
Decoding the Large Language Models
Discovering LLM Structures: Decoder-only, Encoder-only, or Decoder-Encoder
Explore Transformer models’ rise in NLP, from their foundational architecture to their prowess in tasks like summarization and translation.
Language models have, for decades, been the linchpin in the evolution of Natural Language Processing (NLP). They have enabled computers to mimic human-like text comprehension, ushering in a paradigm shift in how machines understand and generate language. This article delves deep into the most revolutionary among them: the Transformer models, exploring their architecture and their impact on diverse NLP tasks.
Before starting, if you want to learn more about generative AI, I suggest checking out my other posts using the below list:
Now, let’s get started!
Transformers: Revolutionizing the Realm of NLP
In 2017, an academic paper titled “Attention Is All You Need,” authored by Vaswani and team, made waves across the AI community. What was so special about it? It introduced the world to the Transformer architecture, a model that proposed a novel self-attention mechanism. This mechanism is adept at weighting input tokens in a sequence differently, depending on the context, enabling it to “zoom into” different input parts for various tasks.
The original Transformer architecture was a dual-faceted beast comprising an encoder and a decoder. However, in the vast landscape of NLP, innovators found value in either using both or just one of these components, depending on the task at hand:
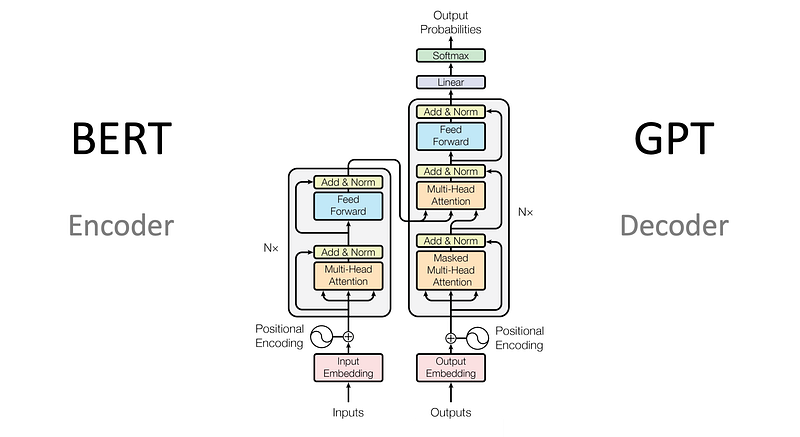
- Encoder-Only Transformers (like BERT): This variant uses just the encoder part of the architecture. It’s designed to process a sequence of tokens and produce a dense representation for each token in the sequence. Models like BERT, trained in a bidirectional manner, aim to predict words that are intentionally masked in a sentence. The success of this approach has led to BERT’s foundational role in tasks like text classification, named entity recognition, and many others.
- Decoder-Only Transformers (like GPT): This model is the flip side of the coin, relying solely on the decoder component. Designed primarily for text generation, models like GPT take a prompt and weave extensive, coherent narratives or responses. They’re trained unidirectionally, predicting the next token in a sequence based on prior tokens.
Over time, the research community’s voracious appetite for innovation led to models with astonishingly high parameter counts. GPT-3, for instance, boasts 175 billion parameters! Such large-scale models stretch the limits of machine-generated text, producing outputs often indistinguishable from human-written content.
A Deep Dive: Encoders, Decoders, and Their Directions
The beauty of the Transformer architecture lies in its versatility. Its components — the encoder and the decoder — are both stacks of layers that process and produce sequences. Let’s delve into how specific models leverage these components:
Encoder-Decoder (like the original Transformer or models like T5):
- Machine Translation: Translate a sentence from a source language to a target language. The encoder processes the source, and the decoder generates the translation.
- Text Summarization: Condense a longer piece of text into a shorter summary.
- Image Captioning: Given an image, produce a textual description or caption. The encoder processes the image, and the decoder generates the caption.
Encoder-Only and Decoder-Only:
Encoder-Only (like BERT):
- Filling in Missing Words: Given a sentence with some words masked out, predict the missing words.
- Sentence or Document Classification: Determine the category or sentiment of a sentence or document.
- Named Entity Recognition: In a sentence, identify and categorize entities (e.g., persons, organizations).
- Question Answering: Given a passage and a question, find the answer within the passage.
Decoder-Only (like GPT):
- Text Generation: Produce coherent and contextually relevant text based on a prompt.
- Conditional Text Generation: Given some conditions or constraints, generate text that adheres to them.
- Summarization (with fine-tuning): Create a concise summary of a longer text.
- Translation (with fine-tuning): Translate text from one language to another.
Bidirectional vs. Unidirectional:
In the above, some Bidirectional or Unidirectional are mentioned; let’s see what those are and how we can distinguish them.
- Bidirectional: The model processes input data (like a sentence) from both directions, from start to end and from end to end. When BERT is trained, it’s done in a bidirectional manner. This is achieved by masking (hiding) some words in a sentence and asking the model to predict them based on the surrounding context. Since the model can use words before and after the masked word to make its prediction, it’s considered bidirectional.
- Unidirectional: This means the model processes data in one direction only. For example, when GPT is trained to predict the next word in a sentence, it only looks at the previous words, not the ones that come after. It’s like reading a book from the first page to the last without looking ahead.
Conclusions
The Transformer architecture and its offshoots have reshaped the NLP terrain. From simple text classification tasks to intricate ones like translation, they’ve proven their mettle time and again. As research progresses, the AI community waits with bated breath for the next big breakthrough in this domain. One thing is certain: Transformers have set the stage for an exciting future in NLP.
Thank you for reading my post, and I hope it was useful for you. If you enjoyed the article and would like to show your support, please consider taking the following actions: 👏 Give the story a round of applause (clap) to help it gain visibility. 📖 Follow me on Medium to access more of the content on my profile. Follow Now 🔔 Subscribe to the newsletter to not miss my latest posts: Subscribe Now or become a referred Medium member. 🛎 Connect with me on LinkedIn for updates.





