Deploy Your LLM Chatbot With Retrieval Augmented Generation (RAG), llama2–70B (MosaicML inferences) and Vector Search
Dear LLMs Enthusiasts,
The field of LLMs/GenAI is continuously growing in excitement and potential.
Gen AI/LLMs: A Distributed Challenge!
It is truly remarkable to contemplate our current possession of the necessary data, cloud infrastructure, and ML models to create extraordinary GenAI solutions.
My Journey with OpenAI at Microsoft
I began using OpenAI with Microsoft customers in 2022, and it was remarkable to witness how swiftly we could disrupt businesses using LLMs.
Here’s a talk I delivered on Azure Open AI during my time at Microsoft.
I must admit that working with Gen AI gave me a sense of rebellion. Engaging in GenAI projects feels like deconstructing and reconstructing everything with a completely new approach.
Teaching at IE University
Now, as I teach at IE University, I strongly encourage my students to utilize LLMs like ChatGPT/OpenAI or any other they find useful. In my opinion, using LLMs can expand your capabilities. For those who love learning, it’s akin to having your own personal teacher.
I often feel like I’m in the movie Interstellar, with an AI buddy to assist me. If you’re interested in this topic, please watch my talk here.
Exploring Gen AI at Databricks
In June 2023, I joined Databricks, and over the past months, I’ve been collaborating with customers and partners to explore the applications of Gen AI.
I’ve had the privilege of delivering numerous talks at events about Gen AI. It’s incredibly exciting to join forces with partners and customers to co-create the future using new technologies.
One demo that I find particularly useful is called “Deploying Your LLM Chatbot With Retrieval Augmented Generation (RAG), llama2–70B (MosaicML inferences), and Vector Search.”
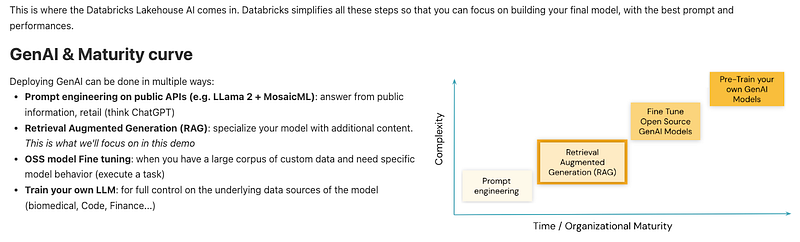
Last year, most customers were experimenting with LLMs and defining use cases. As shown in the GenAI Maturity curve below, they were in the “Prompt Engineering” phase. This year, many customers have progressed to Phase 2, where they are exploring RAG (Retrieval Augmented Generation).
A few more mature customers have reached Phase 3 and 4.
GenAI Maturity curve
What you’ll learn in this demo
LLMs are disrupting the way we interact with information, from internal knowledge bases to external, customer-facing documentation or support.
In this tutorial, we will cover how Databricks is uniquely positioned to help you build your own chatbot using Retrieval Augmented Generation (RAG) and deploy a real-time Q&A bot using Databricks serverless capabilities. We will leverage llama2–70B-Chat to answer our questions, using MosaicML Inference API.
RAG is a powerful technique where we enrich the LLM prompt with additional context specific to your domain so that the model can provide better answers.
This technique provides excellent results using public models without having to deploy and fine-tune your own LLMs.
You will learn how to:
- Prepare clean documents to build your internal knowledge base and specialize your chatbot
- Leverage Databricks Vector Search with AI Gateway to create and store document embeddings
- Search similar documents from our knowledge database with Vector Search
- Deploy a real-time model using RAG and providing augmented context in the prompt
- Leverage the llama2–70B-Chat model through an AI Gateway using MosaicML endpoint (fully managed)
Try now this demo:
Demo link:
Scaling your business with a GenAI-Powered Assistant
LLMs are disrupting the way we interact with information, from internal knowledge bases to external, customer-facing documentation or support.
While ChatGPT democratized the use of LLM-based chatbot for retail, companies need to deploy personalized models that answer their needs:
- Privacy requirements on sensitive information
- Preventing hallucination
- Specialized content, not available on the Internet
- Specific behavior for customer tasks
- Control over speed and cost
- Deploy models on private infrastructure for security reasons
Introducing Databricks Lakehouse AI
To solve these challenges, custom knowledge bases and models need to be deployed. However, doing so at scale isn’t simple and requires:
- Ingesting and transforming massive amounts of data
- Ensuring privacy and security across your data pipeline
- Deploying systems such as Vector Search Index
- Having access to GPUs and deploying efficient models
- Training and deploying custom models
This is where the Databricks Lakehouse AI comes in. Databricks simplifies all these steps so that you can focus on building your final model, with the best prompt and performances.
What is Retrieval Augmented Generation (RAG) for LLMs?
RAG is a powerful and efficient GenAI technique that allows you to improve model performance by leveraging your own data (e.g., documentation specific to your business), without the need to fine-tune the model.
This is done by providing your custom information as context to the LLM. This reduces hallucination and allows the LLM to produce results that provide company-specific data, without making any changes to the original LLM.
RAG has shown success in chatbots and Q&A systems that need to maintain up-to-date information or access domain-specific knowledge.
RAG and Vector Search
To be able to provide additional context to our LLM, we need to search for documents/articles where the answer to our user question might be. To do so, a common solution is to deploy a vector database. This involves the creation of document embeddings (vectors of fixed size, computed by a model). The vectors will then be used to perform realtime similarity search during inference.
Implementing RAG with Databricks Lakehouse AI and a MosaicML endpoint
In this demo, we will show you how to build and deploy your custom chatbot, answering questions on any custom or private information.
As an example, we will specialize this chatbot to answer questions over Databricks, feeding databricks.com documentation articles to the model for accurate answers.
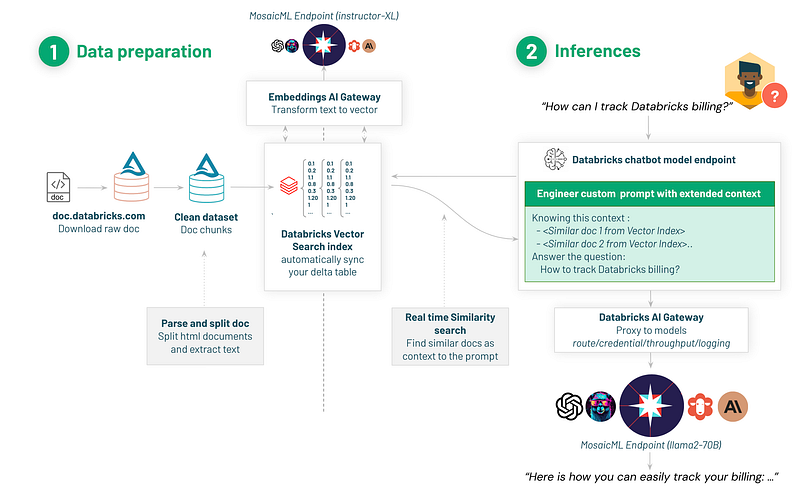
Here is the flow we will implement:
- Download databricks.com documentation articles
- Prepare the articles for our model (split into chunks)
- Create a Vector Search Index using an Embedding endpoint
- Deploy an AI gateway as a proxy to MosaicML
- Build and deploy our RAG chatbot