
Embedding similarity search

Searching for something similar is a key concept in many information retrieval systems, recommendation engines, synonyms searching, etc. Basically everywhere, where exact search through the database is not an option (as an example, you cannot just save the word and also save the representation its meaning and context).
In that case, most of the tools, deep learning algorithms or statistical ML methods are operating with initial items representations in the form of vectors in high dimensional space, called embeddings. This allows to represent initial items (like text, images, etc.) in much more efficient and flexible way also saving its features and sometimes even context.
So, basically searching for similar items means searching for its vector representations that are close to each other in their representation space (finding Euclidean or other distance between them).
Considering the above, searching for the similar item will follow the algorithm:
- Represent all the items from the dataset as an embeddings
- Define a metric for a pair of embeddings. This measure could be cosine similarity, Euclidean distance or dot product.
- Search the embedding of the query object
- Select the embeddings close to the query object
Retrieving those results is a k-nearest neighbours search that can be done in a several different ways. If there are not so many items in the dataset (few hundreds or thousands), it is possible to compute distance metric between all vectors. Although if result is needed in the real time, and the dataset is really big, searching for nearest neighbours needs to be approximate. This can be done by creating an index data structure that allows fast search of the items.
Lets review the different ways of searching k-nearest neighbours, from the simplest, to the methods that can be used for the big datasets:
Using direct calculation
From scratch using numpy: the simplest approach is to compute the distance from query vector X to every other vector in S, and identify the k vectors that have minimum distances. As all the possible matches are evaluated, this is a brute force search. This operation requires the computation of N*N distances and then finding the bottom k values:
import numpy as np
N = 10000
d = 10
k = 5
# create an array of N d-dimensional vectors (our search space)
S = np.random.random((N, d)).astype('float32')
# create a random d-dimensional query vector
x = np.random.random(d)
# compute distances
distances = np.linalg.norm(S - x, axis = 1)
# select indices of vectors having the lowest distances from the X
neighbours = np.argpartition(distances, range(0, k))[:k]Using scikit-learn: scikit-learn provides a simple way to search for k-nearest neighbours (using sklearn.neighbors.NearestNeighbors ):
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(n_neighbors=k)
knn.fit(S)
# select indices of k nearest neighbours
neighbours = knn.kneighbors([x], return_distance = False)
print(neighbours)Results are the same as with using numpy (as exact distances are computed). In both approaches we need to fit the whole matrix of distances into memory, which may be a little problematic.
Using approximate similarity
When dataset is much bigger then RAM or the answer should be provided in real-time — there are 2 main approaches to approximate embedding similarity: tree-based approach and hashing approach.
Basic idea is similar to building database indexes. In tree-based approaches is to recursively partition the data in a divide-and-conquer fashion, which puts similar vectors near each other in the tree. Tree indexes require large amounts of memory, and the performance degrades with higher-dimensional data.
In hash-based approach, the idea is to learn a model that converts an item into a code, where similar items will produce the same or similar code. This approach significantly reduces the memory needed.
There are several open source libraries that implement approximate similarity matching techniques. Let’s review the most popular of them.
Non-Metric Space Library (NMSLIB) The core-library does not have any third-party dependencies. It is included in Amazon Elasticsearch Service. It is written in C++ and can be used both ways — directly in C++ and Python.
The queries can be answered either exactly, i.e., by returning a complete result set that does not contain erroneous elements, or, approximately, e.g., by finding only some neighbors. Thus, the methods are evaluated in terms of efficiency-effectiveness trade-offs rather than merely in terms of their efficiency. One common effectiveness metric is recall, which is computed as an average fraction of true neighbors returned by the method (with ties broken arbitrarily).
import hnswlib
import numpy as np# Declaring index
p = hnswlib.Index(space='l2', dim=d) # possible options are l2, cosine or ipp.init_index(max_elements=N+1, ef_construction=100, M=16)
# Controlling the recall by setting ef:
# higher ef leads to better accuracy, but slower search
p.set_ef(10)
p.add_items(S)
# Query the elements for themselves and measure recall:
labels, distances = p.knn_query(S, k=1)
print("Recall:", np.mean(labels.reshape(-1) == np.arange(len(S))), "\n")# Query the elements for themselves and measure recall:
labels, distances = p.knn_query(x, k=k)
print(labels[0])As we are testing on a very small dataset, used search methods do not necessarily outperform brute-force search. Typically, the larger is the corpora, the larger is the improvement in efficiency over the brute-force search.
