
Desenvolvendo projetos de IA (semana 2)

A primeira semana do novo curso de Andrew Ng (AI for everyone) nos fez entender o que hoje é a Inteligência Artificial (IA), suas possibilidades, seus limites e como ela pode ser implementada na forma de modelos de Machine Learning, e em particular de Deep Learning. Com este conhecimento geral da IA, podemos agora aprender como desenvolver um projeto de IA nesta segunda semana do curso.
Este artigo faz parte da série “Deep Learning in Practice” (para ler também as versões em Francês e Inglês).
Lista de artigos “IA para todos”
- IA para todos (semana 1)
- Desenvolvendo projetos de IA (semana 2)
- Construindo IA em sua empresa (semana 3)
- IA e Sociedade (semana 4)
Introdução
Agora que você tem um conhecimento geral de IA graças a semana 1, você pode iniciar seu primeiro projeto de IA (starting an AI project)!
Seja um projeto com amigos, seja um negócio, para selecionar um projeto de IA (selecting an AI project) — ou seja, um projeto onde o uso de IA trazer valor — você precisa estabelecer a sequência de fluxo de trabalho (workflow), a coleta de dados e a organização da equipe IA.

Andrew Ng usa o exemplo de reconhecimento de fala do Amazon Alexa para explicar esses 3 passos.

Crédito: todas as imagens neste artigo vêm do MOOC de Andrew Ng, AI for everyone.
Dicas para um formador
O conteúdo desta semana 2 contém todos os elementos essenciais para o desenvolvimento de um projeto de IA (pequeno ou grande) e a compreensão de como todos as funções de trabalho serão afetadas pela IA.
O formador deve apresentar o conteúdo do curso de uma forma Top-Down, começando com exemplos mostrando os usos da IA em diferentes setores (comércio, indústria, agricultura, etc.) e diferentes atividades (vendas, marketing, recursos humanos, etc.). De fato, descobrindo o impacto da IA nas atividades em seu setor, o participante terá um interesse pessoal em entender a IA e, portanto, uma motivação adicional.
Além disso, o curso deve basear-se em exemplos simples e compreensíveis para todos.
Pontos-chave da semana 2
. Como o sua atividade será alterado pela IA . Como decidir usar a IA em um projeto? (etapa 1) . Como decidir usar a IA em um projeto? (etapa 2) . Realizar um projeto de IA internamente ou terceirizá-lo? . Fluxo de trabalho de um projeto de Machine Learning . Fluxo de trabalho de um projeto de Ciência de Dados . Trabalhando com uma equipe de IA . As ferramentas da equipe de IA . Sem Big Data, nenhum projeto de IA? Errado!
Como o sua atividade será alterado pela IA
Com a revolução digital, todas as atividades foram digitalizadas e/ou geram dados digitais. Isso significa que o uso de ferramentas de Ciência de Dados (Data Science) e IA pode beneficiá-lo/la, aplicando-se às diferentes atividades do seu trabalho.
Vejamos os exemplos dados por Andrew Ng:
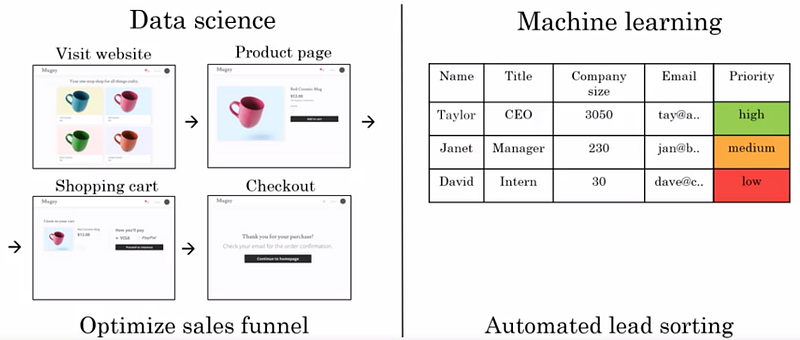
- Aumento das vendas: se você trabalha no campo comercial, sabe que clientes em potencial (leads) com um perfil diferente são sensíveis a diferentes produtos. Um modelo ML pode ajudá-lo a priorizar clientes (na saída B) com base em seus perfis (na entrada A) para um determinado produto.
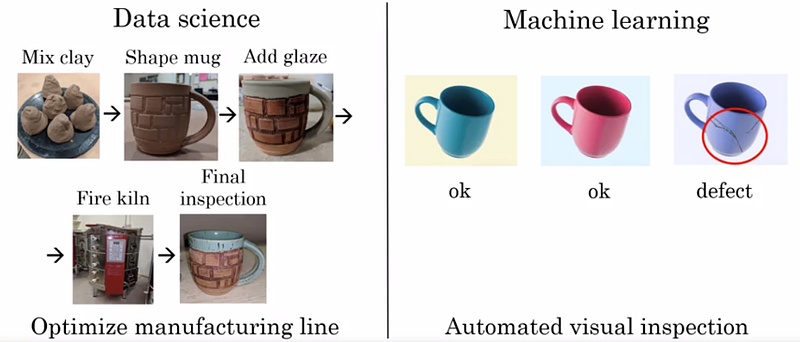
- Detecção de defeitos: no final de uma linha de fabricação de produtos, é possível instalar uma câmera cujas fotos serão visualmente inspecionadas por um modelo ML, a fim de classificar os produtos em uma das duas categorias “sem defeito“ou” com defeito“.
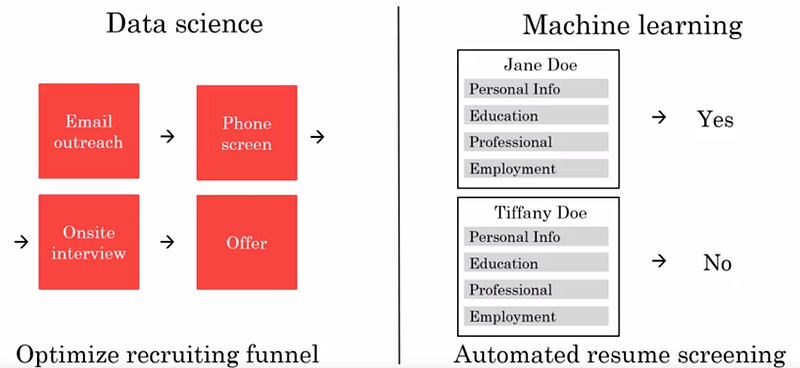
- Assistência ao recrutamento: para cada atividade, um modelo de ML pode ser treinado com os dados de resumos (entrada A) para detectar aqueles que correspondem à atividade (saída B: sim/não)
- Recomendação de produto: se você trabalha em marketing, você sabe que os sites de comércio eletrônico aumentam suas vendas sabendo como oferecer a seus clientes os produtos que mais lhes correspondem. O software por trás dessas recomendações é, na maioria das vezes, um modelo de ML que foi direcionado para prever o produto ou produtos (saída B) que um cliente com um determinado perfil (entrada A) preferirá.

- Agricultura de precisão: ao treinar um modelo de ML para reconhecer ervas daninhas (saída B) das fotos (entrada A), é possível livrar-se delas atacando-as em vez de pulverizar toda a plantação com um produto químico. É melhor para a produção agrícola, para a saúde do consumidor e para o meio ambiente.

Como decidir usar a IA em um projeto? (etapa 1)
Seja uma atividade existente ou o lançamento de um novo projeto, como você decide usar a IA? De fato, vimos na semana 1 que os modelos de IA não podem (pelo menos hoje) substituir todos os processos humanos e de negócios.
Para responder a essa questão, é sempre melhor organizar uma equipe multifuncional com a equipe de IA e a equipe de domínio, ou seja, a equipe que tem o conhecimento do campo e da profissão na qual queremos usar a IA: os projetos a serem selecionados são aqueles que são viáveis com IA (viabilidade) e que criam valor/redução de custos (valorização).
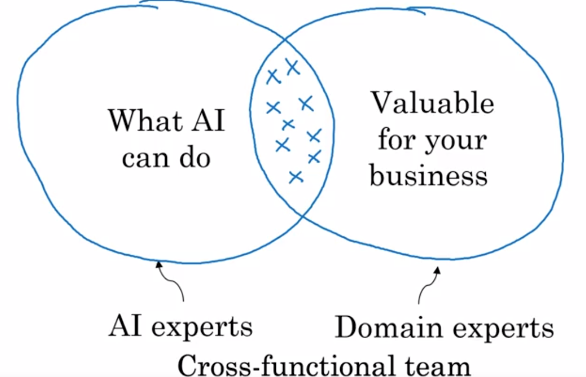
A ferramenta de seleção de projetos (framework) de Andrew Ng para esse “brainstorming” é a seguinte (nota: no parágrafo seguinte, Andrew Ng oferece um segundo “framework” para analisar melhor a viabilidade e o valor de um projeto de IA pré-selecionado):
- automação de processos/tarefas em vez de atividades: uma atividade é de fato composto de múltiplas atividades e como a IA só pode automatizar um único processo, é necessário dividir cada atividade em processos unitários para decidir para cada um usar a IA ou não.
- seleção de atividades com maior impacto nos negócios da empresa: se no início do uso da IA em uma empresa, é preferível escolher um projeto com menor impacto em seus negócios (no início, a ideia é experimentar para ganhar experiência), uma vez que as equipes estejam prontas para usar a IA, é preferível usá-la em que ela terá o maior impacto no negócio de a empresa.
- seleção das atividades mais difíceis/dolorosas do negócio da empresa: além do ponto anterior, uma vez que as equipes estejam prontas para usar a IA, é preferível usá-la em que as atividades do negócio da empresa são as mais difíceis/dolorosas (algumas podem ser automatizadas pela IA).

Como decidir usar a IA em um projeto? (etapa 2)
O “framework” da etapa 1 permite pré-selecionar um projeto no qual usar a IA. No entanto, ainda é necessário analisar com maior profundidade a sua viabilidade técnica pela equipe de IA (diligência técnica) e seu valor potencial pela equipe de domínio (diligência empresarial) antes de iniciá-lo.
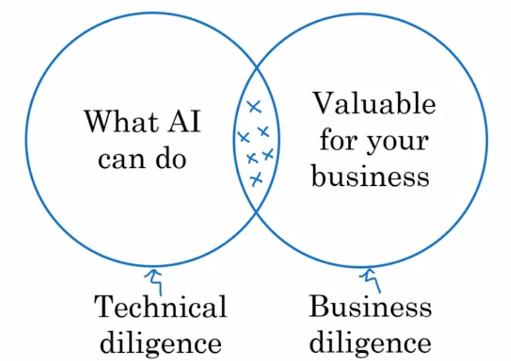
Diligência técnica
- De acordo com o estado da arte em IA, é possível atingir o nível de desempenho exigido pela equipe de domínio?
- Se sim, quantos dados de treinamento são necessários (e é possível coletá-los)?
- Quanto tempo e pessoas estarão envolvidas na criação, treinamento e implantação do modelo de IA?
Diligência empresarial
- Que redução de custos o modelo de IA pode induzir?
- Que aumento na receita o modelo de IA pode trazer?
- O modelo de IA pode gerar um novo produto e/ou um novo negócio?
Ética
A semana 4 do curso será dedicada à ética, porque também deve ser um critério de decisão para o lançamento de um projeto de IA.

Realizar um projeto de IA internamente ou terceirizá-lo?
Antes de contratar especialistas em IA para construir uma equipe interna, muitas vezes é melhor terceirizar o projeto para ganhar experiência em primeira mão. Além disso, é importante manter-se atualizado sobre o estado da arte em IA, de modo a não reconstruir o que já existe, especialmente em seu setor: use/compre modelos de IA padrão em seu setor e desenvolva-se somente aqueles que não existem e/ou que lhe trazem um valor diferenciador.

