
Easy Distributed Scikit-Learn with Ray

TL;DR: Scale your scikit-learn applications to a cluster with Ray’s implementation of joblib’s backend.
Scikit-learn is a popular open-source library for machine learning. It features various clustering, classification, regression and model selection algorithms including k-means, support vector machines (SVMs), gradient boosting and random forests.
Distributed Scikit-Learn with Ray
Scikit-learn parallelizes training on a single node using the joblib parallel backends. Joblib instantiates jobs that run on multiple CPU cores. The parallelism of these jobs is limited by the number of CPU cores available on that node. The current implementation of joblib is optimized for a single node, but why not go further and distribute it on multiple nodes?
Running distributed applications on multiple nodes introduces a host of new complexities like scheduling tasks across multiple machines, transferring data efficiently, and recovering from machine failures. Ray handles all of these details while keeping things simple.
Ray is a fast and simple framework for building and running distributed applications. Ray also provides many libraries for accelerating machine learning workloads. If your scikit-learn code takes too long to run and has a high degree of parallelism, using the Ray joblib backend could help you to seamlessly speed up your code from your laptop to a remote cluster by adding four lines of code that register and specify the Ray backend.
How to Run Scikit-Learn with Ray
After you set up your Ray cluster you have to make the following changes to your code:
A More Complete Example
Here’s a more complete example that does hyperparameter tuning of an SVM with cross-validation using random search.
The lines that were added to the original code are #2,#7,#8, and #21. Note that so far, this code will run on multiple cores but only on a single node, because we haven’t specified how to connect to a Ray cluster yet.
To run it on a Ray cluster add ray.init(address=”auto”) or ray.init(address=”<address:port>”) before calling
with parallel_backend(“ray”) as shown in line #20.
More details on how to run scikit-learn with Ray are available here.
Experimental Results
To evaluate the benefits of distributing scikit-learn with Ray, we run hyperparameter tuning with random and grid search on SVM classifiers and random forests using the scikit-learn digits dataset. The code to reproduce the results is available here. We start with a single m5.8xlarge node with 32 cores on AWS. Then we increase the number of nodes to five and then to ten. We compare the Ray backend to the Loky, Multiprocessing, and Dask backends.
The following figure shows the performance comparison on a random forest benchmark as well as two SVM hyperparameter tuning benchmarks. For random forests, we use 45,000 trees. For hyperparameter tuning, we use 1,500 configurations for random search and 20,000 for grid search. The performance in terms of execution time is normalized to the performance of the scikit-learn default Loky backend (in the plots, higher is better).
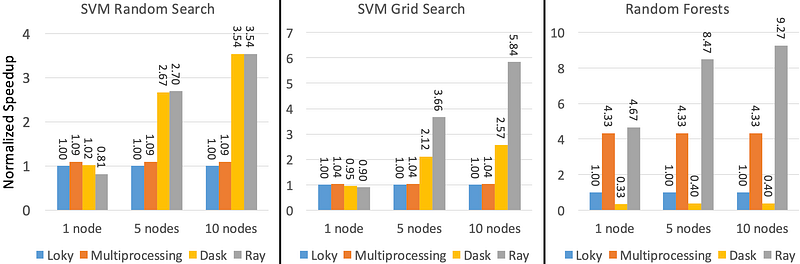
On multiple nodes, Ray outperforms the other backends. Ray performs significantly better in the random forest benchmark. Ray shines in this workload due to the large number of tree estimators used, which results in 45,000 tasks being submitted (compared to 1,500 tasks in hyperparameter tuning with random search and 20,000 in grid search). Ray’s high-throughput decentralized scheduler along with its use of shared memory allow Ray to scale this workload efficiently to multiple nodes. The performance improvement as we add more nodes increases but is bottlenecked mainly by the serial part of the program (Amdahl’s law). Adding more hyperparameters to tune can further improve the parallelism and result in improved scalability.
Conclusion
In this blog post, we showed how you can scale your scikit-learn applications to a cluster with Ray’s implementation of joblib’s backend, by adding four lines of code.
This is only one of many powerful libraries built to scale using Ray, including Tune, a scalable hyperparameter tuning library and RLlib, a scalable reinforcement learning library. If you have any questions, feedback, or suggestions, please join our community through Discourse or Slack. If you would like to see how Ray is being used throughout industry, consider joining us at Ray Summit.




