
Embedding: Types, Use cases and Evaluation (Part 3 of RAG Series)
Making computers understand Text

This is part 3 of the “Retrieval-Augmented Generation (RAG) — Basics to Advanced Series”. Links to other blogs in the series are at the bottom of this blog. Taking forward from part 1 (RAG Basics) and part 2 (Chunking), in this blog we will focus on the “Embedding” component which is relevant for embedding of chunks in the source content and the query. (highlighted in Blue). Since, fundamentally the concept is similar, we will cover this together.
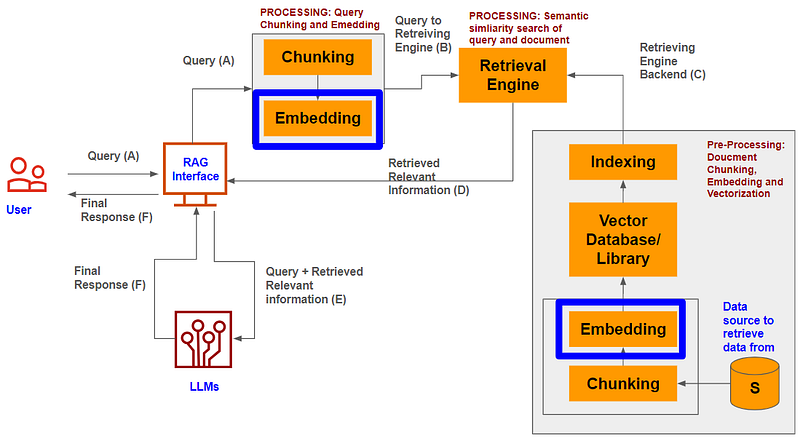
What is Embedding?
In the last blog (Chunking), we discussed how we can break the source content (S) and the query into small chunks using various chunking strategies.
Now, as we know computers understand numbers, so these chunks of text have to be encoded to numbers (some mathematical form) which the computers can read, understand and process. Furthermore, we also would expect numbers to ensure that there are relationships between each word/chunk with the other words/chunks as well.
This conversion of chunks of text into a mathematical form is called embedding.
Since the models would use these numbers for computation, the numbering should be — meaningful and structured. To enable this there are some core principles behind embedding techniques:
- Ensure that number retains the contextual understanding of the text
- Ensure that number retains the semantic and syntactic properties of the text
- Ensure that number retains the linear relationship between words
In order to adhere to these principles, Embedding algorithms necessitate more than simply assigning numerical values to words/chunks. It requires a broader representation of these numbers which is achieved through high dimensional vectors.
Given below is an illustration of how embedding works in real world applications. As mentioned, embedding converts the words/chunks/sentences into vectors and the values of these vectors are such that the numbers in the vectors retain the contextual, semantic and syntactic properties. For example: as seen in the table below, the sea animals vectors are very similar to each other and are distinct from other embedding vectors for laptop/computer, man/women/girl. Note that embedding vectors can go into a very high n-dimensional space.
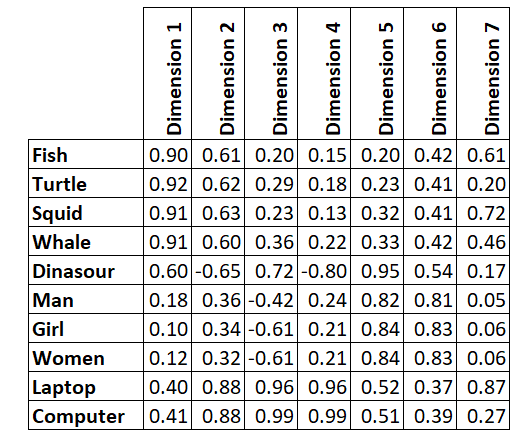
Note that Embedding is certainly not a new (RAG) concept in fact all NLP models like RNNs, LSTMs, ELMo, BERT, AlBERT and not GPT have thrived on the basis of evolution of Embedding methodologies.
It would not be incorrect to say that the better the sophistication of Embedding, the better would be model outcome — as embedding helps the model understand the “relationship” between the texts — both in terms of context and semantics. Over the years, the embedding algorithms have made significant progress, resulting in faster processing speeds and improved accuracy in generating language sequences and other downstream tasks.
Types of Embedding
While we have used text embedding as a specific example, Embeddings can also be utilized for various types of data, such as images, graphs, and more.
- Word Embeddings: Embedding of Individual words. Models: Word2Vec, GloVe, and FastText
- Sentence Embeddings Embedding of entire sentences as vectors that capture the overall meaning and context of the sentences. Models: Universal Sentence Encoder (USE) and SkipThought.
- Document Embeddings Embedding of entire sentences capturing the semantic information and context of the entire document. Models: Doc2Vec and Paragraph Vectors
- Image Embeddings — captures different visual features. Models: CNNs, ResNet and VGG
- User/Product Embeddings represent users/products in a system as vectors. Capture user/products preferences, behaviors, attributes and characteristics. These are primarily used in recommendation systems.
Embedding — key use cases
Having performed embedding it is critical to make a note of how these embeddings are used downstream:
- Semantic Similarity and Distance: One of the most popular applications of RAG (Retrieval-Augmented Generation) is measuring the semantic similarity between texts based on a given query. By organizing the vectors in a meaningful manner, embedding enables the underlying relationships between the query and the document, simplifying the process of comparing and retrieving relevant results.
