuning to Improve LLMs without Additional Data
LLM self-training
Synthetic data generated by LLMs are successfully used to train smaller LLMs. Phi-2 and Zephyr are two very good examples of popular LLMs trained on synthetic data. But these data are additional data, i.e., we need another, better, LLM to generate them.
Can the LLM improve its fine-tuning using synthetic data that it has generated by itself, i.e., without using any additional data or external LLMs?
To answer this question, Chen et al. propose SPIN, a method for self-training LLM:
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
SPIN uses two “player” models. The main player is trained to distinguish LLM responses from human responses by minimizing a specific value. This value reflects the degree of belief that a given response, given a prompt, originates from a human rather than the LLM. The opponent player model seeks to improve the LLM, making its responses indistinguishable from human data for the main player.
Both the main and opponent players are iteratively updated given their respective feedback.
For fine-tuning, SPIN requires only the initial model and the existing supervised fine-tuning dataset, enabling LLM self-improvement. The initial model used by the authors is Zephyr trained without DPO:
SPIN surpasses the performance achieved after DPO with additional preference data.
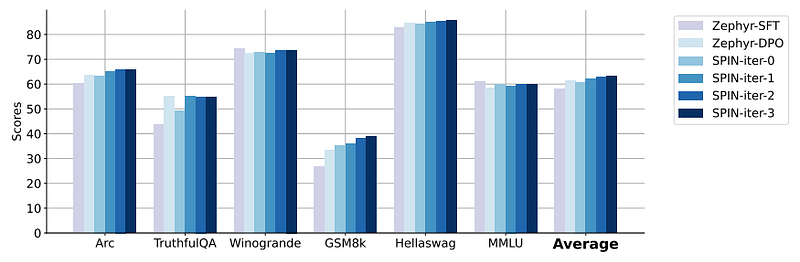
Iterative training is more effective than training for more epochs, with SPIN maintaining performance even with extended training durations.
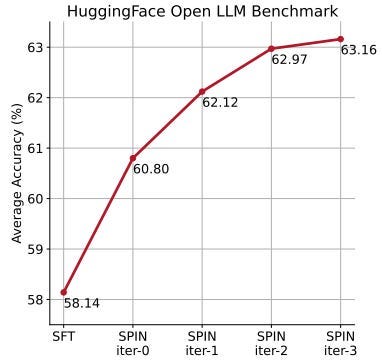
The fact that SPIN outperforms DPO without additional data is quite impressive. The paper is, however, not very clear on how difficult it is to find the right hyperparameters. SPIN and its players have a lot of similarities with GANs (Generative Adversarial Networks) which are well-known to be difficult to train.
This article was originally published in the The Weekly Kaitchup:





