
Efficient Nets: Scaling of Conv networks
Because of scaling, neural networks took so many years to come forward despite all its maths already being present since the 90s. Back then, we didn’t understand properly how to make a neural network work for complex tasks. Since Batchnorm() was not invented until 2014, researchers struggled to train VGG16. Basically, we didn’t understand how to scale the networks to perform complex tasks. If you’ll look at the VGG16 architecture below image, you’ll observe scaling happening at three different levels: Depth, width, and resolution.
Depth scaling is the number of layers in a given network. Width scaling is the size of each Conv layer {112x112 or 56x56} and resolution is the depth of each Conv layer {112x112x128 (resolution =128)}. But, why do we need scaling? Why can’t we just add the same size and resolution layers and make predictions using that? There are two reasons why we don’t do that, firstly, using the same size layers will cause a huge jump in the number of parameters (more parameters means more memory requirements) and secondly, we want features to be read at different scales so that we can find more hidden patterns in the data stream(imagine the resolution of Conv layers as the resolution of a microscope). You can choose these numbers (scaling parameters) but the model’s performance won’t be optimized. Correct scaling is the key to a model’s success.
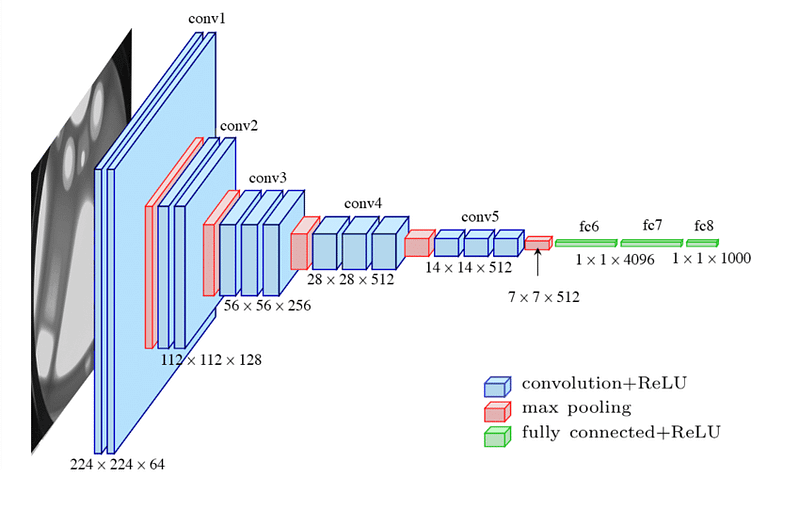
As of now, VGG16 is considered ancient and its scaling is very linear thus it fails in complex tasks. In recent times, Efficient Net has gained huge popularity because of its dynamic scaling. Efficient Net is considered to be the state of the art developed by google. It combines a compound scaling methodology to achieve a considerable improvement in accuracy and low computational complexity.
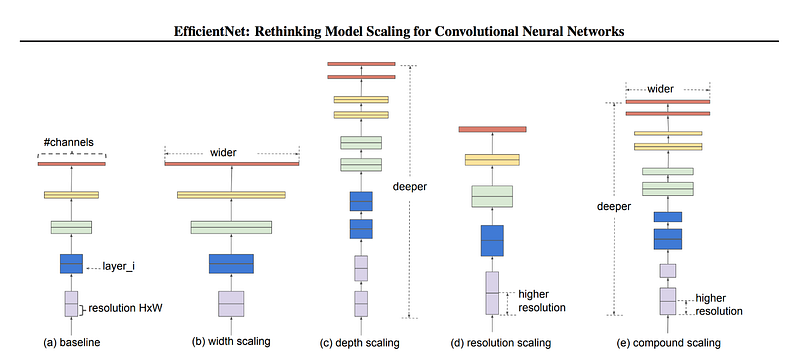
Compound scaling: The compound scaling method uses a compound coefficient φ to uniformly scale network width, depth, and resolution in a principled way:
depth: d = α ^φ
width: w = β ^φ
resolution: r = γ^ φ
s.t. α · β^ 2 · γ^ 2 ≈ 2
α ≥ 1, β ≥ 1, γ ≥ 1
Here α, β, γ are constants that can be determined by a small grid search. Intuitively, φ is a user-specified coefficient that controls how many more resources are available for model scaling, while α, β, γ specify how to assign these extra resources to network width, depth, and resolution, respectively. Notably, the FLOPS of a regular convolution op is proportional to d, w^2, r^ 2, i.e., doubling network depth will double FLOPS, but doubling network width or resolution will increase FLOPS by four times. Since convolution ops usually dominate the computation cost in ConvNets, scaling a ConvNet with equation 3 will approximately increase total FLOPS by (α · β 2 · γ 2) ^φ. In this paper, we constraint α · β ^2 · γ^ 2 ≈ 2 such that for any new φ, the total FLOPS will approximately increase by 2^φ.