- Dimensionality Reduction: Text embeddings result in the conversion of text into lower-dimensional vectors. This conversion is advantageous as it reduces the dimensionality of the inputs, leading to improved computational efficiency.
- Transfer Learning: Text embeddings facilitate transfer learning by enabling a model to be pre-training on a large dataset and then fine-tune on a smaller, domain-specific dataset.
- Machine Learning Models: Embedding is a key step for any machine learning modeling — clustering, classification etc.
- Multi-modal support: Vector databases can store embeddings of multimodal data — like image captioning, visual question answering, or speech recognition. Given the vectors are stored in similar manner this enables LLMs to integrate different cross functional tasks.
Common Embedding models (from RAG perspective)
By training a neural network on a large corpus of text, embeddings are obtained. This training allows the network to assign similar vectors in the embedding space to words that are used in similar contexts. Consequently, the embeddings capture the semantic relationships between words and the specific contextual nuances in which they are employed.
As you can expect, there are a plethora of models available for embedding. Given below are some key models from established players like Open AI, Mistral etc.
- Cohere’s Embedding: Powerful for processing short texts with under 512 tokens. For longer texts, the API truncates input to fit the maximum context length and embed the text.
- Mistral Embedding: Strong embedding for AI/ML modeling like text classification, sentiment analysis etc. Embeddings are renowned for their user-friendliness, resilience, and capacity to handle vast amounts of data. This empowers businesses to utilize language embeddings for improved data insights and innovative AI-driven solutions.
- Open AI Embeddings: Open AI is currently one of the market leaders for Embedding Algorithms. Of the all, OpenAI second-gen text-embedding model, ada-002, has proven to give top-notch results across various use cases. Furthermore, the model is cost-effectiveness, and user-friendliness. Open AI Embedding models are trained for specific use cases like Text Similarity, Text Search and Code search. The common Embedding algorithms are ada, babbage, curie, davinci etc.
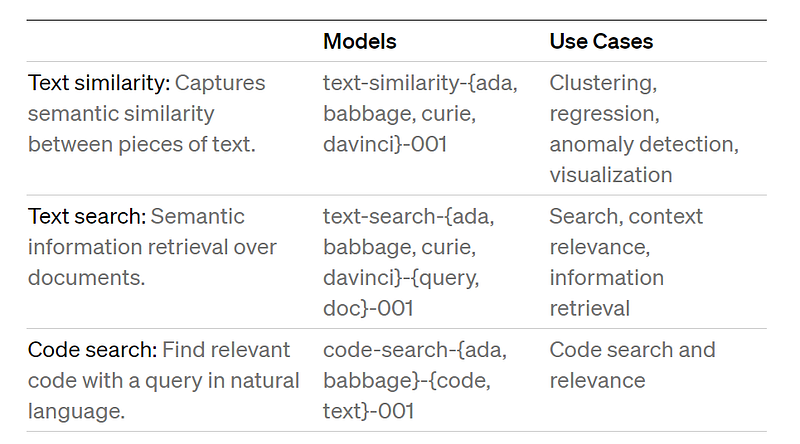
One key aspect to emphasize here is that the costing of these Embedding models are very different and could be steep for some strong models — these are a function of Sequence length and Embedding dimensions — therefore it is imperative that appropriate Embedding algorithms are used for the given use cases.
Note that it is becoming really common to create your own customized Embedding model for specific use cases.
Evaluating the performance of Embeddings models
As you would have acknowledged by now that there are a lot of Embeddings algorithms available in the market and more are being developed everyday. This raises a key question, how can we measure the effectiveness of one Embedding algorithm over others. One of the most common and sophisticated way of how this is done is using Hugging Face’s Massive Text Embedding Benchmark (MTEB) Leaderboard. MTEB is a useful tool for assessing the effectiveness of different text embedding models in a wide range of embedding tasks.
MTEB offers a comprehensive explanation of the leaderboard’s objective and provides valuable insights into various text embedding models. MTEB evaluates the performance of the Embedding model across 8 tasks (text mining, classification, clustering, pair classification, reranking, retrieval, semantic textual similarity (STS), and summarization) and 58 datasets.
P S: I plan to write a blog on MTEB sometime soon.
Conclusion
In conclusion, embedding plays a crucial role in the development and success of NLP models. By transforming words or sentences into numerical representations, embedding allows NLP models to understand and process textual data effectively. Embedding not only captures the semantic meaning of words but also enables the models to recognize relationships and similarities between different words or sentences. With the availability of pre-trained embedding models and resources like MTEB, researchers and developers can evaluate and compare the performance of various embedding techniques. As NLP continues to advance, embedding will remain a key component in enhancing the accuracy and performance of NLP models, enabling them to tackle complex language tasks with greater precision.
Here is a view of what’s in the series, feel free to let me know if you would like me to cover any specific aspect.
2. Pre-processing block — Chunking (part 2): strategies, considerations and optimization
3. Pre-processing block — Embedding (part 3): Types, Use cases and Evaluation. — this blog
4. Pre-processing block — Vector Databases and Vector Libraries (part 4)
5. Evaluation of RAG performance (part 5) — is RAG performing per expectations
6. How to improve RAG performance (part 6)
Do like and share and tag as much to help each other succeed.
Disclaimer: The views expressed in this article are opinions of the author in his personal capacity and not of his employer.



