Designing Low Latency Segmentation Platform Using Upstash Kafka and Source MongoDB Connector
Introduction
- Segmentation platform plays a crucial role in understanding and categorizing customers, products, and other relevant data.
- Segmentation involves dividing a larger group into smaller, more homogeneous subgroups based on certain criteria.
- Here are a few examples of segmentation platforms in different domains: For example — Customer segmentation to identify and categorize customers based on various factors such as demographics, purchasing behavior, order history, and preferences. This enables personalized marketing strategies, targeted promotions, and a more customized shopping experience.
Table of Contents
- Understanding Requirements
- Basic Architecture
- Architectural Components
- Design Challenges
- Proposed Solutions
- Closing Notes
1. Understanding Requirements
Designing a low-latency segmentation platform for customer segments in e-commerce introduces specific challenges related to real-time processing, user experience, and the dynamic nature of customer behavior. Here are some challenges you might encounter in this context:
1. Large and Dynamic Datasets:
- E-commerce platforms deal with large and constantly changing datasets, including customer profiles, product catalogs, and transaction histories.
- Managing and processing these vast datasets in real-time while maintaining low latency is a significant challenge.
2. Scalability
- Designing for scalability is essential to handle varying workloads. Ensuring that the system can scale horizontally by adding more processing units without sacrificing latency requires careful architecture planning.
3. Asynchronous Processing:
- Leveraging asynchronous processing can help decouple components and improve overall system responsiveness. However, managing asynchronous communication without introducing complexities or delays requires careful design.
4. Data Flow and Pipelines:
- Designing an efficient data flow and processing pipeline is crucial for low-latency systems.
- Minimizing the time data spends in transit between components and optimizing the sequence of processing steps can significantly impact overall latency.
5. Microservices Architecture:
- Implementing a microservices architecture can enhance scalability and flexibility. However, ensuring seamless communication between microservices without introducing latency can be challenging.
- Designing efficient APIs and managing inter-service communication is critical.
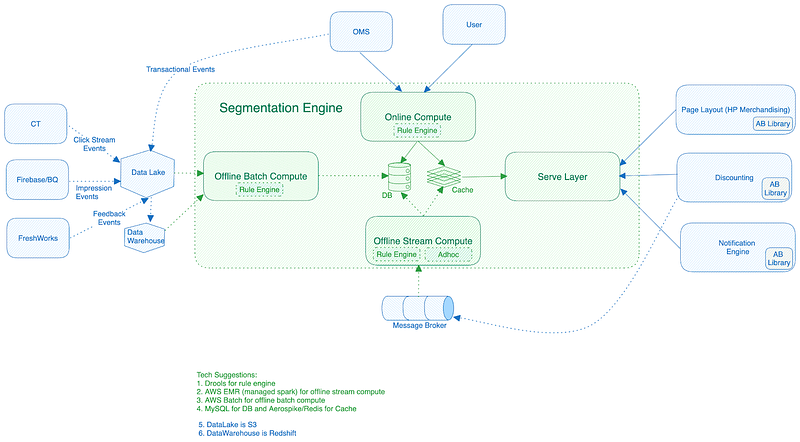
2. Basic Architecture
The Segmentation Platform consists of three major subsystems:
1. Compute Service(Offline Batch Compute/Online Compute)
- The primary goal of the compute service is to extract user segments from the raw data obtained from the data lake.
- The creation of segments is facilitated by Spark Jobs. Whenever someone from any team initiates the creation of a segment, a Spark job is triggered to fetch data from the organization’s data lake.
- Once the data is retrieved, cleaned, and validated through the Spark job, the next step involves the Spark job reaching out to the serving sub-system.
2. Ingestion Service
- The ingestion service is responsible for transferring the calculated segment from the compute service to the segmentation service.
- Additionally, it manages the inclusion and exclusion of existing users within their respective segments.
3. Segment Service(Serve Layer)
- The segmentation service is crucial in providing user segments based on specific requirements for user service or discount service.
- The serving of segments could be supported by a suite of Java/Go services. These services can utilize Aerospike as the primary storage layer for both persistence and caching.