Faiss (Facebook AI search)
Faiss is a library made by Facebook to be efficient with large datasets and high dimensional sparse data. It contains several methods for similarity search. Most of them, use a compressed representation of the vectors and do not require to keep the original vectors. This generally comes at the cost of more approximate search but these methods can scale to billions of vectors in main memory.
Faiss is built around an index type that stores a set of vectors, and provides a function to search in them with L2 and/or dot product vector comparison. Some index types are simple baselines, such as exact search. Most of the available indexing structures correspond to various trade-offs with respect to
- search time
- search quality
- memory used per index vector
- training time
- need for external data for unsupervised training
There are several different possibilities to chose index types using Faiss:
- if there will be not that many searches, memory is a concern and exact match is needed, then the best choice is “Flat” index
- if dataset is big and memory is a concern then NHSW need to be chosen. As well as in NMSLIB, we chose the M parameter. The 4 <= M <= 64 is the number of links per vector, higher is more accurate but uses more RAM. The memory usage is (d * 4 + M * 2 * 4) bytes per vector.
Also there are different settings for the clustering of the dataset has to be done beforehand. After clustering, “Flat” parameter just organizes vectors into the buckets, and does not compress them, the storage size is the same as that of the original dataset. The tradeoff between speed and accuracy is set via the nprobe parameter which can reduce dimensionality, make quantization of the vectors into M 4-bit codes etc (more here).
import faiss
import numpy as np# Param of PQ
M = 8 # The number of sub-vector. Typically this is 8, 16, 32, etc.
nbits = 8 # bits per sub-vector. This is typically 8, so that each sub-vec is encoded by 1 byte
# Param of IVF
nlist = 100 # The number of cells (space partition). Typical value is sqrt(N)
# Param of HNSW
hnsw_m = 32 # The number of neighbors for HNSW. This is typically 32
# Setup
quantizer = faiss.IndexHNSWFlat(d, hnsw_m)
index = faiss.IndexIVFPQ(quantizer, d, nlist, M, nbits)
# Train
index.train(S)
# Add
index.add(np.array([x])
# Search
index.nprobe = 8 # Runtime param. The number of cells that are visited for search.
dists, ids = index.search(x=np.array([x])[:3], k=k)
print(ids)Spotify’s Annoy library
Annoy is a C++ library with Python bindings that builds random projection trees. An index is built with a forest of k trees, where k is a tunable parameter that trades off between precision and performance. It also creates large read-only, file-based data structures that can be shared among many processes.
from annoy import AnnoyIndex
import randomt = AnnoyIndex(d, 'angular') # Length of item vector that will be indexed
for i in range(len(S)):
t.add_item(i, S[i])
t.build(10) # 10 trees
print(u.get_nns_by_vector(x, k)) # will find the k nearest neighboursConclusions
Here represented benchmarks for all libraries with the different datasets and distance metrics. As we can see, that as dataset is smaller — the less difference is between speed of work of different methods.
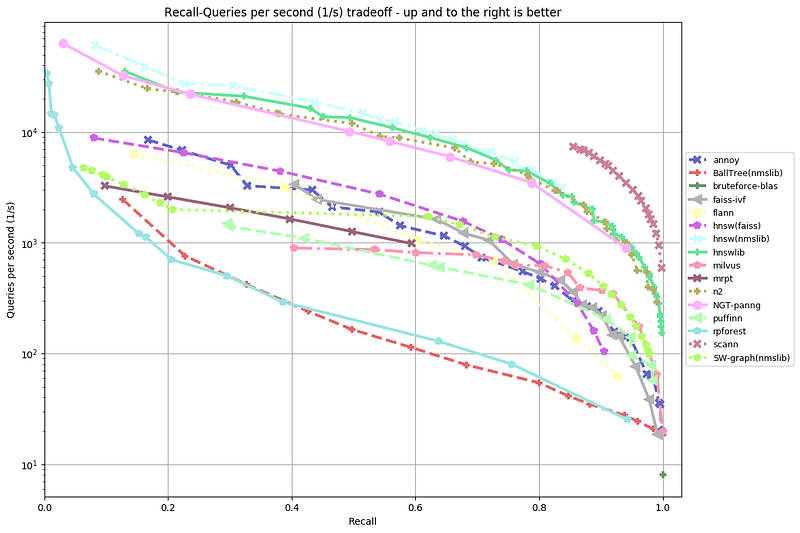
So , in this tutorial, we have built a brut-force and an approximate k-NN similarity search feature using different libraries and approaches. Also, reviewed different types of indexes used in approximate k-NN similarity.
The code can be tried out with Google Colab.
Sources:



