
EDA and Feature Engg Series: Encoding
Exploratory Data Analysis and Feature Engineering Series: Encoding techniques with multiple approaches in practical use case considerations
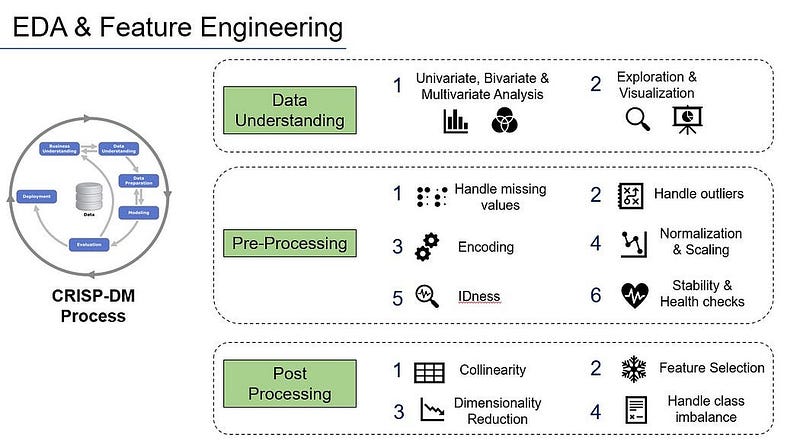
The CRISP-DM methodology in any Data Science program involves key stages around the “Data Understanding” and “Data Preparation” phases. We spend the majority of our time and effort during these stages. This series is in continuation with other methods that I have published.
Please refer here for the post around “handling missing values” and here for the post around “handling outliers”.
In this article, we will focus on encoding techniques. Feature Engineering is an extremely critical step in the Data Science process and encoding is very useful as part of the data pre-processing. Handling non-numeric data for use by machine learning algorithms is not something we can avoid and present its own set of challenges.

We will attempt to focus on the following:
· What is Encoding?
· Different types of Encoding techniques
· Consider a few of them such as One Hot Encoding, Label Encoding, Ordinal Encoding, Helmert Encoding, Binary Encoding
· Encoding overall approach — when to use what?
A) What is Encoding:
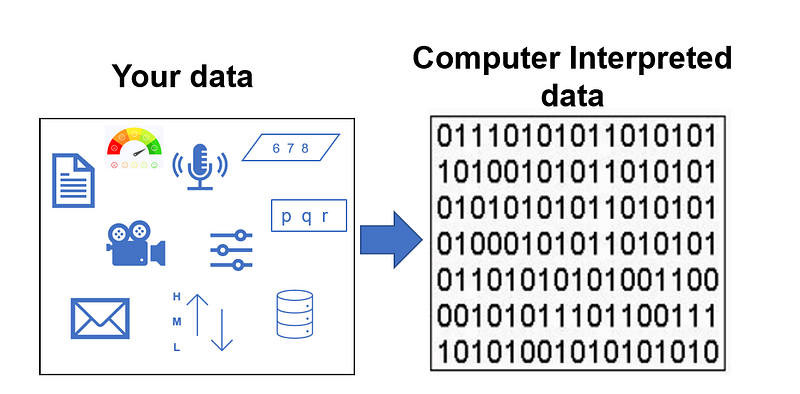
Encoding helps us convert different types of data such as nominal (e.g. Green, Yellow, Blue, Red, etc, or Dog, Cat, Cow, etc), ordinal (e.g. High, Medium, Low, etc) to computer/machine interpreted data formats (which is eventually 1 or 0 formats) that the machine understands. The machine learning algorithms operate on mathematical vectors with little context and therefore it is required to convert categorical variables to numeric format.
We will see various types of encoding techniques and how to use them.