Fluxo de trabalho de um projeto de Machine Learning
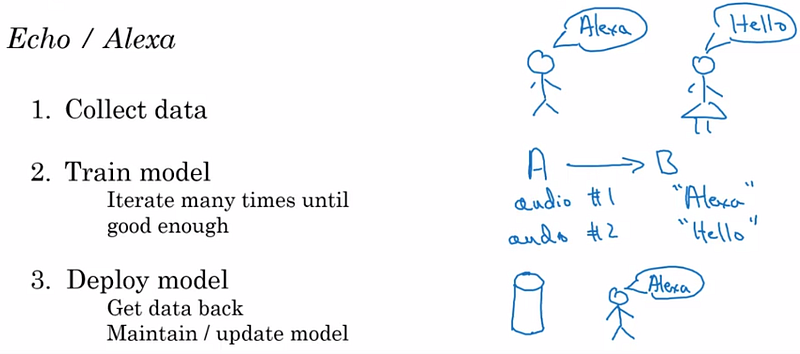
Todo projeto de Machine Learning começa com a coleta de dados (etapa 1) que será necessária para treinar o modelo (etapa 2).
No exemplo de Andrew Ng, é para gravar várias pessoas pronunciando as palavras “Hello” e “Alexa”. Os arquivos de áudio gravados representam as entradas A do nosso modelo de ML e seu conteúdo (“Hello”, “Alexa”), os alvos B. Para que nosso modelo de ML atinja um bom desempenho, precisamos não apenas de vários dados de treinamento (dataset (A, B)), mas também várias iterações de treinamento para refinar o valor dos parâmetros do modelo.
Em seguida, teremos que implantar o modelo (etapa 3), ou seja, implementar o modelo de ML como software nas caixas de som do Amazon Alexa e enviá-las para um pequeno grupo de usuários que gerarão novos dados ao usá-las. Por exemplo, se esse grupo contiver pessoas com sotaque diferente das que geraram o primeiro dataset de treinamento, os novos dados serão diferentes, o que permitirá de treinar novamente o modelo e/ou modificar sua arquitetura. Este ciclo de atualização do modelo de ML é essencial para melhorar seu desempenho no maior uso possível.
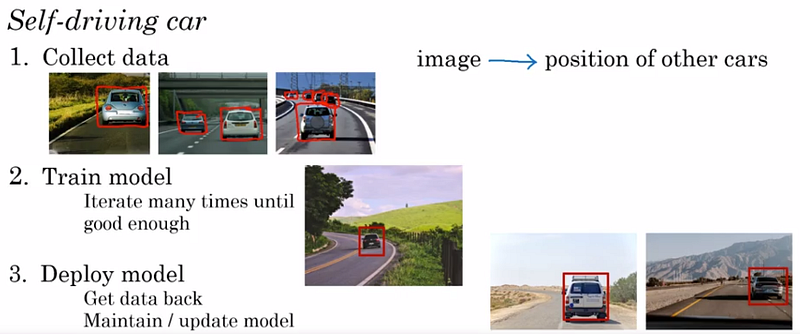
Agora que você conhece as 3 etapas para criar um modelo de ML, como você o aplicaria em carros autônomos?
Fluxo de trabalho de um projeto de Ciência de Dados
Como para o fluxo de trabalho de um projeto de IA, o fluxo de trabalho de um projeto de Ciência de Dados (Data Science) contém 3 etapas: a primeira é a coleta de dados ( collect data), a segunda a analise desses dados ( analyze data) com tantas interações quantas necessárias para extrair as características importantes (insights), e a terceira para emitir hipóteses e propor ações ( suggest hypotheses/actions) cuja implementação irá gerar novos dados para analisar . Este ciclo é essencial para melhorar o desempenho do produto/serviço analisado.
Dois exemplos são usados por Andrew Ng para ilustrar esse fluxo de trabalho: a otimização do ato de comprar em um site e a redução de canecas com defeitos em seu processo de fabricação.