- The decision to opt for Aerospike as a NoSQL store was influenced by its horizontal scalability and its capability to meet SLAs.
3. Architectural Components
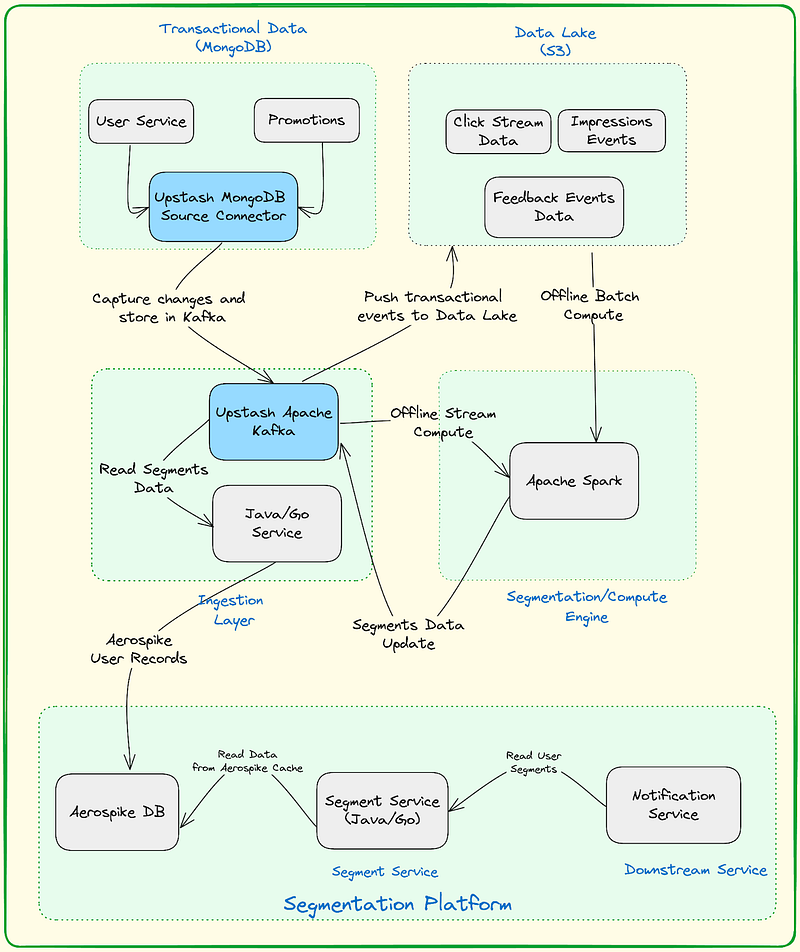
1. Data Lake — S3
- S3 is a widely adopted and versatile option for serving as a data lake. Its scalable and durable object storage capabilities make it suitable for efficiently storing and managing large volumes of diverse data types.
- By utilizing S3 as a data lake, organizations can benefit from its robust features for data storage, retrieval, and management, making it a popular choice in various data-centric applications and architectures.
2. Transactional Database MongoDB
- MongoDB’s document-oriented model is beneficial for transactional use cases as it allows you to store complex data structures in a format similar to JSON. This flexibility is particularly useful for applications where the data structure might evolve over time.
3. Upstash Kafka Cluster
- We can stream the traffic (click) events from our web application to Upstash Kafka then we can store them in the data lake for further processing.
- Upstash Kafka is the first Serverless Kafka offering. With a pay-per-request model, we can have a fully managed Kafka cluster without paying hundreds of dollars. With the free tier, we can create a Kafka cluster in seconds and without entering our credit card. The Upstash team takes care of availability, maintenance, scaling, upgrades, and all the other tedious stuff while you focus on your app.
4. Upstash MongoDB Source Connector
- A MongoDB Source Connector is a component used in data integration and streaming platforms, such as Apache Kafka Connect, to connect to a MongoDB database and capture changes or events in real time.
- The connector facilitates the movement of data from MongoDB to another system or platform, allowing for seamless data integration and analytics.
5. Apache Spark
- Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
- By integrating Upstash Kafka with Apache Spark which is provided out of the box by Upstash, we will stream the traffic (click) events from our web application to Upstash Kafka then we will analyze it on real-time.