B) Different Types of Encoding:
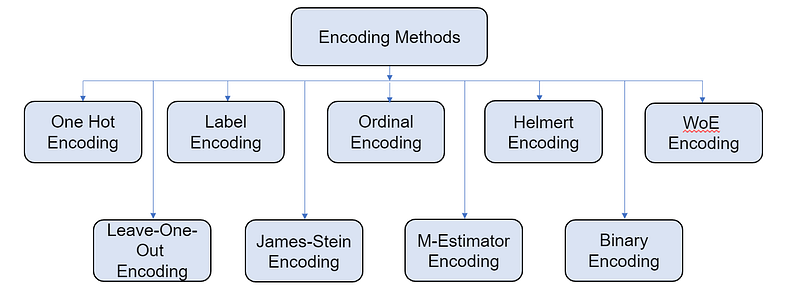
There are many different types of Encoding. I have attempted to illustrate some of the important types such as One Hot Encoding, Label Encoding, Ordinal Encoding, Helmert Encoding, WoE (Weight of Evidence) Encoding, Leave-One-Out Encoding, James-Stein Encoding, M-Estimator Encoding, Binary Encoding, etc.
We will try to pick five of these and understand them from illustrations with examples using python.
C) Example of a few Encoding techniques:
We will focus on five of them with an example to compare.
- One Hot Encoding:
One Hot Encoding is a very popular method. It is used to split each of the categories into an additional column. It increases dimensionality as part of encoding since it creates additional columns/attributes for various categories.
We have considered an example of servers, their respective chiller temperatures, and model type. The label is the target feature which is either 1 or 0. The goal is to predict chiller temperatures by formulating a machine learning predictive model.
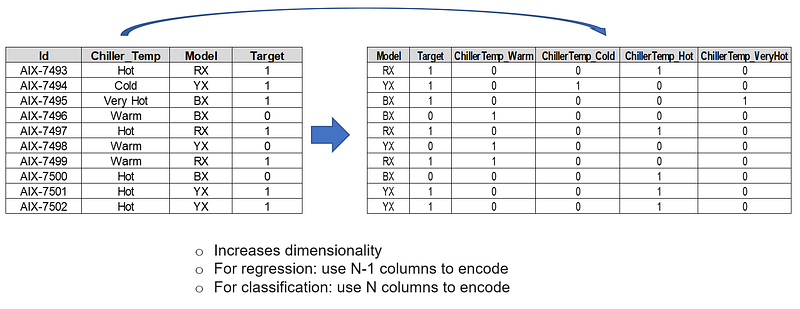
It creates N different columns each for a category and replaces one column with 1 rest of the columns are 0.
- For Regression, we use N-1 (drop the first or last column of One Hot Coded new feature) columns.
- For classification, the recommendation is to use all N columns without dropping any column as most of the tree-based algorithm builds a tree based on all available variables.
import pandas as pd
import numpy as np
from sklearn import preprocessing
from sklearn.preprocessing import OneHotEncoder
# Create sample data in the dataframe
my_data = {'Id':[7493,7494,7495,7496,7497,7498,7499,7500,7501,7502],
'Chiller_Temp':['Hot','Cold','Very Hot','Warm','Hot','Warm','Warm','Hot','Hot','Hot'],
'Model':['RX','YX','BX','BX','RX','YX','RX','BX','YX','YX'],
'Target':[1,1,1,0,1,0,1,0,1,1]}
df2 = pd.DataFrame(my_data)
df2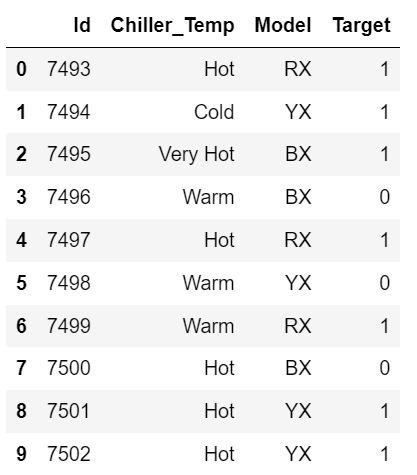
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore') # Creating instance of one-hot-encoder
ohet = ohe.fit_transform(df2.Chiller_Temp.values.reshape(-1,1)).toarray()
dfOneHot = pd.DataFrame(ohet, columns=["ChillerTemp_" + str(ohe.categories_[0][i])
for i in range(len(ohe.categories_[0]))])
dfh = pd.concat([df2, dfOneHot], axis=1)
dfh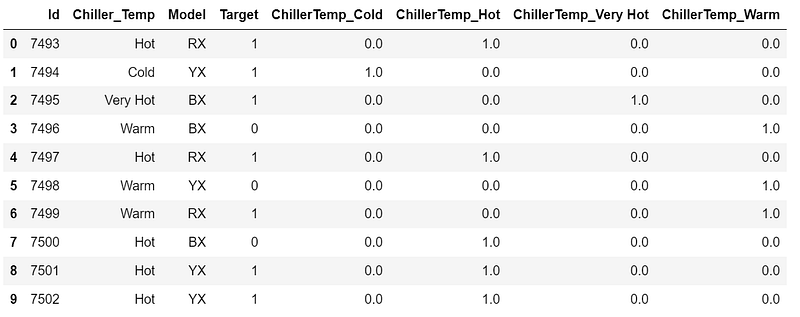
The linear regression has access to all of the features as it is being trained and hence examines the whole set of dummy variables altogether. This means that N-1 binary variables give complete information about the original categorical variable to the linear regression. This approach can be adopted for any machine learning algorithm that looks at all the features simultaneously during training — for example, support vector machines and neural networks as well as clustering algorithms.
2. Label Encoding:
It is used to transform categorical features into numerical features by assigning a numerical value to each of the categories. If we consider the same example of our Servers and their chiller temperature, we can do the following:
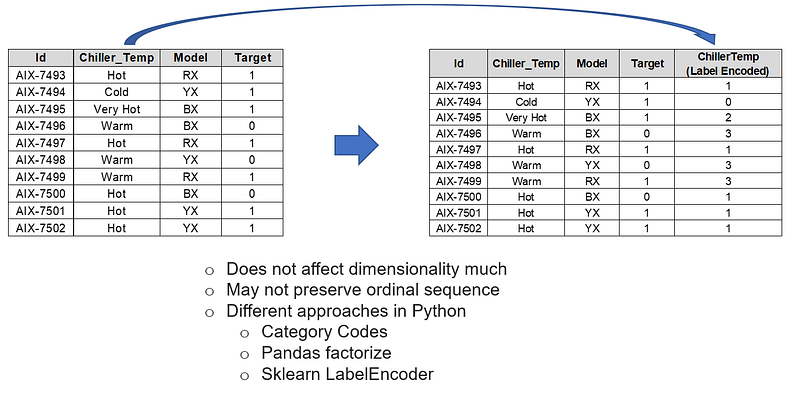
It will not affect dimensionality much as it does not create additional features for each category. In this example above, [Hot, Cold, Very Hot, Warm] will be encoded to [1, 0, 2, 3].
It can be used for ordinal variables as well, however, it does not mandate following the sequence. Therefore, it may not preserve the ordinal sequence.
There could be many examples and a few are illustrated below.
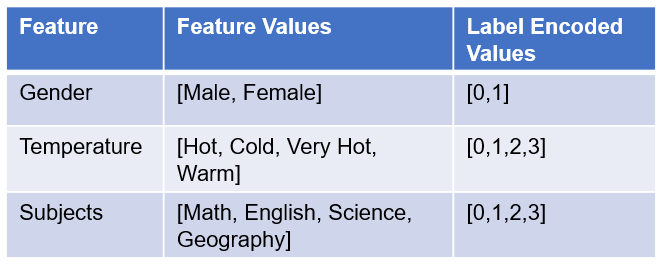
The code example is illustrated below.
import pandas as pd
import numpy as np
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
# Create sample data in the dataframe
my_data = {'Id':['AIX-7493','AIX-7494','AIX-7495','AIX-7496','AIX-7497','AIX-7498','AIX-7499','AIX-7500','AIX-7501','AIX-7502'],
'Chiller_Temp':['Hot','Cold','Very Hot','Warm','Hot','Warm','Warm','Hot','Hot','Hot'],
'Model':['RX','YX','BX','BX','RX','YX','RX','BX','YX','YX'],
'Target':[1,1,1,0,1,0,1,0,1,1]}
df = pd.DataFrame(my_data)
df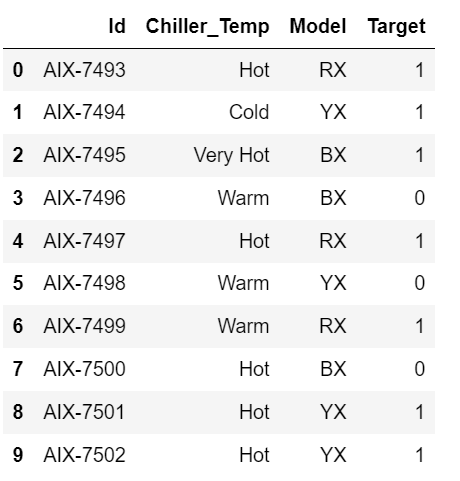
# Creating instance of labelencoder
labelencoder = LabelEncoder()
# Assigning numerical values and storing in another column
df['ChillerTempEncoded'] = labelencoder.fit_transform(df['Chiller_Temp'])
df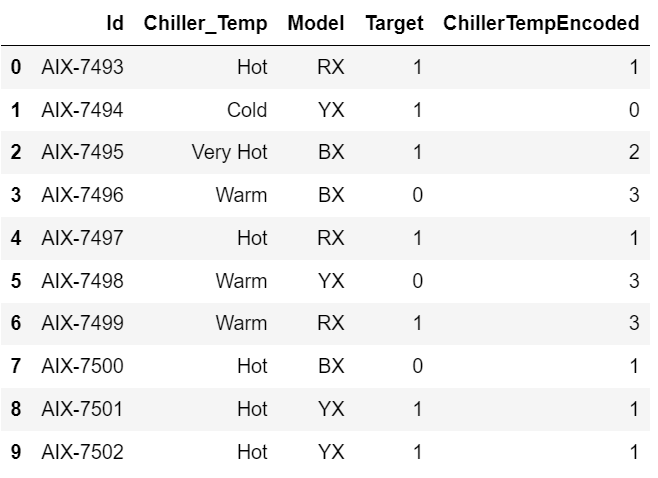
3. Ordinal Encoding:
It is used to transform categorical features into numerical features by assigning a numerical value to each of the categories. It preserves the ordinal sequence.
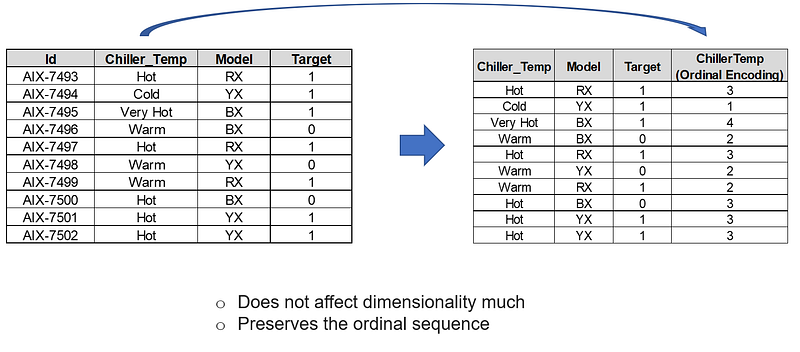
A few examples are illustrated below.
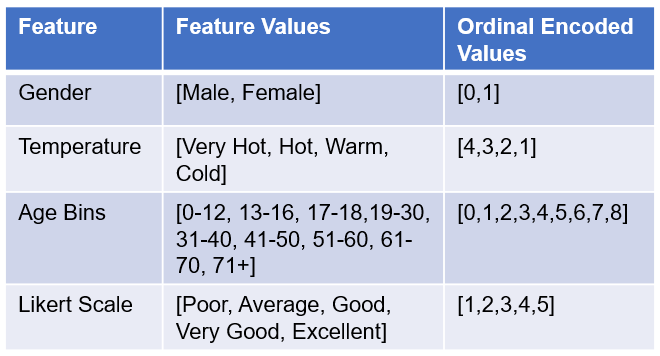
4. Helmert Encoding:
It increases dimensionality (like One Hot Encoding). We have taken the same example of servers with different level chiller temperatures.
In this technique, the mean of the dependent variable for a level is compared to the mean of the dependent variable over all previous levels.