Trabalhando com uma equipe de IA
Antes de postar uma oferta de emprego para recrutar um especialista em IA, sugira que seus engenheiros de TI façam um curso de ML/DL. De fato, muitos MOOCs estão disponíveis na Internet e são um ótimo lugar para começar a aprender sobre a IA.
Uma vez que você tenha uma equipe de IA, a equipe de domínio deve definir a taxa de desempenho a ser obtida pelo modelo de IA e fornecer um dataset de teste que avalie efetivamente o nível atingido pelo modelo após o treinamento.
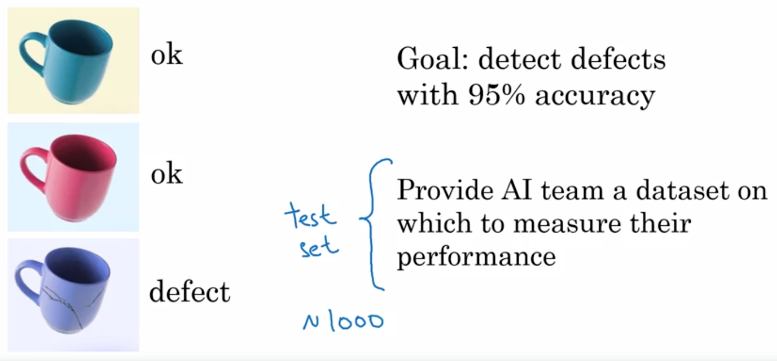
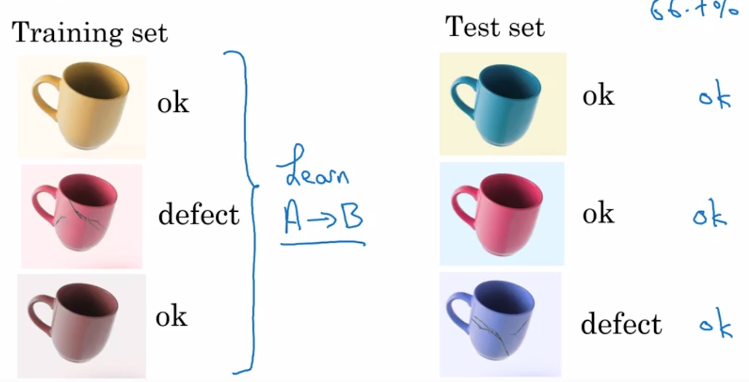
Tenha cuidado, não é realista pedir à equipe de IA para obter uma taxa de desempenho de 100%, porque dependendo da dificuldade do projeto, até mesmo o melhor modelo de IA pode não ser suficiente. Além disso, o dataset de treinamento nunca pode abranger todos os casos possíveis e alguns dos dados podem ser falsos ou ambíguos (esses problemas podem ser corrigidos com mais dados e/ou trabalhos para corrigir dados existentes).

As ferramentas da equipe de IA
A IA evolui em grande parte no mundo do código aberto, o que permite não apenas ter acesso às estruturas de ML/DL de alta qualidade (para a lista de Andrew Ng, devemos adicionar a biblioteca fastai), mas também aos papeis de pesquisa acadêmica em ML/DL (website Arxiv) e ao código fonte de muitos modelos (site GitHub).

A equipe de IA também deve ter capacidade computacional significativa (GPU) para poder treinar seus modelos de ML/DL. As GPUs podem ser locais (On-premise ou On-prem deployment), na nuvem (cloud) no Amazon AWS, Microsoft Azure ou Google GCP por exemplos ou na implantação do Edge (caso de uso: em carros autônomos ou em dispositivos móveis de reconhecimento da voz, a fim de ter um tempo de resposta mais rápido, ter menos dados para transferir e aumentar a privacidade).

Sem Big Data, nenhum projeto de IA? Errado!
A quantidade de dados necessária para treinar um modelo de IA depende da natureza do projeto. Além disso, com as técnicas de Data Augmentation, Transfer Learning e Regularization, agora é possível começar a treinar um modelo ML/DL com poucos dados (1000, 100 ou até 10). Posteriormente, o uso do modelo em produção aumentará o número de dados de treinamento e, assim, melhorará o desempenho do modelo.

Sobre o autor: Pierre Guillou é consultor em inteligência artificial no Brasil e na França. Por favor, entre em contato com ele através do seu Perfil do Linkedin.