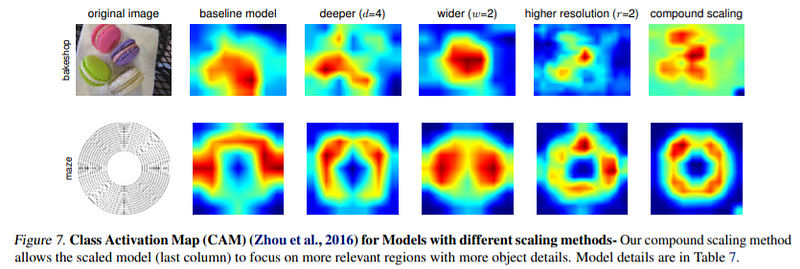
All we discussed above sounds good in theory, but how does it translate to actual performance. In DL, performance is often looked at through the value of loss or some other metric. A better way to understand networks' performance is to look at the class activation map, which basically tells us what a network finds salient or essential in a given image. You can see the improvement in performance due to compound scaling.
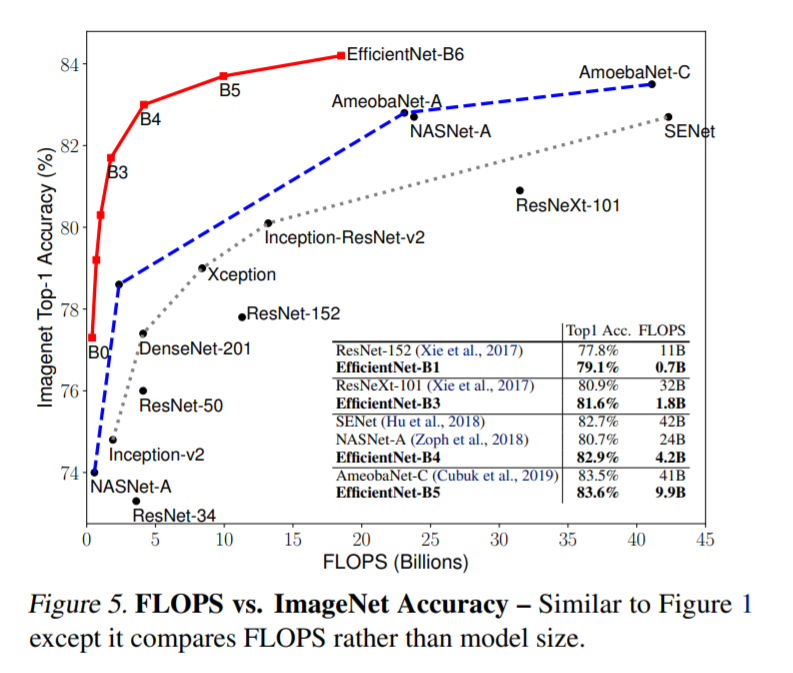
For the more nerdy people, here’s the graph of top-1% accuracy vs FLOPS (number of operations) for different state-of-the-art models. We can see that efficient Net achieves much higher performance for fewer parameters or FLOPS.
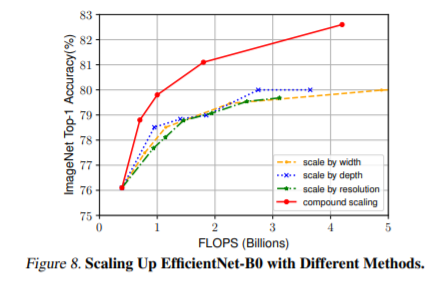
And also, in the graph for the effect of different scaling, we see similar results, huge improvement through compound scaling over traditional scaling. The idea behind Efficient Net is straightforward but a compelling one. Another good thing about Compound scaling is that it’s model agnostic (model-independent). As of writing this blog, Efficient Net B6 wide is the best model in the world for the Imagenet challenge (All the new models are benchmarked on this dataset only).
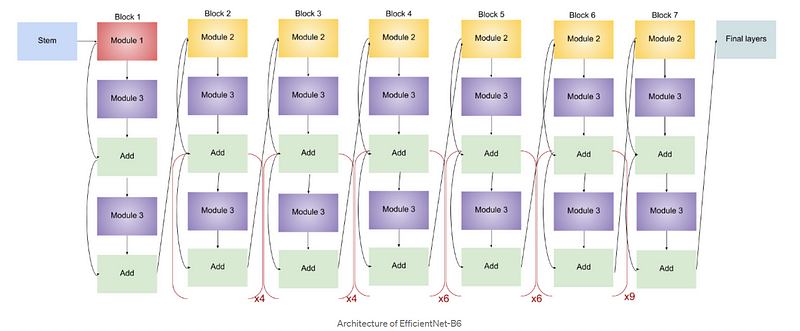
And if you are wondering what’s with the different Efficient net B1, B2…B6, architecture, they just have more layers than their previous version, thus a better ability to extract more deep features. The earlier versions of Efficient Net have similar architecture and lesser connections compared to B6 and B7. Going into the architecture detail is beyond the scope of this particular blog.
Thanks for giving your time, and if you think that this blog added something to your knowledge base, please consider following the AI guys Blog, and if you are interested to become a writer at AI Guys you can follow this link.