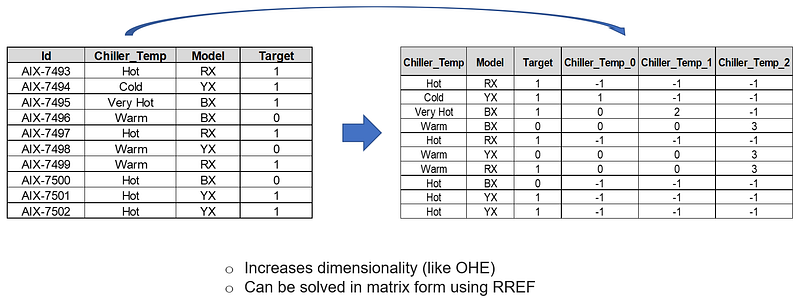
It can be solved in matrix form using RREF (Reduced Row-Echelon Form). A matrix is in RREF (reduced row-echelon form) if it satisfies the following: In each row, the left-most nonzero entry is 1 and the column that contains this 1 has all other entries equal to 0. This 1 is called a leading 1. You can check on RREF here.
This method is typically useful when the levels of categorical feature (e.g. Chiller_Temp in the above example) are ordered in a meaningful way.
Please refer here for sklearn usage considering category_encoders.
classcategory_encoders.helmert.HelmertEncoder(verbose=0, cols=None, mapping=None, drop_invariant=False, return_df=True, handle_unknown='value', handle_missing='value')5. Binary Encoding:
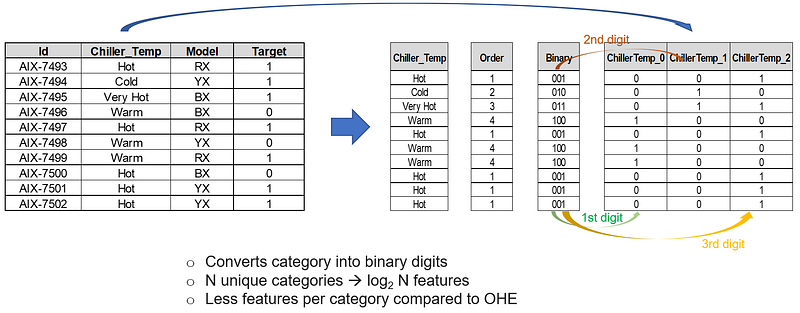
The binary encoding technique is a combination of One Hot encoding and hash encoding. When to use — when there is a high number of categories, it would be a good idea to use this method. It acts as a kind of dimensionality reduction as well since it uses fewer features compared to One Hot encoding.
For example — if there are 40–50 models in the server category and we would like to encode them, then it will be a good idea to use binary encoding. Another example — in the airline analysis, we are trying to explore and analyze source to destination flights and operations effectiveness from a specific source airport. Since the number of destinations would be lots of cities, we can use binary encoding instead of one hot encoding to minimize creating too many additional features.
D) Encoding overall approach — when to use what?
Here is a summary of encoding techniques based on certain situations.
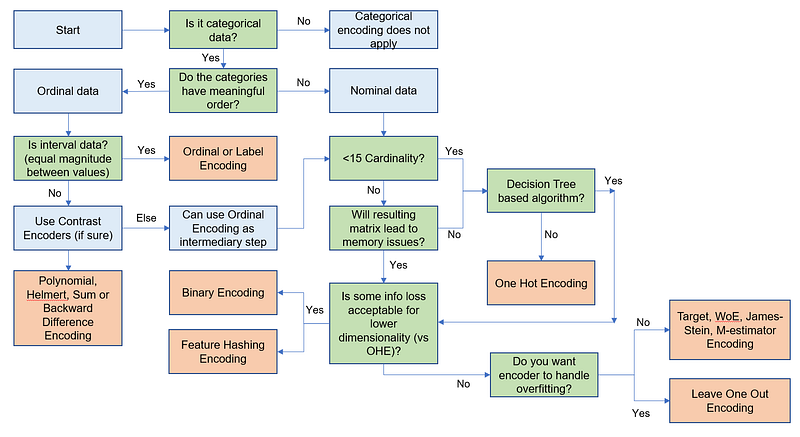
That’s all for now. I will come back with more techniques as part of the “EDA and Feature Engineering” series. Please feel free to provide your valuable feedback or comments and clap if you like and if there is some value for you.
The python implementation file can be referred to here.
Disclaimer: The postings here are a personal point of view from my experiences, analysis, thoughts, and readings from various sources.