- Apache Spark will be responsible for processing updates to user segments. These updates will then be written to Upstash Kafka before being propagated to update the Aerospike database.
4. Design Challenges
The growing adoption and usage of the segmentation engine could introduce certain challenges for the system.
- Write QPS Bottleneck: The creation of more and larger segments may lead to a bottleneck in write queries per second (QPS), resulting in prolonged wait times for segment creation.
- Lower Latency Request: Achieving very low latency is crucial for sending certain communications, especially when determining whether a user belongs to a specific segment.
1. Read Latency
- Moreover, as the platform continues to evolve, even with the required <50ms latency for reads, there is an anticipation that this speed might not be adequate for certain services and their future use cases.
- For example, the notification service is expected to require rapid checks to determine user segment membership before sending out communications. Introducing increased latency for each communication request is anticipated to be unacceptable in the future.
2. Managing Kafka Infrastructure
- Handling millions of events per minute from transactional sources can indeed pose challenges when using Kafka infrastructure, and the effective management of such a high throughput requires careful consideration of various factors.
- Regular performance testing and optimization are key to maintaining a high-throughput Kafka infrastructure.
3. MongoDB Change Data Capture
- Aggregating events from web applications, particularly when they are stored in traditional transactional databases like MongoDB, and then pushing them to a data lake can indeed involve some effort.
- Utilize change data capture mechanisms provided by MongoDB or implement a custom solution to capture changes in the database.
5. Proposed Solutions
1. Distributed Cache Aerospike to improve read latency
- Aerospike will contain segments of a user where the user ID serves as the primary key for accessing user segments.
- Additionally, we could also implement secondary indexes on segment IDs, streamlining the retrieval of segment users and eliminating the necessity of storing segment users separately
- Furthermore, the design aims to meet latency requirements, with the potential for it to function as a cache, potentially replacing the need for Redis.
- Replacing the current Aerospike with Upstash Redis would necessitate managing two sets of data: segment users and user segments.
2. Serverless Upstash Kafka to manage Kafka Infrastructure
- With Upstash Kafka, you get a completely managed service. This implies that Upstash handles all the technical tasks, such as server provisioning, scaling, and maintenance involved in running Kafka clusters.
- This takes away the need for you to worry about things like setting up the infrastructure, getting everything to work correctly, and maintaining it over time.
- This allows you to focus on leveraging Kafka for your unique requirements and objectives. Without the burden of managing infrastructure, you can now channel your energy into enhancing the overall quality of your application, particularly in a rapidly evolving development environment.
- Price scales to zero: A true serverless offering shouldn’t charge you if you’re not actively using it. Price-per-request is our most outstanding feature. We’ve been designing our products and infrastructure to fit this pricing model from day one. This requires minimizing fixed costs, which is quite difficult for a beast like Kafka.
- No operational burden for the user: The user creates the Kafka topic and starts using it. High availability, scalability, upgrades, backups… it’s all our responsibility.
- Connectionless: Serverless functions do not hold state. So you should be able to access your data with a stateless connection. Our Kafka offering supports the Kafka TCP protocol so all Kafka clients will work with Upstash. We also have a built-in REST API to enable connectionless environments like AWS Lambda, and Cloudflare Workers.
3. MongoDB Change Data Capture Using MongoDB Source Connector
- Kafka Connect is a tool for streaming data between Apache Kafka and other systems without writing a single line of code. Via Kafka Sink Connectors, you can export your data into any other storage. Via Kafka Source Connectors, you can pull data to your Kafka topics from other systems.
- Kafka Connectors can be self-hosted but it requires you to set up and maintain extra processes/machines. Upstash provides hosted versions of connectors for your Kafka cluster. This will get the burden of maintaining an extra system from you and also it will be more performant since it will be close to your cluster.
6. Closing Notes
In this blog post, we’ve explored the design principles of a low-latency segmentation platform leveraging cutting-edge technologies provided by Upstash. This infrastructure is engineered to scale seamlessly, accommodating millions of users and handling terabytes of data stored in a data lake.





